数据分析入门项目之 :Titanic: Machine Learning from Disaster
1.摘要:
本文详述了新手如何通过数据预览,探索式数据分析,缺失数据填补,删除关联特征以及派生新特征等数据处理方法,完成Kaggle的Titanic幸存预测要求的内容和目标。
2.背景介绍:
Titanic幸存预测是数据分析入门和机器学习入门经典的开源项目之一。它要求我们通过训练数据集分析出具有什么特征的人更可能幸存,并预测出测试数据集中的每一位乘客是否生还。
该项目是一个二元分类问题
3.数据处理完整流程:
3.1:加载数据
在加载数据前,把可能会用到的相关包全部加载。
#基本数据分析
import pandas as pd
import numpy as np
#可视化
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
#模型, 数据处理,模型融合 相关方法。
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from xgboost import XGBClassifier
from sklearn.metrics import precision_score
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import GridSearchCV, cross_val_score, StratifiedKFold, learning_curve
import warnings
warnings.filterwarnings('ignore')通过如下代码将训练数据和测试数据分别加载到名为train_df和test_df的data.frame中
train_df=pd.read_csv('titanic/train.csv')#训练集
test_df=pd.read_csv('titanic/test.csv')#测试集
#把训练数据和测试数据放一起进行数据处理
combine = pd.concat([train_df,test_df])3.2 数据预览
先观察数据
print(train_df.describe())
print(test_df.describe())
train_df.describe(include=['O'])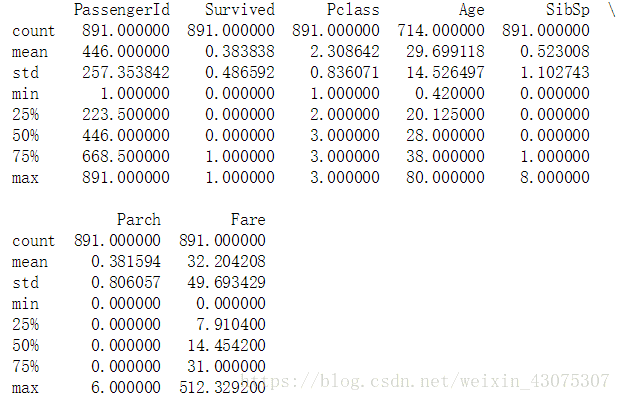


把训练数据和测试数据放一起进行数据处理
combine = pd.concat([train_df,test_df])
combine.head()
PassengerId :标识乘客的ID
Survived:标识该乘客是否幸存。
Pclass:标识乘客的船舱等级
Name:除包含姓和名以外,还包含Mr. Mrs. Dr.这样的具有西方文化特点的信息
Sex:标识乘客性别
Age:标识乘客年龄,有缺失值
SibSp:代表兄弟姐妹及配偶的个数。
Parch:代表父母或子女的个数
Ticket:代表乘客的船票号
Fare:代表乘客的船票价
Cabin:代表乘客所在的舱位,有缺失值
Embarked 代表乘客登船口岸
在这个问题中:
一共有891个样本
Survived的标签是通过0或1来区分
大概38%的样本是survived
大多数乘客(>75%)没有与父母或是孩子一起旅行
大约30%的乘客有亲属和/或配偶一起登船
票价的差别非常大,少量的乘客(<1%)付了高达$512的费用
很少的乘客(<1%)年纪在64-80之间
上面3个表了解到,Age Cabin Fare Embarked 存在缺失值
3.31 乘客等级越高,幸存率越高
plt.figure(figsize=(12,4))
train_df.pivot_table(index='Pclass',
columns='Survived',
values='PassengerId',
aggfunc='count').plot.bar(stacked=True)
