Facial Recognition Using Motion Vectors: H.264(论文翻译)
最近在学习视频编解码相关的目标跟踪知识,看到了这一篇论文,并对其进行全部翻译,深有所感,希望能对大家有用。
I.Introduction——引言
全景变焦(PTZ)摄像机的自主控制是一个有趣的研究领域,具有许多应用,例如录制演讲,研讨会,体育赛事现场直播,视频监控等。该项目在这方面的工作是初步的。这项工作针对的是录制现场演讲的更为简单的场景,即对象受限制的运动.PTZcamera可以实时录制对象并由h.264编码器实时生成编码的比特流。传统的面部识别算法可用于跟踪对象,但在某些情况下会失败,例如对象背对着摄像机或背景中的海报。此项目的目的是通过简单地使用位中可用的运动矢量来帮助传统的面部识别算法提高其准确性。我们提出了一种算法来跟踪每帧中运动的多个对象。假设记录演讲的场景,该主题就是演讲者的脸。从某种意义上说,该算法是通用的,可以很容易地扩展到先前建议的其他应用程序。
在第二部分中,我们概述了成功的视频编码标准之一MPEG-2。在第三节中,我们概述了H.264。在本节中,我们主要介绍H.264建议的基于MPEG-2的改进,以及它们如何有助于提高压缩效率。在第四节中,我们描述了使用运动矢量进行面部跟踪的算法,并使用一些样本帧演示了其工作原理。在第五节中,我们通过建议针对本技术的其他应用程序来总结。
II.Overview of MPEG-2——MPEG-2的概述
视频本质上是以恒定帧速率捕获的一系列图片。视频压缩是一种利用空间和时间冗余来最小化存储视频所需位数的方法。压缩可以是有损的或无损的,其中在实践中更优选前者。已经提出了几种视频压缩标准,包括MPEG-2,H.264,HEVC等。
让我们首先了解视频的每个组成部分。视频由一系列图片组成。固定数量的图片被分组在一起,称为图片组(GOP)。图片中的每个16x16像素段都构成MPEG的基本编码单元。该单元称为“宏块”。连续的一组宏块称为“切片”。切片对于解码器处理错误很有用。如果出现错误,解码器会跳过当前片段并跳至下一个片段以继续进行解码。"块''由8X8像素组成,是最小的编码单位。它可以是亮度(Y)或色度(Cr,Cb)块。根据YUV格式的类型,每个宏块都有不同数量的块。例如4:2:0每个宏块有4个亮度块和2个色度块。
MPEG-2标准定义了帧内(I),预测(P)和双向(B)三种类型的图像。I图片仅使用该图片中的信息进行编码。通过将最近的(正向)I或P图片作为参考图片对P图片进行编码.P图片使用运动补偿,因此可提供更高的压缩效率。B图片同时使用前向和后向预测,因此具有最高的压缩效率。每个GOP都包含准确的I图片。B和P图片的数量是一种设计选择,这会带来多种后果。

图1 视频序列组成的层次结构
例如,M = 3,N = 12给出了GOP结构IBBPBBPBBPBB。M是两个锚图像(I或P)之间的距离,N是两个I图像之间的距离。具有更多的B图片会增加对视频进行编码的时间,同时还会提高压缩效率。N较大会降低随机访问视频的能力(I图片提供随机访问点)。需要注意的重要一点是,帧的显示顺序与视频中存储的顺序不同。
帧内编码不涉及运动补偿。它依靠空间冗余来实现良好的压缩效率。基本压缩范例由以下框图描述。MPEG-2在每个8X8块上使用离散余弦变换(DCT)。根据预定义的量化矩阵对所得的系数进行量化,该预定义的量化矩阵为每个频率系数设置量化参数。较高的频率比较低的频率更粗糙,因为人类对高频的敏感度较低。可变长度码用于压缩这些量化的DCT系数。游程编码,然后是霍夫曼编码是最常见的选择。进行之字形扫描以生成零的长时间运行,因此减少了表示每个DCT系数的位。

