java编程中处处离不开对象,是否了解对象在内存中结构?是否知道如何计算对象在内存中具体大小呢?本篇文章将想你介绍对象在内存中布局以及如何计算对象大小。
内存结构
在HotSpot虚拟机中,对象在内存中存储的布局可以分为3块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。如下图所示:

普通对象结构
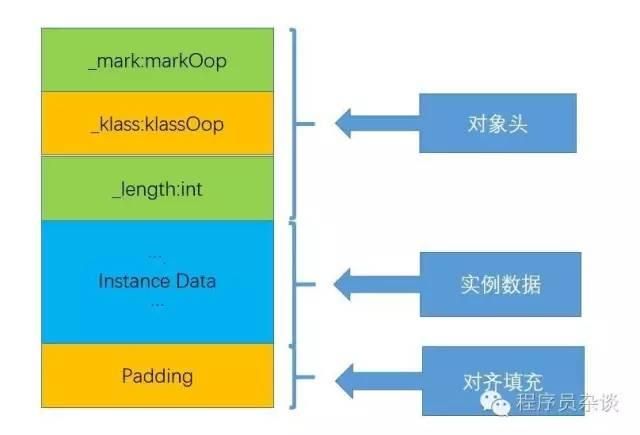
java数组结构
对象头(Header)
makrword: 用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,这部分数据的长度在32位和64位的虚拟机(未开启压缩指针)中分别为4个字节和8个字节,官方称它为“MarkWord”,该部分将在下一节关于锁在对象中展现会详细介绍。
klass指针:对象头的另外一部分是klass,类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例.
length : 如果对象是java数组,那在对象头中还必须有一块用于记录数组长度的数据。所以会用4个字节的int来记录数组的长度。
实例数据区
实例数据部分是对象真正存储的有效信息,也是在程序代码中所定义的各种类型的字段内容。无论是从父类继承下来的,还是在子类中定义的,都需要记录起来。
对齐填充
由于HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,这就要求当不为8字节整数倍时,就需要填充数据对齐填充。如此规定的原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问,详细原因介绍可以去查找相关资料。
大小计算
pubilc long id;
来看一个简单的类,如下:
public class Hello {
public Object o;
}
Hello hello=new Hello();
对于对象的大小分为以下两种:
1.自身的大小(Shadow heap size)
2.所引用的对象的大小(Retained heap size)。
Hello 实例创建出来之后,在内存中所占的大小就是 Hello 自身大小(Shadow heap size)。包括类的头部大小以及一个int的大小和一个引用的大小。
hello.o=new Object();给其引用对象赋值
hello中object 成员变量是一个对象引用,这个被引用的对象也占一定大小。hello 实例所维护的引用的对象所占的大小,称为 hello 实例的 Retained heap size。
计算对象大小可用对象大小的计算可用java.lang.instrument.Instrumentation 或者 dump 内存之后用 memory analyzer 分析。 使用Instrumentation必须将代码打成 jar 包。若不想这么麻烦,可以直接使用lucene core里面的RamUsageEstimator来计算大小,shallowSizeOf 计算自身引用的大小,humanSizeOf所引用的对象大小添加以下依赖即可:
不同位下的JVM对象头大小是不一样的
-
-
在32位JVM下,存放Class指针的空间大小是4字节,MarkWord是4字节,对象头为8字节。
-
在64位JVM下,存放Class指针的空间大小是8字节,MarkWord是8字节,对象头为16字节。
-
64位JVM开启指针压缩的情况下,存放Class指针的空间大小是4字节,MarkWord是8字节,对象头为12字节。
-
基本数据类型的大小如下:

对于引用的大小如上对对象头中指针一样,不同位数JVM会有区别。在 32 位的 JVM 上,一个对象引用占用 4 个字节;在 64 位上,占用 8 个字节,开启指针压缩情况下占用4个字节。
关于指针压缩可通过 -XX:+UseCompressedOops 选项,开启指针压缩。从 Java 1.6.0_23 起,这个选项默认是开的。可通过 jinfo -flag UseCompressedOops
~]#jinfo -flag UseCompressedOops XXXXX
-XX:+UseCompressedOops
以下对于对象大小的讨论都是在64位JVM上进行的,我们来看一个关于计算大小一个经典问题。有如下对象:
public class Fuck {
byte a;
int c;
boolean d;
long e;
Object f;
}
在计算大小前,先引出计算大小的第一个规则。
