MV-YOLO: Motion Vector-aided Tracking by Semantic Object Detection(论文解读)
最近学习视频多目标跟踪算法,因为YOLO是最近比较火的多目标跟踪算法,正好看到这一篇论文,对自己帮助很大,在这里花了大半天时间将其翻译成中文,希望对大家有所帮助。
以下是原文PDF下载地址:https://arxiv.org/pdf/1805.00107v1.pdf
目录
MV-YOLO:通过语义对象检测进行运动矢量辅助跟踪
摘要:
1.介绍
2.提出的方法
2.1.ROI 创建
2.2.目标检测
2.3.最终box选择
2.4. 总结
3.实验结果
3.1.实验设置
3.2.结果
3.3.最后的评论
4.结论
参考文献
MV-YOLO:通过语义对象检测进行运动矢量辅助跟踪
摘要:
对象跟踪是许多视觉分析系统的基石。尽管近年来在该领域已取得了长足的进步,但在真实视频中如何稳健、高效的进行目标检测依然是一个挑战。在本论文中,我们提出了一个混合跟踪器,他利用被压缩的视频流和在解码帧上通用语义学的目标检测器得到的运动信息,去建立一个快速和高效的跟踪引擎。该方法在OTB跟踪数据集上与几个最近广为人知的跟踪器进行了比较。结果在速度和准确率上本方法都显示了较好的优势。本方法超过其他已存在的跟踪器的另一个优势在于它的简易和部署效率方面,因为它可以在系统中已经存在的资源或信息进行重复利用。
关键词:目标跟踪,语义跟踪,运动矢量,感兴趣区域
1.介绍
视觉目标跟踪是计算机视觉的基本任务之一,也是视频监控、智能家居/城市、独立生活、人机交互等许多视觉分析应用的基石。尽管近年来跟踪器的性能有了显著的进步,但是在真实世界的视频中进行鲁棒、高效和精确的跟踪仍然是一个挑战。
现有的跟踪方法可以用多种方式分类。出于本研究的目的,根据输入数据域进行划分是有用的:像素域、压缩域和混合域。
1、像素域:像素域跟踪器是文献中最丰富和研究最充分的。该组开发了许多成功的跟踪方法,如基于相关滤波器的跟踪方法(如[1])和基于已获深度特征的跟踪方法(如[2]、[3])。这类方法的优点包括它们具有高精度的潜力,以及它们与视频编解码器无关。然而,它们往往是资源密集型的,因为所有像素值都需要被构建、存储在内存中并进行处理。
2、压缩域:第二类跟踪装置是在压缩域数据中开发的,只需要部分解码的视频流信息。压缩域数据携带有价值的信息在很多领域都十分有用,例如:人脸识别、定位、动作语义以及目标分割和跟踪。参考论文6,7,8中主要观点是运动矢量和相关的编码语法元素是场景中物体运动的很好的指示器。既然这些信息已经存在于视频比特流中,那么自然的想去尝试在跟踪过程中使用它。压缩域跟踪器的优势在于高效和速度,因为它们可以避免在许多视频解码、像素值的存储和处理,而且它们一般都在很少的数据中处理。劣势的方面就是它们比较依赖于压缩视频上的编码方法,同时可能会降低准确率,因为它受限于低分辨率的运动采样网格:通常一个MV使用4X4或者更大一点的模块/单元.