图2 基本变换编码范例
使用参考图片(I或P)对P图片进行编码。大部分压缩归因于时间冗余。根据参考图片预测P图片中的每个16x16宏块,并由运动矢量![]() 表示。这意味着当前宏块的16x16块在失真方面是最接近的匹配,这是主题平方误差(MSE)计算。穷举搜索受search_width限制,search_height用于计算运动矢量。H.264中提供了更高级的搜索算法。原始宏块与预测宏块之间的差异是呼叫预测误差,然后使用DCT量化熵编码进行编码,类似于帧内编码。
表示。这意味着当前宏块的16x16块在失真方面是最接近的匹配,这是主题平方误差(MSE)计算。穷举搜索受search_width限制,search_height用于计算运动矢量。H.264中提供了更高级的搜索算法。原始宏块与预测宏块之间的差异是呼叫预测误差,然后使用DCT量化熵编码进行编码,类似于帧内编码。
双向预测会略有不同,因为每个宏块都可以使用前向预测或后向预测,或同时使用两者。当两者都使用时,它取过去和将来预测的宏块的平均值。诸如速率控制[7]和自适应量化之类的高级概念需要深入研究,这超出了该项目的目标。
III.Overview of H.264
在本节中,我们将研究H.264在MPEG-2上的主要改进。从广义上讲,在变换编码,熵编码,运动补偿和配置文件方面进行了改进。
选择8X8以上的DCT作为变换工具,以进行帧内编码和运动预测误差编码。尽管DCT具有非常接近KKT的优势,并且具有快速实现算法(FFT)[5],但它具有一些不良的特性。DCT将整数值图像转换为需要浮点运算的实值系数。因此,在H.264中引入了一个新的整数变换,它可以在4x4的块上运行[3] [4]。这不需要浮点运算,并且可以在解码器处进行精确的重构。
H.264帧内编码的另一个改进是它具有9个方向用于空间预测[4]。H.264使用两种熵编码模式:上下文自适应可变长度编码(CAVLC)和上下文自适应二进制算术编码(CABAC)。CAVLC与MPEG-2非常相似,只是在可用的4个VLC表中,根据相邻块的统计信息,选择一个。另一方面,CABAC实现了显着的压缩效率,并且具有很高的计算复杂度[3]。自适应算术代码随输入的变化而变化。还可以将非整数位数分配给符号,从而自适应地最小化位速率。