plt.title(u"根据舱等级的获救情况");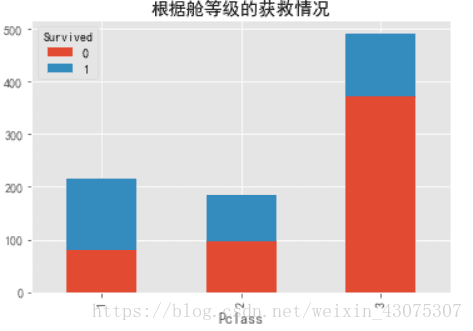
根据可视化结果发现:1等舱的人生存率超过了50%,2等舱,3等舱生存率递减。
将Pclass作为特征之一。这里我们把船舱位置离散化。
df=pd.get_dummies(combine['Pclass'],prefix='Pclass')
combine=pd.concat([combine,df],axis=1)3.32 不同Title的乘客幸存率不同
乘客姓名重复度太低,不适合直接使用。而姓名中包含Mr. Mrs. Dr.等具有文化特征的信息,可将之抽取出来。
我们在丢弃Name与PassengerId这两个特征之前,希望从Name特征里提取出Titles的特征,并测试Titles与survival之间的关系。
在下面的代码中,我们通过正则提取了Title特征,正则表达式为(\w+.),它会在Name特征里匹配第一个以“.”号为结束的单词。
同时,指定expand=False的参数会返回一个DataFrame。
combine['Title'] = combine.Name.str.extract('([A-Za-z]+)\.', expand=False)
pd.crosstab(combine['Title'], combine['Sex'])
表中最多的四个称谓是MISS Mr Mrs Master
所以把所有的male全部称呼为Mr
但是女人分为Miss 和Mrs 两类,查阅资料,把剩下的称呼归到Miss或者Mrs里来。
Mme:称呼非英语民族的”上层社会”已婚妇女,及有职业的妇女
Lady:贵族夫人
the Countess:女伯爵
Ms:美国用来称呼婚姻状态不明的妇女
Mlle:小姐
Dona:家庭主妇
combine['Title'] = combine['Title'].replace(['Lady', 'Countess',
'Dr','Mme', 'Dona'], 'Mrs')
combine['Title'] = combine['Title'].replace(['Don','Dona',
'Major', 'Capt', 'Jonkheer', 'Rev', 'Col','Sir','Dr'],'Mr')
combine['Title'] = combine['Title'].replace(['Mlle','Ms'],'Miss')combine[['Title','Survived']].groupby('Title').mean().plot.bar()
plt.title('名字中带有不同称谓的获救情况')
train_df[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()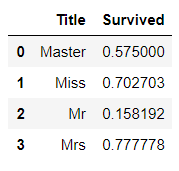
从上面的可视化图和Title表可看出,Title为Mr的乘客幸存比例非常小,而Title为Mrs和Miss的乘客幸存比例非常大。
我们决定保留这个新的Title特征并加入到训练模型
把Title名字离散化
df2=pd.get_dummies(combine['Title'],prefix='Title')
combine=pd.concat([combine,df2],axis=1)3.33 女性幸存率远高于男性
对于Sex变量,由Titanic号沉没的背景可知,逃生时遵循“妇女与小孩先走”的规则,由此猜想,Sex变量应该对预测乘客幸存有帮助。
combine.pivot_table( index='Sex',
columns='Survived',
values='PassengerId',
aggfunc='count').plot.bar(stacked=True)
plt.title('不同性别的获救情况')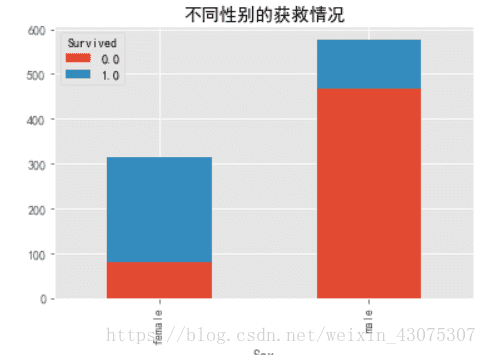
可视化的结果验证了这一猜想,大部分女性得以幸存,而男性中只有很小部分幸存。
3.34 名字长度也和幸存与否有关?
