Redis基础知识
1:什么是Redis
Redis是一个免费开源的高性能key-value非关系型数据库,是为了解决高并发、高扩展等一系列问题而出现的数据库解决方案。
2:Redis为什么快
| 计算机存储介质读取速度 | ||||||
| 寄存器 | 一级缓存 | 二级缓存 | 三级缓存 | 内存 | 硬盘 | 远程硬盘(光盘) |
| 速度依次降低(寄存器读取速度最高) | ||||||
Redis数据是存储在内存中的,并且是单线程(不用在线程切换、锁等问题上消耗CPU,可以通过单线程多进程实现一定的性能提升)
3:Redis如何实现持久化
Redis实现持久化主要有两种方式:写日志AOF、快照RDB
AOF就是根据配置的策略把每次操作都持久化到一个日志文件中。
AOF主要有三种持久化策略:always(每操作一次就持久化,耗能明显)、everysec(每秒持久化一次,如若宕机会丢失几秒的数据--默认,也是常用)、no(Redis根据操作系统自动持久化,不可控)。
AOF文件主要是通过AOF重写来生成的,原生的AOF文件记录的确实是每次的操作记录,但是其中明显会有许多重复冗余的数据,这个原生的AOF日志文件只能当做日志文件,而持久化需要的AOF文件实际上把内存中数据进行一次数据回溯而生成的,然后替换原生的AOF文件。
AOF重写有两种方式:手动执行AOF重写命令、通过配置文件进行配置(主要配置文件重写尺寸与文件增长率)
RDB就是在某个时刻进行Redis持久化生成一个二进制的RDB文件。
RDB主要的三种持久化策略:客户端执行save命令(同步阻塞命令)、客户端执行bgsave命令(异步非阻塞命令)、自动(通过配置文件指定持久化时机--60秒1W条、300秒10条、900秒1条数据变化的那个配置,本质还是bgsave--常用)
如果Redis重启会优先使用AOF文件(误差小),相对而言二进制的RDB文件恢复数据速度其实更快一些。RDB更加适合大数据的持久化,比如一小时、一天一次的备份。
Redis4.0版本后可以两种持久化方式混合使用。
4:Redis的多种数据结构
Redis主要有五大数据类型,以及其他的四种衍生出来的数据类型。
一:String字符串
字符串的value最大是512M,常用incr命令去做一些计数器,也可以使用它做一个分布式锁
示例:set name Jacob、get name
二:Hash
Hash的value是由 field于value成对组成的,里面的field是不会重复的(重复则覆盖)。
常用于存储对象,比如某个用户的某个商品浏览次数的自增
hincrby username productIdViewNum 1 给username这个用户的productIdViewNum 这个属性 进行自增 1
示例:hset student name Jacob、hget student name
三:List列表
List的Value是一个可重复的有序队列,所以可以进行一些左右添加、弹出的,以及在获取指定索引范围内元素的操作。
常用于最新消息的存储、Redis消息队列
示例:rpush student Jacob Lisha Abell、lindex student 1 (获取该key索引1出的元素)、lset student 1 Lili (修改该key索引1出的元素)
四:Set集合
Set的Value是不可重复并且无序的,因为是集合所以可以进行一些集合间的操作,如取交集sinter、并集sunion、差集sdiff,还有可以随机弹出一个元素等操作。
常用于共同好友、共同关注,随机抽奖等场景。
示例:sadd names Jacob Lisha Abell(如果已存在那么就不会添加--不是覆盖是直接不添加,不存在就则会添加成功)、smembers names(获取该key中的所有元素)、srandmember names 3(随机获取该key中的3个元素)
五:Sorted Set有序集合
Sorted Set是有序并没有重复元素的,它的Value由两部分组成,一个score分数,一个value值,其中score就是排序的依据。
常用于热度排行榜、特价排行榜、关注度排行榜等场景中。
示例:zadd studentScore 66 Jacob 86 Lisha 79 Abell(实际会按照分数默认从小到大排序)、zscore studentScore Jacob(获取Jacob的分数)、zrange studentScore 1 2 withscores(获取2~3排名的元素并打印分值--打印分值可选项withscores)
六:BitMap位图
BitMap主要是通过二进制数据进行存储(主要是对位的一些操作),实现使用很小的内存实现高效存储,例如布隆过滤器。
| 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
它里面的运算有取并集、交集、非、异或操作,还可以获取value中为上为1或者0的总数统计等。
使用场景一:假设某个网站用户有1E,并且这些用户主键是从1~1E,现在需要统计每天该网站用户的登录情况,就可以创造一个1E的位,表示从1~1E这些用户,如果对应位上的用户上线过线,则用1,否则用0表示,从而实现每日活动用户的统计。
使用场景二:每日签到,用该用户做key,然后给一个31的位,哪天签到了就给设置1,否则为0。
示例:setbit mouth202002 0 1(设置mouth202002这个key对应的value第1位的值为1)、bitcount mouth202002 0 10(获取mouth202002这个Key对应value中从0~10索引之间出现1的次数的总和)。