图3 H.264中可用的九种空间预测模式
运动补偿方面的改进可以概括为以下几个方面:
- 宏块分区类型数量增加
允许选择不同的宏块分区大小可提高压缩效率。对于单调的背景,没有分区的16x16宏块,对于更详细的前景4x4分区,对于相同数量的位,可以将失真降至最低。H.264提供大小为8x8、16x8、8x16和16x16luma样本的宏块分区,以及其他大小为8x8、8x4、4x8或4×4 luma样本的子宏块分区。
- 多画面预测
H.264最多允许将15张图片用作预测的参考图片[3]。这在类似于场景切换的情况下特别有用。
- 运动矢量的四分之一像素分辨率
四分之一像素分辨率提供了比MPEG-2 [4]中使用的半像素分辨率更好的PSNR。四分之一像素内插运动补偿分两个阶段实现:1)由6抽头滤波器生成的半像素预测,然后,2)与相邻像素进行线性平均。
- 去块滤波
基于块的帧内编码和运动估计通常会导致“块状伪像” [4]。因此H.264定义了自适应环路内去块滤波。有关详细研究,请参阅[6]。
MPEG-2定义了6个配置文件(简单,主要,4:2:2配置文件,SNR,空间和高)和4个级别(高,高1440,主要和低)。配置文件给出了所使用的编码工具的类型(B图片,熵编码类型)。级别给出了编码参数的范围(比特率,分辨率)。H.264定义了三个配置文件,Baseline,Main和Extended,可以根据不同的应用进行选择。
运动估计极大地提高了任何视频压缩标准的编码复杂度。以下是可用的各种搜索算法的子集[2]:
- Full search——全搜索
对![]() 搜索范围内的所有宏块进行搜索,使预测误差最小化。误差的标准可以是绝对差之和(SAD)或平方差之和(SSD)。如果我们有N个参考图片和M个块类型,则总共有搜索候选
搜索范围内的所有宏块进行搜索,使预测误差最小化。误差的标准可以是绝对差之和(SAD)或平方差之和(SSD)。如果我们有N个参考图片和M个块类型,则总共有搜索候选![]() 。该算法计算量大,研究了以下几种搜索算法以降低其复杂度。
。该算法计算量大,研究了以下几种搜索算法以降低其复杂度。
- Fast Full Search (FFS) (default)——快速完全搜索(FFS)(默认)
根据连续消除算法(SEA)得出SAD的下限如下:
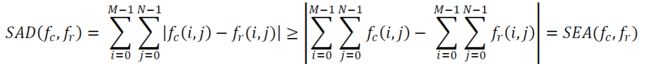
SEA的计算比SAD容易得多,并且可并行化。如果SEA大于当前的最小值,我们可以跳过该块并继续进行下一个。也可以使用每个4x4块的SEA来计算较大块的SEA。因此,从本质上讲,我们拥有一种具有较低复杂度的FFS算法,而不会降低性能。
- Simplified Hexagon Search——简化的六边形搜索
与菱形搜索类似,它具有半径2的大六边形图案和半径1的小六边形图案。计算所有点的失真。如果中心点失真最小,则对较小的六边形图案重复此过程。否则,将大六角形图案的中心移到失真最小的点,然后继续。
- Enhanced Predictive Zonal Search (EPZS)——增强型预测性区域搜索(EPZS)
与许多预测算法类似,EPZS具有三个主要步骤[1]。
-
预测器选择:这是任何预测算法中最重要的步骤。其准确性直接影响该算法的性能和计算复杂度。最常用的一组预测变量是“中位数预测变量”,三个空间相邻的MV(左,上和右上)以及参考帧中并置的MV。不必像提前终止步骤中所述那样考虑每个预测变量。
-
自适应提前终止:基于三个相邻块,并置的块以及预定的
 和
和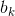 的SAD选择阈值
的SAD选择阈值 ,如下所示:
,如下所示: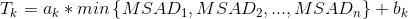 。如果所选集合中的任何预测变量的SAD小于阈值,我们可以停止搜索并将该预测变量选择为运动矢量。否则,我们将继续执行第3步,以优化我们的最佳预测指标。
。如果所选集合中的任何预测变量的SAD小于阈值,我们可以停止搜索并将该预测变量选择为运动矢量。否则,我们将继续执行第3步,以优化我们的最佳预测指标。 -
预测细化:如果不符合提前终止标准,则通过使用步骤1中定义的最佳预测器中心附近的Diamond / Hexagonal搜索进一步 完善运动估计。
IV.Algorithm for Facial Recognition——人脸识别算法
我们针对的主要应用是PTZcamera录制实时说话的人,并实时跟踪其面部。因此,这里固有的假设是,任何帧中的大部分运动都是由面部贡献的,而前景或背景中没有其他运动。
我们使用编码比特流中可用的宏块每个分区的运动矢量信息来识别运动面部。这样做的简单方法是识别特定帧中的所有非零运动矢量。如果我们的假设是正确的,那就是只有脸部在任何帧中移动,那么我们已经成功地识别出它。但是在视频序列中通常会观察到两个偏差。
- 首先,帧中可能存在杂散运动,这意味着尽管帧的该部分没有明显的运动,但是某些宏块可能具有非零运动矢量。
- 其次,框架的其他部分可能具有比面部更多的运动,例如手,腿等。
因此,我们提出了一种算法来处理这两种冲突并以合理的准确度识别被摄对象的面部,算法如下:
I. 我们创建一个哈希表,以便其范数在指定范围内的4x4子宏块分区将属于同一存储桶。这表示帧中运动的直方图。
II. 接下来,我们确定4x4子宏块分区具有最高![]() 和第二高
和第二高![]() 数量的存储桶。如果
数量的存储桶。如果![]() 并且第二高的存储桶的范数小于最高的存储桶的范数,则选择第二高的存储桶的较低范数值作为阈值。否则,我们选择最高存储桶的较低标准值。
并且第二高的存储桶的范数小于最高的存储桶的范数,则选择第二高的存储桶的较低范数值作为阈值。否则,我们选择最高存储桶的较低标准值。
III. 从每个4x4块的运动矢量中,我们确定16x16宏块是如何划分的。这是通过为宏块定义一个森林来完成的,其中每个4x4块都是一个节点,并且如果相邻(空间)节点具有相同的运动矢量,则它们之间存在一条边。通过在该森林的每个断开连接的图上运行广度优先搜索(BFS)算法,我们得到每个宏块分区的左上角像素和右下角像素。