train_df.groupby(train_df.Name.apply(lambda x: len(x)))['Survived'].mean().plot()
plt.title('不同名字长度获救概率的分布情况')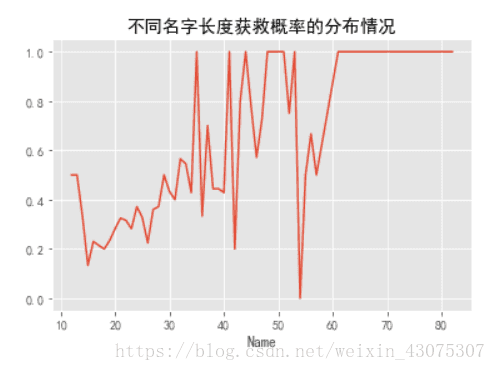
大概是Name长度越长,Name里包含的称谓越多,社会地位越高吧。
我们把名字长度分成5个区间并进行离散化。
combine['Name_Len'] = combine['Name'].apply(lambda x: len(x))
combine['Name_Len'] = pd.qcut(combine['Name_Len'],5)
df10 = pd.get_dummies(combine['Name_Len'],prefix='Name_Len')
combine = pd.concat([combine,df10],axis=1)3.35 配偶及兄弟姐妹数适中的乘客更易幸存;父母与子女数适中的乘客更可能幸存;生成新的Feature(FamilySize)
train_df.pivot_table(index='SibSp',
columns='Survived',
values='PassengerId',
aggfunc='count').plot.bar()
plt.title('不同亲戚数量获救情况')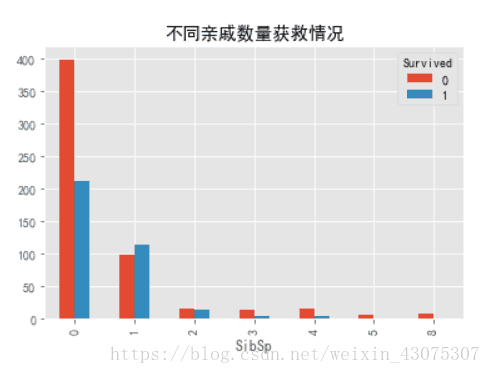
train_df.pivot_table(index='Parch',
columns='Survived',
values='PassengerId',
aggfunc='count').plot.bar()
plt.title('不同父母孩子数量获救情况')
SibSp与Parch都说明,当乘客无亲人时,幸存率较低,乘客有少数亲人时,幸存率高于50%,而当亲人数过高时,幸存率反而降低。在这里,可以考虑将SibSp与Parch相加,生成新的变量,FamilySize(家庭成员数量)。
combine['Familysize']=combine['Parch']+combine['SibSp']
combine.pivot_table(index='Familysize',
columns='Survived',
values='PassengerId',
aggfunc='count').plot.bar()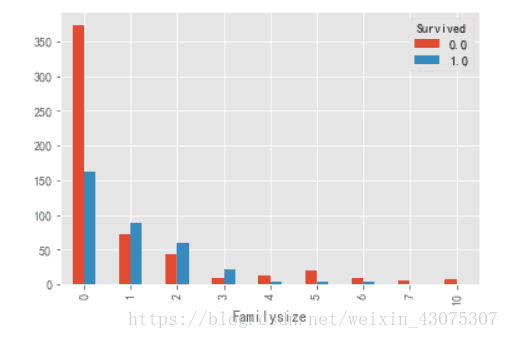

从图中可以看到,当家庭成员数为0时,生存率不足1/3,当家庭成员数在1-3之间的时候,生存率在50%以上,当家庭成员超过3个时,生存率骤降,不足50%
我们把Familysize作为新的特征变量加入要训练的模型中。
分成3组,并离散化。
combine['Familysize'] = np.where(combine['Familysize']==0, 'solo',
np.where(combine['Familysize']<=3, 'normal', 'big'))
df4 = pd.get_dummies(combine['Familysize'],prefix='Familysize')
combine = pd.concat([combine,df4],axis=1)3.36 添加一些特别的Feature
因为Sex对于Survived的影响很大,并且在泰坦尼克场景下,女性死亡和男性存活都是小概率事件,模型会很容易判断女性乘客存活、男性乘客死亡,为了提升模型对于这一类群体的识别能力,我们分析数据找到了一个重要特征,family,同一个family下的生存死亡模式有很大程度上是相同的,例如:有一个family有一个女性死亡,这个family其他的女性的死亡概率也比较高。
因此,我们把这些特殊的family标注出来作为特征值。
combine['Fname'] = combine['Name'].apply(lambda x:x.split(',')[0])
combine['Familysize'] = combine['SibSp']+combine['Parch']
dead_female_Fname = list(set(combine[(combine.Sex=='female') & (combine.Age>=12)
& (combine.Survived==0) & (combine.Familysize>1)]['Fname'].values))
survive_male_Fname = list(set(combine[(combine.Sex=='male') & (combine.Age>=12)
& (combine.Survived==1) & (combine.Familysize>1)]['Fname'].values))
combine['Dead_female_family'] = np.where(combine['Fname'].isin(dead_female_Fname),1,0)
combine['Survive_male_family'] = np.where(combine['Fname'].isin(survive_male_Fname),1,0)
combine = combine.drop(['Name','Fname'],axis=1)3.37 共票号乘客幸存率高
我们把那些票号一样的乘客的属性变成Share,把那些单独票号的乘客的属性变成Unique
a=combine.groupby('Ticket').Ticket.count()
b=np.arange(0,929)
for i in b:
if a[i]>1:
combine.loc[combine.Ticket==a.index[i],'newTicket']='Share'