3、混合域:第三种就是混合跟踪器,就是试图同时利用像素域和压缩域数据的优点。参考论文9就是这样一个例子,它通过将从高效视频编码(HEVC)位流中提取的MVs和块编码模式与解码的帧内的颜色信息相结合来执行跟踪。
本次工作中使用的跟踪方法也是一个混合算法,将解码的MVs与语义对象检测相结合,对完全解码的帧进行操作。基本思想是,已经存在于压缩视频比特流中的MVs足够好以指示目标对象的近似位置。语义对象检测器然后通过在解码帧上提供像素精度包围盒来细化对象的位置。在另两个最近的工作中,并行跟踪和验证(PTAV)[10] 和ROLO [11] 也提倡两阶段跟踪(近似求精)的思想。这两种方法都是像素域跟踪器,而我们的是目前所知的第一个混合式跟踪器。PTAV在第一阶段使用快速但不精确的像素域跟踪器,其次是基于VGGNET [12] 的暹罗网络,用于细化第二阶段。在ROLO中,第一阶段近似由YOLO对象检测器 [13] 给出,而第二阶段细化由长短时存储器(LSTM)网络提供。
论文的结构如下:在第二节中,针对我们的跟踪器我们描述了更多的细节。在第三节中,我们描述了实验,并讨论了结果,同时与其他文献中几个有代表性的跟踪器进行了比较。第四部分总结全文。
2.提出的方法
所提出的跟踪框架在图1中示出。我们把它称为MV-aided YOLO(MV辅助的YOLO),简称MV-YOLO。根据当前帧间编码帧的MVs和前一帧中的对象位置,构造目标对象的近似位置。构造的近似位置被称为感兴趣区域(ROI)。同时,解码的当前帧被传递到语义对象检测器(在我们的情况下是YOLO),它检测帧中的各种对象的位置。ROI然后帮助决定哪些位置对应于目标对象。详情见以下各小节。

图1: 概述所提出的跟踪方法
2.1.ROI 创建
ROI创建者使用来自HEVC比特流的MVs来构建目标帧在当前帧T中的近似位置,给定对象在前一帧t-1中的位置。程序相对简单。在帧解码期间从HEVC比特流读取帧T的MVs。与PU相关联的MV被分配给其所有像素。然后,在帧t-1中的MV是指对象的位置的每个像素被标记为ROI像素。最后,ROI被选择为包含所有ROI像素的最小轴对齐矩形。该过程在图2中示出,其中帧T中的ROI以红色显示,并且从帧T到帧t-1的多个MV以黄色示出。
虽然ROI创建背后的基本思想是相当直观的,但需要解决几个技术难题。这些包括没有MVs的PUs(如跳过和帧内编码PUs),MVs指向除t-1以外的帧和分数精度MVs。在这些挑战中,跳过PUs是最容易解决的。由于跳过模式指示对应的PU与前一帧中的对应的共定位区域几乎完全相同,所以将零MV分配给每个跳过PU。
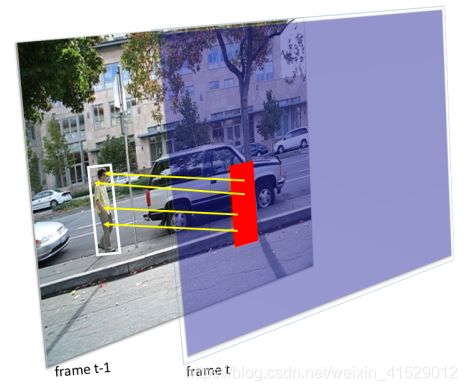
图 2:ROI创建的一个例子
由于编码器选择了帧内模式这一事实表明,基础运动过于复杂,无法通过常规运动补偿加以利用,因此,还需要为帧内编码的PUs分配有意义的运动。对于此类PU,我们在同一编码树单元(CTU)中收集所有相邻的帧间编码PUs的MVs,然后应用Polar Vector Median(PVM)[7]来为此类PUs提出合适的MV。具体地,令![]() 是来自相邻PUs的MVs的列表,所述相邻PUs根据它们相对于水平轴的角度进行分类。然后,选择来自V的
是来自相邻PUs的MVs的列表,所述相邻PUs根据它们相对于水平轴的角度进行分类。然后,选择来自V的![]() 个连续向量的子列表,以使它们的角度差之和最小。也就是说,选择的组是
个连续向量的子列表,以使它们的角度差之和最小。也就是说,选择的组是![]() ,其中k被选为
,其中k被选为
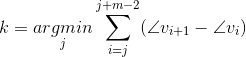 (1)
(1)
