【1】图的基本概念
(1)图是由顶点集合以及顶点间的关系集合组成的一种数据结构。
Graph = (V,E) V是顶点的又穷非空集合;E是顶点之间关系的有穷集合,也叫边集合。
(2)有向图:顶点对
(3)无向边:若顶点Vi到Vj之间的边没有方向,则称这条边为无向边,用无序偶对(Vi,Vj)来表示。
如果图中任意两个顶点时间的边都是无向边,则称该图为无向图:
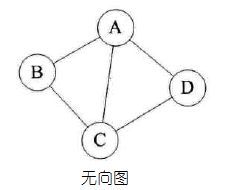
由于是无向图,所以连接顶点A与D的边,可以表示为无序对(A,D),也可以写成(D,A)
对于如上无向图来说,G=(V,{E}) 其中顶点集合V={A,B,C,D};边集合E={(A,B),(B,C),(C,D),(D,A),(A,C)}
有向边:若从顶点Vi到Vj的边有方向,则称这条边为有向边,也称为弧。
用有序偶
如果图中任意两个顶点之间的边都是有向边,则称该图为有向图:
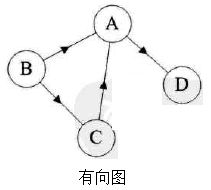
连接顶点A到D的有向边就是弧,A是弧尾,D是弧头,
对于如上有向图来说,G=(V,{E})其中顶点集合V={A,B,C,D};弧集合E={
(4)完全无向图:若有n个顶点的无向图有n(n-1)/2 条边, 则此图为完全无向图。
完全有向图:有n个顶点的有向图有n(n-1)条边, 则此图为完全有向图。
(5)树中根节点到任意节点的路径是唯一的,但是图中顶点与顶点之间的路径却不是唯一的。
路径的长度是路径上的边或弧的数目。
(6)如果对于图中任意两个顶点都是连通的,则成G是连通图。
(7)图按照边或弧的多少分稀疏图和稠密图。 如果任意两个顶点之间都存在边叫完全图,有向的叫有向图。
若无重复的边或顶点到自身的边则叫简单图。
(8)图中顶点之间有邻接点。无向图顶点的边数叫做度。有向图顶点分为入度和出度。
(9)图上的边和弧上带权则称为网。
(10)有向的连通图称为强连通图。
【2】图的存储结构
关于图的存储结构,可以分为以下五种:
(1) 邻接矩阵
图的邻接矩阵存储方式是用两个数组来表示图:
一个一维数组存储图中顶点信息;
一个二维数组(称为邻接矩阵)存储图中边或弧的信息

(2) 邻接表
邻接矩阵是一种不错的图存储结构。 但是:对于边树相对顶点较少的图,这种结构是存在存储空间的极大浪费的。
因此我们考虑先进一步,使用邻接表存储,关于邻接表的处理办法是这样:

下图是一个无向图的邻接表结构:
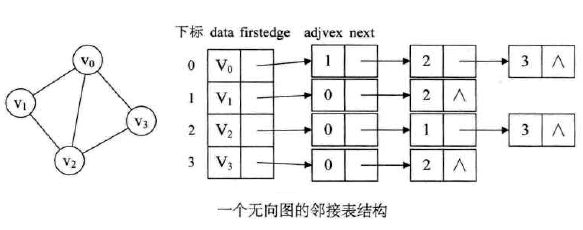
对于有向图而言,为了更便于确定顶点的入度(或以顶点为弧头的弧)。
我们可以建立一个有向图的逆邻接表。如下图所示:
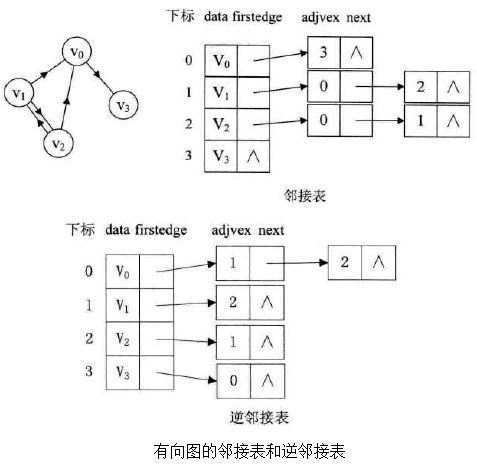
而对于有权值的网图,可以在边表节点定义中再增加一个weight的数据域,存储权值信息即可。 如下图所示:

那么,有了这些结构的图,下面定义代码如下:

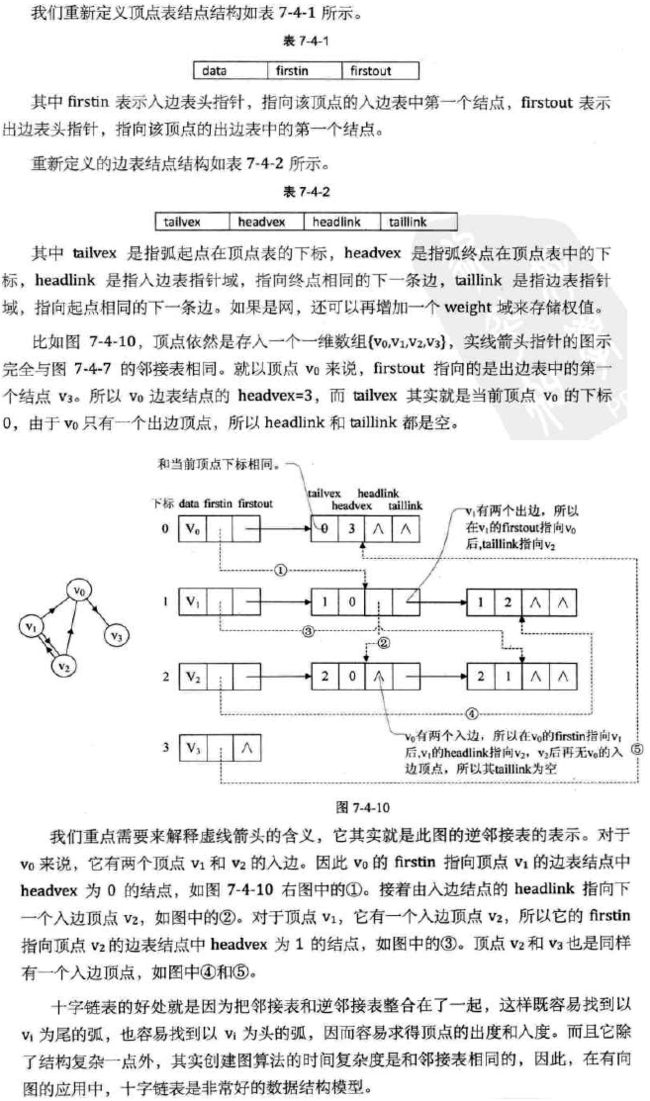
(3) 十字链表
对于有向图而言,邻接表也是有缺陷的。
试想想哈,关心了出度问题,想了解入度问题就必须把整个图遍历才能知道。
反之,逆邻接表解决了入度问题却不了解出度的情况。
那是否可以将邻接表和逆邻接表结合起来呢?答案是肯定的。
这就是所谓的存储结构:十字链表。其详解如下图:
(4) 邻接多重表
有向图的优化存储结构为十字链表。
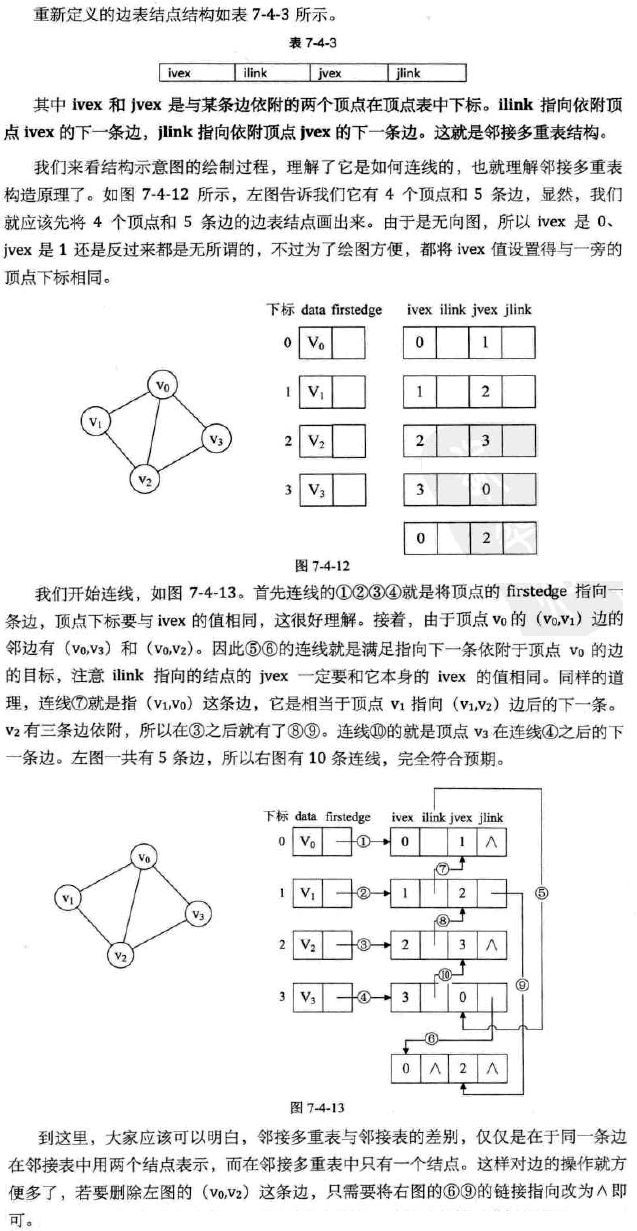
对于无向图的邻接表,有没有问题呢?如果我们要删除无向图中的某一条边时?
那也就意味着必须找到这条边的两个边节点并进行操作。其实还是比较麻烦的。比如下图:

欲删除上图中的(V0,V2)这条边,需要对邻接表结构中右边表的阴影两个节点进行删除。
仿照十字链表的方式,对边表节点的结构进行改造如下:
(5)边集数组
边集数组侧重于对边依次进行处理的操作,而不适合对顶点相关的操作。
关于边集数组详解如下:

【3】图的遍历
图的遍历图和树的遍历类似,那就是从图中某一顶点出发访遍图中其余顶点,且使每一个顶点仅被访问一次,这个过程就叫做图的遍历。
对于图的遍历来说,如何避免因回路陷入死循环,就需要科学地设计遍历方案,通过有两种遍历次序方案:深度优先遍历和广度优先遍历。
(1) 深度优先遍历
深度优先遍历(Depth_First_Search),也称为深度优先搜索,简称DFS。
为了更好的理解深度优先遍历。请看下面的图解:
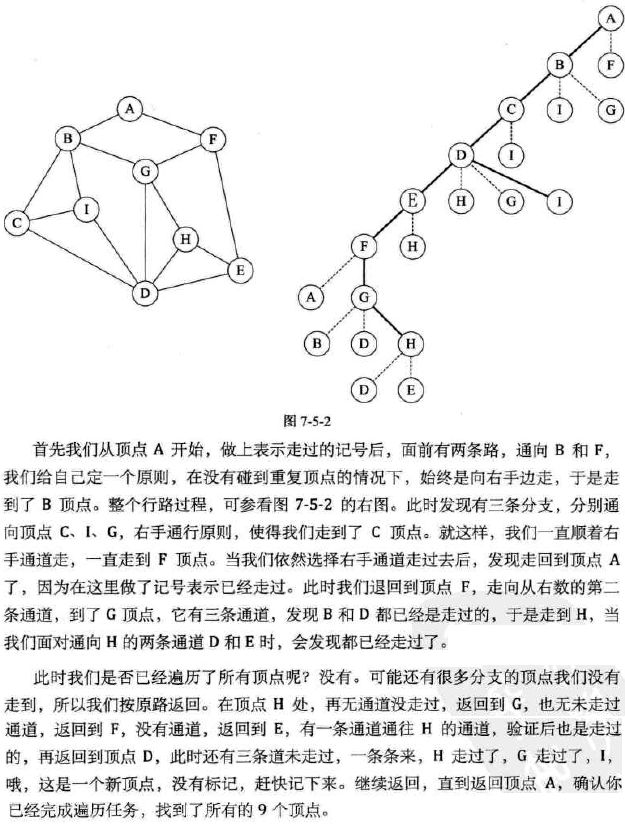
其实根据遍历过程转换为右图后,可以看到其实相当于一棵树的前序遍历。
(2)广度优先遍历
广度优先遍历(Breadth_First_Search),又称为广度优先搜索,简称BFS。
深度遍历类似树的前序遍历,广度优先遍历类似于树的层序遍历。

【5】图的邻接矩阵和邻接表实现
Good Good Study, Day Day Up.
顺序 选择 循环 总结