图4 在每个4x4块上使用BFS识别宏块分区
IV. 我们将两个宏块分区之间的连接定义为至少有一个像素重叠。然后,我们对超过上一步计算的阈值的所有分区运行强连接组件算法,这将导致多个不相交的分区组,其中每个组具有空间连接的分区(至少一个像素)。此类最大的组代表框架中具有运动的主要对象,我们围绕该对象绘制一个框。
在编码的比特流中,我们具有每个帧的每个宏块的每个4x4块的运动矢量。如第三节所述,每个宏块可以划分为几种类型。挑战之一是确定分区的类型,这在我们算法的步骤III中进行了处理。步骤I,II计算运动矢量范数的动态阈值。步骤III使用BFS识别大于阈值的宏块分区。步骤IV标识连接的运动大于步骤II中阈值的最大分区组。
为了了解该算法如何最小化上述两个偏差,我们首先分析步骤II。实施静态阈值是不可行的,因为运动矢量的范数的大小随帧而变化。因此选择动态阈值,以使同一存储桶中的大量分区必须属于我们感兴趣的对象(面部)。但是由于我们使用的是固定的哈希表,因此可能会在两个不同的存储桶之间划分分区。因此检查15%,这可以最大程度地减少框架中的杂散运动。

图5 在样本帧中的所有宏块分区,GREATERTHAN动态阈值。
我们如何处理在同一帧中移动的多个对象?我们迭代算法仅在面部是突出对象(占据帧的重要部分)时才起作用。如果两个宏块分区之间至少有一个公共像素,我们定义它们之间存在边/连接。这将生成分区森林。通过在该目录林上运行最强连接组件算法版本,我们可以获得断开连接的分区集。最大的此类集合代表运动中大于动态阈值的帧中的“突出对象”。

图6 运行SCC后,同一样本帧上的每个分区集合都用红色边框标记

图7 在最大的一组分区周围绘制大方框的结果
V.Future Work——未来的工作
在此项目中,我们概述了MPEG-2和H.264视频压缩标准。然后,我们在对对象进行实时视频录制的情况下分析了面部识别的特定问题。我们提出了一种算法,该算法考虑了一般视频序列的非理想性,这些序列在帧中具有杂散运动和多个运动。该算法可以很容易地扩展到跟踪多个对象运动的更复杂的情况。
如前所述,该算法主要用于补充传统面部识别算法的性能。需要做进一步的工作来创建这样的混合方案。我们算法的另一个有趣的应用领域是自主直播体育报道。这是一个特别具有挑战性的任务,因为每个帧中都有很多运动,并且很难将目标对象的运动与所有其他运动分开。视频监控也是另一个有趣的应用。要注意的是,这些应用程序均不需要对所提出的算法进行任何根本性改变,而仅需对阈值和要跟踪的对象数量进行一些改进。将这项工作扩展到HEVC编码的比特流是未来研究的另一条途径。图7:在最大的分区集周围绘制大方框的结果。
VI.References——参考文献
[1] A.M.Tourapis, "Enhanced Predictive Zonal Search for Single and Multiple Frame Motion Estimation”,in proceedings of Visual Communications and Image Processing 2002 (VCIP-2002), pp. 1069-79, San Jose, CA, Jan’02.
[2] Liyin,Xie, Su Xiuqin, and Zhang Shun,"A review of motion estimation algorithms for video compression”.Computer Application and System Modeling (ICCASM), 2010 International Conference on.Vol. 2.IEEE, 2010.
[3] Michael Igarta,“Astudy of MPEG-2 and H.264 video coding”,MS. Thesis,Purdue University,U.S.A, (2004).
[4] Wiegand, Thomas, et al. "Overview of the H. 264/AVC video coding standard". Circuits and Systems for Video Technology, IEEE Transactions on13.7 (2003): 560-576.
[5] E. Feigand S. Winograd, "Fast algorithms for the discrete cosine transform", IEEE Trans. Signal Process., Vol. 40, September 1992.
[6] P. List, A. Joch, J. Lainema, G. Bjøntegaard, and M. Karczewicz, “Adaptivedeblocking filter,” IEEE Trans. Circuits Syst. Video Technol., vol.13, pp. 614–619, July 2003.
[7] Westerink, Peter H., Rajesh Rajagopalan, and Cesar A. Gonzales. "Two-pass MPEG-2 variable-bit-rate encoding."IBM Journal of Research and Development43.4 (1999): 471-488.