else:
combine.loc[combine.Ticket==a.index[i],'newTicket']='Unique'可视化newTicket
combine.pivot_table(index='newTicket',
columns='Survived',
values='PassengerId',
aggfunc='count').plot.bar(stacked=True)

我们能明显的看到共享Ticket的乘客生存率超过了50%,而唯一票号的乘客生存率只有不到30%。这里我猜想是因为共同票号的乘客是朋友或者亲戚家人,所以相互关照,相互救援,生存率上升。
我们把票号唯一与否也加入Feature里面。
df8 = pd.get_dummies(combine['newTicket'],prefix='Ticket')
combine = pd.concat([combine,df8],axis=1)3.38 支出船票费越高幸存率越高
因为Fare只有一个缺失值,这里考虑用median去填补它。然后把填补后的Fare分组,看一下不同船票支出对Survived的影响大小。
combine['Fare'].fillna(combine['Fare'].dropna().median(), inplace=True)
combine['bins'] = pd.qcut(combine['Fare'],3 )
combine[['bins', 'Survived']].groupby(['bins'], as_index=False).mean()
我们可以看到,Fare越大,存活率越高。
把bins离散化,加入到Feature中
df7 = pd.get_dummies(combine['bins'],prefix='bins')
combine = pd.concat([combine,df7],axis=1)3.39 不同码头登船的乘客幸存率不同
因为缺失值只有2个,所以也用median代替。
combine['Embarked'] = combine['Embarked'].fillna('S')
train_df.pivot_table(index='Embarked',
columns='Survived',
values='PassengerId',
aggfunc='count').plot.bar(stacked=True)
plt.title(u"各登录港口乘客的获救情况")
plt.xlabel(u"登录港口")
plt.ylabel(u"人数") 
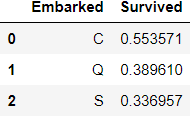
可以看到,C口的幸存率超过了50%,S码头登船的乘客存活率最低。
Embarked与生存率相关,离散化后加入Feature。
df6 = pd.get_dummies(combine['Embarked'],prefix='Embarked')
combine = pd.concat([combine,df6],axis=1)3.40有无Cabin记录的乘客幸存率不同
先对Cabin进行处理,有缺失值标记为YES,不是缺失值的标记为NO
combine.loc[(combine.Cabin.notnull()),'Cabin'] = 'Yes'
combine.loc[(combine.Cabin.isnull()),'Cabin'] = 'No'
combine.pivot_table(index='Cabin',
columns='Survived',
values='PassengerId',
aggfunc='count').plot.bar()
plt.title('有无Cabin的获救情况')

有Cabin记录的乘客生存率高达66%,没有记录的乘客生存率低至29.9%
加入Feature。
df5 = pd.get_dummies(combine['Cabin'],prefix='Cabin')
combine = pd.concat([combine,df5],axis=1)
4 两种方法填补Age缺失值
4.1 随机森林来预测填补Age值
这里面的的Age可以用随机森林来求,可以groupby以后,不同的区间的median来求。
我们这里先用scikit-learn中的RandomForest来拟合一下缺失的年龄数据
# 乘客分成已知年龄和未知年龄两部分
Age_isnull=combine[combine.Age.isnull()]
Age_notnull=combine[combine.Age.notnull()]
from sklearn.ensemble import RandomForestRegressor
def set_missing_age(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age','Fare', 'Parch', 'SibSp', 'Pclass_1', 'Pclass_2',
'Pclass_3']]
Age_isnull=age_df[age_df.Age.isnull()]
Age_notnull=age_df[age_df.Age.notnull()]
x = Age_notnull.drop(['Age'],axis=1)
y = Age_notnull['Age']
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(x,y)
predictedAges = rfr.predict(Age_isnull.drop(['Age'],axis=1))
# 用得到的预测结果填补原缺失数据
df.loc[(df.Age.isnull()),'Age'] = predictedAges