然后将PVM向量  的角度和大小设置为:
的角度和大小设置为:
![]() (2)
(2)
![]()
最后,与[7]相似,对t帧中指向t-1以外的帧的MV进行缩放(假定运动是连续的),使得它们的缩放版本指向t-1帧。小数精度MV的分量被舍入。部分精度MVs的组件四舍五入为最接近的整数
2.2.目标检测
语义对象检测是指在图像中查找对象的位置,并根据它们的类型对它们进行分类,例如人、车、狗、…任何语义对象检测器都可以在我们所提出的图1所示的框架中使用。然而,对于实验,我们选择了三个版本的流行的YOLO检测器:YOLVO3 [14] ,YOLVO2 [15] 和TiNyYOLO,这是一个更简单和更快(虽然准确率较低)版本的YOLVO2。
要跟踪的对象的初始位置在序列的第一帧中指定。然后我们的跟踪器试图推断对象的类。[1]这是通过在序列的前五帧上运行对象检测器来完成的。在每一帧中,对象检测器将多个框与每个盒的最高置信度的对象类一起输出。在每一帧中,找到具有指定的对象位置的联合(IOU)具有最大交集的检测框,并记录该框的对象类。这些对象类中最常见的是被跟踪对象的推断类。
在推断出对象类别之后,在时间t的帧被馈送到对象检测器,并且给出一组N个框![]() 作为输出。这些框包含对象位置,对象类别和置信度分数。从这N个方框中,我们消除了所有类别与我们要跟踪的对象的类别不匹配的那些。这样我们最终得到
作为输出。这些框包含对象位置,对象类别和置信度分数。从这N个方框中,我们消除了所有类别与我们要跟踪的对象的类别不匹配的那些。这样我们最终得到![]() 个框,我们将其重新标记为
个框,我们将其重新标记为![]() 。这些框用于最终决策阶段,如下所述。
。这些框用于最终决策阶段,如下所述。
注意,所提出的跟踪框架依赖于语义(即,对象类)以消除帧中的一些不相关的对象/框。原则上,语义信息应在困难的情况下提供帮助,例如遮挡或多对象跟踪。但是,即使是非语义检测器(那些不输出对象类的检测器)也可以在我们的框架中使用,但是由于大量不相关的框以及在最后阶段做出错误决定的可能性较高,因此准确性可能会受到影响。
2.3.Final box decision-最终box选择
在目标检测器输出一组框![]() 之后,必须识别对应于目标的框。这是在第一阶段发现的ROI的帮助下完成的。在
之后,必须识别对应于目标的框。这是在第一阶段发现的ROI的帮助下完成的。在![]() 的框里,拥有最高IOU的框似乎是一个很好的候选者。然而,即使是最高的IOU也可以很小。因此,我们还将这个最高IOU与自适应阈值进行比较,以得到最终的决定。细节在算法1中给出。
的框里,拥有最高IOU的框似乎是一个很好的候选者。然而,即使是最高的IOU也可以很小。因此,我们还将这个最高IOU与自适应阈值进行比较,以得到最终的决定。细节在算法1中给出。
ROI和框![]() 之间的IOU计算为
之间的IOU计算为
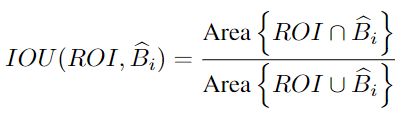 (3)
(3)
算法1中的自适应阈值![]() 相对于先前帧中的目标和ROI之间的IOU改变。该阈值的自适应(算法1中的线10-18)被设计为帮助对象检测器无法检测目标对象的情况,而是检测周围对象。它也有助于在闭塞的情况下。
相对于先前帧中的目标和ROI之间的IOU改变。该阈值的自适应(算法1中的线10-18)被设计为帮助对象检测器无法检测目标对象的情况,而是检测周围对象。它也有助于在闭塞的情况下。

在这种情况下,由对象检测器产生的方框在IOU(在算法1中的第10行)方面与前一帧中的目标不匹配,因此没有选择它们,而是将前一帧中的目标的位置作为当前帧的最后一个框![]() (在算法1中的第17行)。但是如果失配继续,IOU接受阈值减小(