规则1:除了对象整体需要按8字节对齐外,每个成员变量都尽量使本身的大小在内存中尽量对齐。比如 int 按 4 位对齐,long 按 8 位对齐。
根据以上得出其大小过程如下:
Header------12
a-----------13
padding-----16
c-----------20
d-----------21
padding-----24
e-----------32
f(引用)-----36
padding-----40
手工计算的大小为40,用工具计算结果如
Fuck fuck=new Fuck();
System.out.println(RamUsageEstimator.shallowSizeOf(fuck));
fuck的大小:32
为何会有这么的大的差距呢?为了内存紧凑,提高内存使用率,实例成员在内存
中的排列和声明的顺序可能不一致。这就是要引入的第二个规则:
规则2:类属性按照如下优先级进行排列:长整型和双精度类型;整型和浮点型;
字符和短整型;字节类型和布尔类型,最后是引用类型。这些属性都按照各自的单
位对齐。
按照以上规则在进行计算
Header------12
e-----------20
c-----------24
a-----------25
d-----------26
padding-----28
f(引用)-----32
这样其大小就和工具计算的结果,而且明显内存利用率高,可能一些读者又会有疑惑,为何长整型加了之后变成20不对齐呢,为了提高内存利用率,这里有个附加规则若首个成员是长整型或双精度类型,则使用较小的字段,来填充这4个字节的gap。
继承其他类的子类内存计算也有规则,不同类继承关系中的成员不能混合排列。规则三如下:
规则3:优先按照规则一和二处理父类中的成员,接着才是子类的成员。
classAFuck{bytea;}
classBFuckextends AFuck{byteb;}
内存大小计算过程:
HEADER--------12
a-------------13
padding-------16
b-------------17
padding-------24
对于上述例子,发现在父类结束计算后进行了一次对齐,这是子类计算的有一个规则。如果父类中的成员的大小无法满足4个字节这个基本单位,那么下一条规则就会起作用:
规则4:当父类中最后一个成员和子类第一个成员的间隔如果不够4个字节的话,就必须扩展到4个字节的基本单位。
由于父类成员计算后没有按照4字节对齐,所以加3进行对齐。继续看如下例子,
class AFuck {
chara;
int b;
}
class BFuck extends AFuck {
long c;
short d;
byte e;
}
header ---12
b---------16
a---------18
pading----20
d---------22
e---------23
pading----24
c---------32
在进行子类计算的时候,破坏了规则2,没有先计算c的长度。这就要引入第五条规则。
规则5:如果子类第一个成员是一个双精度或者长整型,并且父类并没有用完8个字节,JVM会破坏规则2,按照整形(int),短整型(short),字节型(byte),引用类型(reference)的顺序,向未填满的空间填充。
数组也是对象,故有对象的头部,另外数组还有一个记录数组长度的 int 类型,随后是每一个数组的元素:基本数据类型或者引用。8 字节对齐。
int[] groups=new int[4];
大小为
header -----12
len---------16
[0]---------20
[1]---------24
[2]---------28
[3]---------32
Integer[] groups=new Integer[4]大小也是32,但是实例数据区存就是对Integer对象的引用了,每个引用大小也是4,所以大小是一样的。
关于java对象大小介绍完毕,知道内存是如何组织的有助于理解类实例占用的内存数。
有兴趣的可以尝试解答如下问题。
1.int 和Integer大小一样么,其各占几个字节?
2.byte[] a=new byte[5]和Byte[] b=new Byte[5]大小相等么?
3.long[][] al=new long[2][10]与long[][] bl=new long[10][2]大小相等么?
4.new String()和new String("abc")的Retained heap size各位多少?
5.
public AClass{
pubilc static int a=0;
public final long b;
public int c;
}
的大小为多少?