return df
combine=set_missing_age(combine)
fig=plt.figure(figsize=(12,6))
plt.subplot(121)
train_df[train_df.Survived ==1].Age.plot.hist(bins=16)
plt.title('Survived==1')
plt.subplot(122)
train_df[train_df.Survived ==0].Age.plot.hist(bins=16)
plt.title('Survived==0')
combine['Agebins'] = pd.cut(combine['Age'], 5)
combine[['Agebins', 'Survived']].groupby(['Agebins']).mean().sort_values(by='Agebins', ascending=True)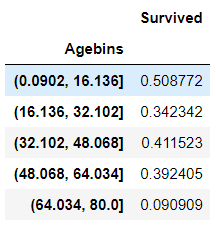
经过缺失值填补分组后,我们可以清楚的看到小孩子的获救概率是最高的,年轻人和老年人死亡率较高,猜测 中年人可能有一部分是Pclass=1的等级。 离散化,加入Feature
df9 = pd.get_dummies(combine['Agebins'],prefix='Agebins')
combine = pd.concat([combine,df9],axis=1)4.2 groupby分组后填补。
不同的年龄有不同的称呼,比如年轻女孩称呼MISS,年龄稍大的女人称呼Mrs。所以,可能Age和Title有关。 年龄较大可能有更高的等级和地位,所以可能Age和Pclass也有关。
先把Title和Pclass分组,然后求每一个组的众数Age,用这些数来填补那些分在同一组的缺失值。
group = combine_df.groupby([‘Title’, ‘Pclass’])[‘Age’]
combine_df[‘Age’] = group.transform(lambda x: x.fillna(x.median()))
group = combine.groupby(['Title', 'Pclass'])['Age']
combine['Age'] = group.transform(lambda x: x.fillna(x.median()))4.3 小孩子的标签很重要。
我们一直遵循着女人和小孩优先的原则,所以我们还要添加一个Kid的标签加入Feature。
combine['IsChild'] = np.where(combine['Age']<=12,1,0)5 建模数据准备
保留有用的特征向,将所有数据数值化。
#丢掉多余的columns
combine=combine.drop(['Age','Embarked','Fare','Parch','Sex','SibSp','Cabin','Pclass',
'Ticket','bins','newTicket','Familysize','Title','Name_Len','Agebins'],axis=1)
#把Feature Name 替换了
combine.rename(columns={'bins_(-0.001, 8.662]':'Fare_1',
'bins_(8.662, 26.0]':'Fare_2',
'bins_(26.0, 512.329]':'Fare_3',
'Agebins_(0.0902, 16.136]':'Age_step1',
'Agebins_(16.136, 32.102]':'Age_step2',
'Agebins_(32.102, 48.068]':'Age_step3',
'Agebins_(48.068, 64.034]':'Age_step4',
'Agebins_(64.034, 80.0]':'Age_step5',
'Name_Len_(11.999, 19.0]':'Name_lenstep1',
'Name_Len_(19.0, 23.2]':'Name_lenstep2',
'Name_Len_(23.2, 27.0]':'Name_lenstep3',
'Name_Len_(27.0, 32.0]':'Name_lenstep4',
'Name_Len_(32.0, 82.0]':'Name_lenstep5'},inplace=True)
combine.columns #查看剩下的columns
#把所有Feature值转化为数值型编码:
features = combine.drop(["PassengerId","Survived"], axis=1).columns
le = LabelEncoder()
for feature in features:
le = le.fit(combine[feature])
combine[feature] = le.transform(combine[feature])
combine.head()
#提取数据集
X_all = combine.iloc[:891,:].drop(["PassengerId","Survived"], axis=1)
Y_all = combine.iloc[:891,:]["Survived"]
X_test = combine.iloc[891:,:].drop(["PassengerId","Survived"], axis=1)6 建模调优
6.1 分别考察逻辑回归、支持向量机、最近邻、决策树、随机森林、gbdt、xgbGBDT几类算法的性能。
#提取这几种算法,放在clfs里
lr = LogisticRegression()
svc = SVC()
knn = KNeighborsClassifier(n_neighbors = 3)