(在算法1中的第17行)。但是如果失配继续,IOU接受阈值减小(![]() 增加在算法1中的第18行)。最终,较低的IOU接受阈值(算法1中的第10行)将使检测到的框中的一个被接受为最终框
增加在算法1中的第18行)。最终,较低的IOU接受阈值(算法1中的第10行)将使检测到的框中的一个被接受为最终框![]() 。
。
2.4. 总结
现在,我们总结了所提出的跟踪框架的几个关键特征。
兼容性与许多对象检测器:我们的跟踪框架的一个优点是,它不是至关重要地依赖于任何特定的对象检测器。当我们在实验中使用YOLO的三个版本用于演示目的时,也可以使用其他检测器, R-CNN [16], Fast R-CNN [17], Faster R-CNN [18], SSD [19],等。
资源共享:我们的跟踪框架中的对象检测器也可以用于其他应用。 例如,如果检测器放置在云中,则其他云服务可以将其用于其他目的,例如用户提供的照片中的对象检测。 这样,单个深度模型可以服务许多应用程序。
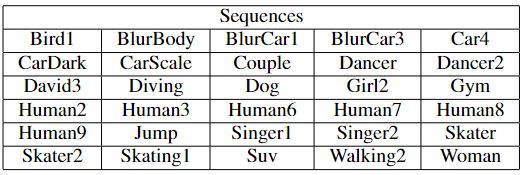
表I:实验中使用的序列表
数据重用:在跟踪中,运动通常是征服的关键挑战之一。但是在我们的框架中,运动是通过MVs来处理的,它存在于视频比特流中。对现有数据的重用加快了处理速度,并具有良好的工程意义。
鲁棒性:跟踪中的其他关键挑战是出现和改变。许多跟踪器试图对这些模型进行显式建模。我们的框架通过使用基于图像的对象检测器来处理这个问题,该对象不受先前帧中对象的外观的记忆的负担。结果,跟踪器对外观变化非常健壮,如图4(b)中的示例所示。
3.实验结果
3.1.实验设置
在OTB100数据集[20]中100个序列共有30个序列被选择用于测试。这些序列包含YOLO支持的对象类。它们被列在表I中。使用HEVC参考软件HM16.15 [21] 对测试序列进行编码,其中配置参数在encoder_lowdelay_P_main.cfg [22]中,并将量化参数(QP)设置为32。然后从压缩的HEVC比特流中提取运动矢量。
所提出的跟踪框架与DSST[1](VOT 2014挑战的获胜者)、CNN-SVM [2], and Re3 [3]进行了比较。后两者是基于目前主导这一领域的深度神经网络的跟踪器类的代表。在我们的框架中,我们使用了YOLO对象检测器的三个版本:YOLVO3 [14],YOLVO2 [15]和TinyYOLO [23],TinyYOLO是YOLVO2的简单版本。所得到的跟踪器分别被称为MV-YOLOv3,MV-YOLOv2和MV-TinyYOLO。YOLOv3,YOLOv2和TinyYOLO的检测阈值分别设置为0.1、0.1和0.03。
3.2.结果
为了评估跟踪器,执行一次通过评估(OPE)[20]。 成功和精确度图[20]如图3所示。对于每个跟踪器,成功曲线是从预测对象框和地面真值框的IOU得出的,而精确度曲线表示帧之间的平均欧几里德距离的百分比。 预测框的质心和地面真值小于给定阈值。 在成功图(图3中的顶部图表)中,图例中每个跟踪器旁边的方括号中表示曲线下面积(AUC)。 在“精度图”(下图)中,图例中的数字表示质心位于地面真实质心20像素内的预测框的百分比。
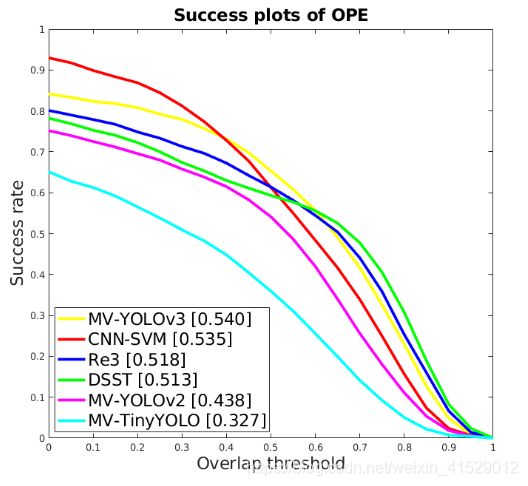
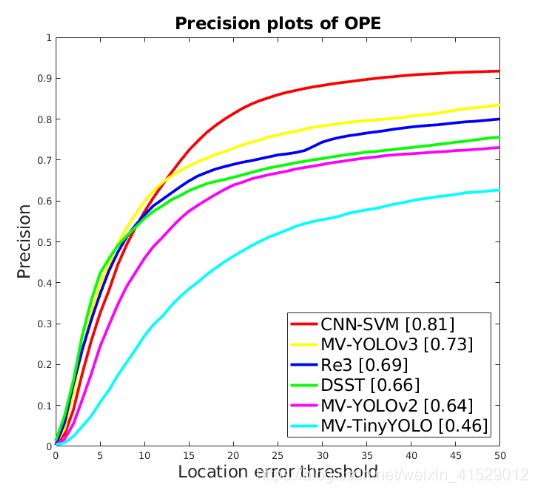
图3: 研究中跟踪方法的成功和精确曲线