七:HyperLogLog基数统计
HyperLogLog使用极小内存存储某个统计数。首先该类型也是往key里面存一个一个的元素,但是这些元素并不会真的存储,而是把这些元素通过一个算法进行了记录,从而实现该类型的特定功能,就是统计、合并!该类型就3个API,pfadd添加、pfmerge合并、pfcount统计。
该类型存在一定的误差性,错误率在0.81%左右。
八:GEO地理信息定位
GEO主要是用来存放经纬度的,所以它主要功能是计算两地的距离、范围等的相关运算。
示例:geoadd citis 116.28 39.55 bj 117.12 39.08 tj(往citis这个key中存放 bj和tj两个地方的经纬度)、geopos citis bj(获取bj的经纬度)、geodist citis bj tj km(查询bj tj两个经纬度之间的距离)
九:Stream流
Stream流是5.0后才正式加入的数据类型,主要是用于解决发布订阅中相关数据的问题。
5:Redis主从复制模式
Redis主从复制主要是在slave上辅助master,数据流是单向从master流向slave的。实现主从复制可以通过在slave上执行slaveof命令,或者直接修改slave的配置文件。
单机版主从复制存在众多问题,比如master挂了,写操作无法进行。由于复制需要一定的时间,所以读操作可能会读不到数据或者读到脏数据。也可能由于网络故障导致主从复制无法正确全量完成等。所以出现了Sentinel模式。
6:Sentinel哨兵高可用模式
Sentinel主要是针对主从复制中各个节点Redis故障进行判断、通知客户端、故障转移等的一些作用。
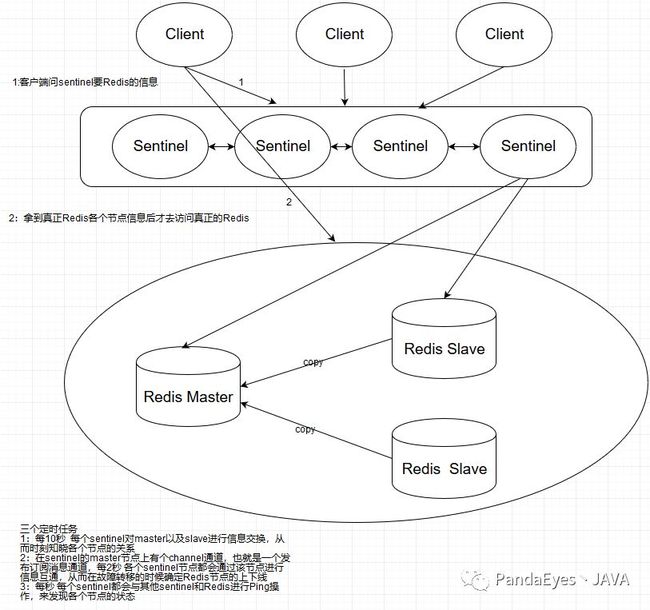
三个定时任务
1:每10秒 每个sentinel对master以及slave进行信息交换,从而时刻知晓各个节点的关系
2:在sentinel的master节点上有个channel通道,也就是一个发布订阅消息通道,每2秒 各个sentinel节点都会通过该节点进行信息互通,从而在故障转移的时候确定Redis节点的上下线
3:每秒 每个sentinel都会与其他sentinel和Redis进行Ping操作,来发现各个节点的状态
主观下线:当一个sentinel发现某个Redis节点出现故障后,当前sentinel节点对该Redis节点标记为下线操作。
客观下线:当某个sentinel进行主观下线后会通知其他sentinel我发现了故障,我要成为sentinel的master对那个Redis进行进行下线操作,然后开始sentinel的选举,各个sentinel对那个Redis节点进行信息交换,之后进行这次的选举活动,如若选举成功则进行Redis的客观下线,实现故障转移。
故障转移:sentinel会共选择一个slave做下一任master,而原来的master会变为一个slave,当这个slave恢复正常后,回去同步新master的数据。
sentinel解决了故障转移的问题,但是毕竟还只是单机多部署,单机的瓶颈依旧存在,所以需要使用Redis Cluster分片集群模式来实现数据的扩展。
7:Redis Cluster模式
Redis Cluster主要是为了解决单机多部署中数据量的瓶颈问题的,它类似于数据库的拆表行为(水平拆分),把原本一个表的数据查分到多个表中,Redis Cluster则是把一个Redis数据库数据分片拆分到多个Redis数据库中,然后通过集群实现分布式高可用式Redis数据库。
Redis Cluster主要有三个点:
1:节点 也就是分片为几个Redis Master,节点之间通过meet实现信息互通。
2:槽 由于是分片,所以需要确定每个片存放哪个范围内的数据,Redis Cluster总共是16384个槽。
3:主从节点 主要是给每个master分配从节点,分配几个自行决定,主要是为了实现高可用。
Redis Cluster由于分片,所以不能进行批量操作,但是可以自己根据需要查询的数据进行一定的逻辑处理,然后使用适当的方式进行获取(比如 串行meet、并行IO、串行IO、hash_tag等),还有会出现ask重定向、moved异常等问题。当然实际中我们大多是直接使用smart客户端来解决这些问题,比如JjedisCluster。
Redis Cluster中某些热点key需要更新时主要可以选择两种方式:互斥锁、永不过期机制。
互斥锁:当需要更新某个热点key时,那么就是锁住该key的获取,然后进行重构,直至重构完成后再放开该key的获取。
永不过期机制:当需要更新某个热点key时,开启一个异步更新操作,如果更新过程中有获取key的操作,那么就返回原来老的值,知道更新完成后才更新当前key的值。
8:Redis雪崩与穿透与击穿
雪崩:主要是由于缓存过掉或者逻辑问题,导致大量访问直接访问数据库,这里访问的数据一般都是数据库存在的。
解决方法:主从结构,master宕机后从节点可以实现高可用。还有就是访问源限流、资源熔断、降级设置进行处理。
穿透:主要是大量请求访问Redis,而Redis没有该数据,然后去访问数据库,而数据库也没有该数据,整个过程就是一个穿透的过程(黑客或者爬虫)。
解决方法:如果整个过程是一个穿透过程,那么可以给缓存放一个一定时限的标识值,或者使用布隆过滤器。
击穿:也就是某些热点key更新时的瞬间,造成大量访问直接请求数据库。
解决方法:可通过互斥key或者永不过期机制进行处理。
如文中有所错误,还望各位多多指教。谢谢!