如图3所示,所提出的跟踪框架的准确性取决于所使用的物体检测器。YOLOv3导致最佳准确性,其次是YOLOv2和TinyY-OLO。为了进一步说明这一点,表II列出了三种跟踪器版本的阈值分别为0.5和20时的重叠成功率(OSR)和距离精确率(DPR)[20]。DPR和OSR都遵循图3中的趋势,表明MV-YOLOv3是这三个中最准确的,而MV-TinyYOLO则是最不准确的。
但是,速度结果显示出相反的趋势。 表II的最后一行显示了所提出框架中三个跟踪器的速度。 跟踪器速度计算如下。 我们首先在台式机上使用MV生成ROI的速度进行了测量,该台式机采用3.40 GHz的Intel Corei7-6800K处理器,128 GB RAM和12 GB Nvidia Titan X GPU。 在此过程中,将忽略所有磁盘访问时间。 然后,我们将此时间添加到YOLO官方网站上报告的对象检测时间[23]。 这两次的和的倒数给出表II的最后一行中报告的速度,以每秒帧数(fps)为单位。 这三个追踪器中最快的是MV-TinyYOLO,速度为88 fps,最慢的是MV-YOLOv3,速度为28 fps,仍然相对较快。
表II:具有三个物体检测器的拟议跟踪框架的性能和速度。
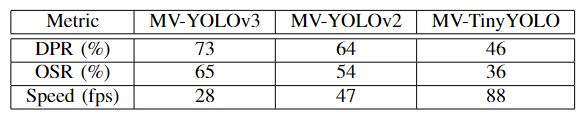
在这个测量期间,任何磁盘存取时间,忽略任何磁盘访问时间。然后我们将这个时间添加到官方YOLO网站上报告的对象检测时间[23]。这两次求和的倒数给出了表II的最后一行中每秒帧速(FPS)的速度。三个跟踪器中最快的是MV-TiNyYOLO,在88 fps,最慢的是MV-YOLVO3在28 fps,这仍然是相对快的并且接近于CNN-SVM and DSST的精度和成功结果取自各跟踪器的官方网站。对于Re3 [3] ,Re3的作者与我们在OTB100数据集上分享了他们的结果。我们从图3看出,MV-YOLVO3在所有测试跟踪器中具有最好的成功AUC,而CNN-SVM具有最好的精度。在这两种情况下,MV-YOLVO3比Re3更准确,这是令人鼓舞的。反过来,R3比DSST更准确,这是VOT 2014挑战中获胜的跟踪器。这说明了近几年来该领域取得的进展。在速度方面,所有三个版本的MV-YOLO都比CNN-SVM和DSST快,但是速度慢于Re3,根据各自论文中所报道的速度。
DSST [1],CNN-SVM [2]的Precision和Success结果来自每个跟踪器的官方网站。对于Re3 [3],Re3的作者与我们分享了他们在OTB100数据集上的结果。从图3中我们可以看到,在所有测试的跟踪器中,MV-YOLOv3的平均成功AUC最高,而CNN-SVM的平均精度最高。在精度和成功结果上,MV-YOLOv3比Re3更准确,这令人鼓舞。反过来,Re3比DSST更准确,DSST是2014年VOT挑战赛的获胜者。这说明了过去几年在该领域取得的进步。根据相应论文中报告的速度,MV-YOLO的所有三个版本都比CNN-SVM和DSST快,但比Re3慢。
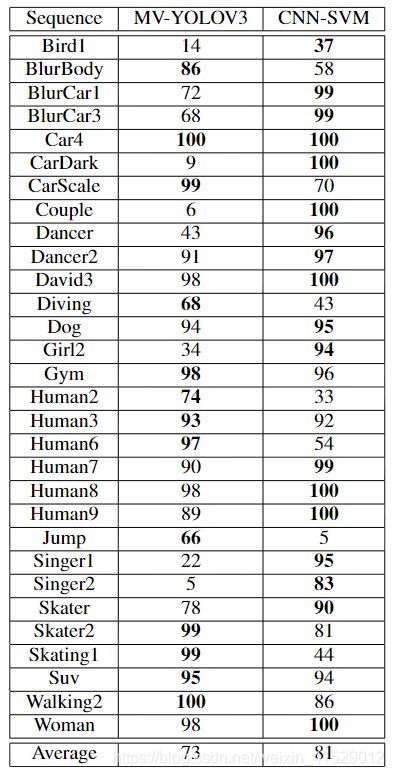
为了进一步分析MV-YOLOv3和CNN-SVM的精度结果,表III中分别报告了每个测试序列在20像素阈值处的DPR(%)的比较,其中更好的结果以粗体显示。尽管CNN-SVM的平均DPR较高,但MV-YOLOv3在几乎一半的测试序列中均优于CNN-SVM。与被跟踪对象(例如,鸟或汽车)同等级别的对象接近ROI,并且跟踪器意外地“锁定”了Toit。可能需要通过将对象属性合并到跟踪框架中来进一步处理这些情况。尽管如此,在许多序列中,MV-YOLOv3提供了比更复杂和慢的CNN-SVM更好的DPR。
表III:在MV-YOLOv3和CNN-SVM的测试序列中,在20个像素距离处的DPR(%)的比较[2]
最后,图4显示了MV-YOLOv3性能的一些直观示例,其中红色框表示从MV创建的投资回报(第II-A节),蓝色框表示最终的预测框(第II-C节)。图的(a)部分显示了遮挡,其中行人是被树干遮挡的履带。显着的遮挡从第82帧开始,一直持续到第85帧。在第82、83和84帧中,对象检测器未找到与ROI有明显重叠的框,因此从框81中选择了目标框作为预测目标位置(算法中的步骤17) 1),降低IOU接受阈值(算法1中的步骤18)。在第85帧中,仅检测到人的头部,并且被检测到的盒子的IOU和ROI相对较小,但是由于降低了IOU阈值在第82,83和84帧中,将检测到的框选为目标。跟踪器会锁定在人身上,并用一个跟踪头部的小盒子持续几帧。稍后,当人员处于全视野并且对象检测器完全检测到该对象时,跟踪器会再次将其锁定到该人员(框97和更高版本)。
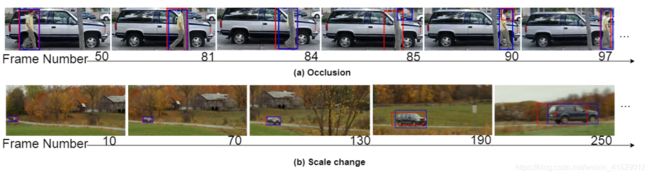
图 4: 当(a)发生阻塞或(b)发生尺度改变时,所提出方法的性能。红色框是从MV得出的ROI(第II-A节),蓝色框是最终预测的目标位置(第II-C节)。
图4(b)部分显示了所提出的跟踪框架对规模变化的鲁棒性。在第10帧中,被跟踪的汽车很小,位于该框架的左下角。在接下来的240帧内,汽车向右和向摄像机移动,而摄像机本身也向右移动。在第250帧处,汽车比第10帧大15倍,并且外观发生了变化:第10帧主要显示了汽车的前视图,而第250帧开始显示了后视图。在这些框架中,尽管外观发生了变化,仍可以准确地跟踪汽车。
3.3.最后的评论
如果对象检测器不支持要跟踪的对象的类别,则有两种解决方法。首先是针对所需的对象类别对检测器进行微调(使用转移学习)。或者,可以切换到通用对象检测器(例如“对象”)。
所提出的方法依赖于视频比特流中的MV,但不一定依赖于HEVC编码器产生的MV。由于最早的视频编码标准,MV被用来表示基于块的跨国运动,而这正是提出的框架所需要的。Ourtracker只需要一个提示即可-物体检测器提供了对物体箱的改进。
我们的跟踪框架的性能在很大程度上取决于对象检测器的准确性,而对象检测器的准确性又取决于输入图像的质量。不幸的是,OTB100数据集中的视频序列被逐帧存储为JPEG图像,这些JPEG图像的质量并不是特别好。在某些情况下,很容易看到编码伪像。为了获得用于测试的运动矢量,我们必须使用HEVC进一步对它们进行编码和解码,从而产生了其他伪像。这导致对象检测器在某些情况下错过了目标对象或错误地对对象进行了分类,从而对我们的结果产生了负面影响。该研究中的其他跟踪器未使用HEVC编码的帧,因此其性能不受其他HEVC编码的影响。
4.结论
在本文中,我们提出了MV-YOLO,这是一种新颖的跟踪框架,它结合了来自压缩视频比特流和语义对象检测的数据重用。基于在视频解码过程中提取的MV,在当前帧中创建目标对象的ROI。然后,语义对象检测器的输出将在ROI的帮助下更精确地定位目标对象。
实验表明,MV-YOLO是一种快速而强大的跟踪框架。MV-YOLO的准确性和速度取决于所使用的特定物体检测器。然而,即使我们测试最慢的版本是相当快的,在28fps,而它的准确率堪比最近trackersbased深模型。
在本研究中,我们仅检查了单个对象的跟踪。但是,MV-YOLO框架包含所有支持多对象跟踪的成分。这是未来研究的主题。
参考文献
[1] M. Danelljan, G. Hger, F. S. Khan, and M. Felsberg, “Discriminative scale space tracking,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 8, pp. 1561–1575, Aug 2017.
[2] S. Hong, T. You, S. Kwak, and B. Han, “Online tracking by learning discriminative saliency map with convolutional neural network,” in Proc. ICML’15, 2015, pp. 597–606.
[3] D. Gordon, A. Farhadi, and D. Fox, “Re3: Real-time recurrent regression networks for visual tracking of generic objects,” IEEE Robotics and Automation Letters, vol. 3, no. 2, pp. 788–795, April 2018.
[4] S. R. Alvar, H. Choi, and I. V. Baji´ c, “Can you tell a face from a HEVC bitstream?,” in Proc. IEEE International Conference on Multimedia Information Processing and Retrieval, 2018, to appear.
[5] S. R. Alvar, H. Choi, and I. V. Baji´ c, “Can you find a face from a HEVC bitstream?,” in Proc. IEEE ICASSP’18, 2018, to appear.
[6] Y. M. Chen, I. V. Baji´ c, and P. Saeedi, “Moving region segmentation from compressed video using global motion estimation and Markov random fields,” IEEE Trans. Multimedia, vol. 13, no. 3, pp. 421–431, June 2011.
[7] S. H. Khatoonabadi and I. V. Baji´ c, “Video object tracking in the compressed domain using spatio-temporal Markov random fields,” IEEE Trans. Image Processing, vol. 22, no. 1, pp. 300–313, Jan. 2013.
[8] L. Zhao, Z. He, W. Cao, and D. Zhao, “Real-time moving object segmentation and classification from HEVC compressed surveillance video,” IEEE Trans. Circuits Syst. Video Technol., 2018, to appear.
[9] S. Gl, J. T. Meyer, C. Hellge, T. Schierl, and W. Samek, “Hybrid video object tracking in H.265/HEVC video streams,” in Proc. IEEE MMSP’16, Sept 2016, pp. 1–5.
[10] H. Fan and H. Ling, “Parallel tracking and verifying: A framework for real-time and high accuracy visual tracking,” in Proc. IEEE ICCV’17, Oct 2017, pp. 5487–5495.
[11] G. Ning, Z. Zhang, C. Huang, X. Ren, H. Wang, C. Cai, and Z. He, “Spatially supervised recurrent convolutional neural networks for visual object tracking,” in Proc. ISCAS’17, May 2017, pp. 1–4.
[12] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
[13] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in Proc. IEEE CVPR’16, Jun. 2016, pp. 779–788.
[14] J. Redmon and A. Farhadi, “YOLOv3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018.
[15] J. Redmon and A. Farhadi, “YOLO9000: better, faster, stronger,” in IEEE CVPR, July 2017, pp. 6517–6525.
[16] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in Proc. IEEE CVPR’14, June 2014, pp. 580–587.
[17] R. Girshick, “Fast R-CNN,” in Proc. ICCV’15, Dec 2015, pp. 1440–1448.
[18] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” in Proc. NIPS’15, 2015, pp. 91–99.
[19] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Fu, and A. C. Berg, “SSD: Single shot multibox detector,” in Proc. European conference on computer vision. Springer, 2016, pp. 21–37.
[20] Y. Wu, J. Lim, and M. H. Yang, “Object tracking benchmark,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 37, no. 9, pp. 1834–1848, 2015.
[21] “HEVC reference software (HM 16.15),” https://hevc.hhi.fraunhofer.de/trac/hevc/browser/tags/HM-16.15, Accessed: 2017-05-27.
[22] F. Bossen, “Common HM test conditions and software reference configurations,” in ISO/IEC JTC1/SC29 WG11 m28412, JCTVC-L1100, Jan. 2013.
[23] J. Redmon, “YOLO: Real-time object detection,” https://pjreddie.com/darknet/yolo/, Accessed: 2018-04-25.