dt = DecisionTreeClassifier()
rf = RandomForestClassifier(n_estimators=300,min_samples_leaf=4,class_weight={0:0.745,1:0.255})
gbdt = GradientBoostingClassifier(n_estimators=500,learning_rate=0.03,max_depth=3)
xgbGBDT = XGBClassifier(max_depth=3, n_estimators=300, learning_rate=0.05)
clfs = [lr, svc, knn, dt, rf, gbdt, xgbGBDT]
#这里的cross_val_score交叉验证的方法可以帮助我们进行调参,最终得到一组最佳的模型参数,使得测试数据的准确率和泛化能力最佳。
kfold = 10
cv_results = []
for classifier in clfs :
cv_results.append(cross_val_score(classifier, X_all,
y = Y_all, scoring = "accuracy", cv = kfold, n_jobs=4))
算出每个模型的准确率的平均值和标准差
cv_means = []
cv_std = []
for cv_result in cv_results:
cv_means.append(cv_result.mean())
cv_std.append(cv_result.std())
cv_res = pd.DataFrame({"CrossValMeans":cv_means,"CrossValerrors": cv_std,
"Algorithm":["LR","SVC",'KNN','decision_tree',"random_forest","GBDT","xgbGBDT"]})
print('cv_res')
g = sns.barplot("CrossValMeans","Algorithm",data = cv_res, palette="Set3",orient = "h",**{'xerr':cv_std})
g.set_xlabel("Mean Accuracy")
g = g.set_title("Cross validation scores")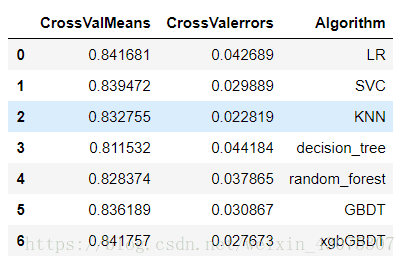

6.2 把不同的模型组合在一起
#定义一个类
class Ensemble(object):
#创建类中的函数:
def __init__(self,estimators):
self.estimator_names = []
self.estimators = []
for i in estimators:
self.estimator_names.append(i[0])
self.estimators.append(i[1])
self.clf = LogisticRegression()
#拟合训练集和训练结果
def fit(self, train_x, train_y):
for i in self.estimators:
i.fit(train_x,train_y)
x = np.array([i.predict(train_x) for i in self.estimators]).T
y = train_y
self.clf.fit(x, y)
#用拟合好的模型来预测
def predict(self,x):
x = np.array([i.predict(x) for i in self.estimators]).T
#print(x)
return self.clf.predict(x)
#比较预测结果
def score(self,x,y):
s = precision_score(y,self.predict(x))
return s把不同的分类器放进集成框架中
bag = Ensemble([('xgb',xgbGBDT),('lr',lr),('rf',rf),('svc',svc),('gbdt',gbdt)])
score = 0
#评估模型,把训练集随机分成0.8份(X_train)和0.2份(X_cv), 拟合训练数据然后预测X_cv,得到的结果和Y_cv比较,重复10次,算出最终得分。
for i in range(0,10):
num_test = 0.20
X_train, X_cv, Y_train, Y_cv = train_test_split(X_all, Y_all, test_size=num_test)
bag.fit(X_train, Y_train)
#Y_test = bag.predict(X_test)
acc_xgb = round(bag.score(X_cv, Y_cv) * 100, 2)
score+=acc_xgb
print(score/10) #83.0597 总结:
最后在官网上提交的结果是0.79904,新更新排名17%。

7.1 值得改进的地方:
- 1.我们可以把Title中频数小的称呼提取出来,形成一个新的Feature。
- 2.预测Age的随机森林模型中的Feature可以更加的详细。而且应该用填补缺失值以后的特征向量去拟合模型。
- 3.也许名字长度没有那么重要???
- 4.模型准确度的天花板取决于特征工程,所以当以上3个小tips都完成以后,试着换一种模型融合算法,看能不能有更好的结果。
- 如果您看到这里,那就点个赞再走咯~~
- 祝数据分析和机器学习之路一切顺利!!
8 改进之后的排名

1,我把Title那些名称使用较少的名字提取出来,然后用Rare命名成立一个单独的feature。

2,用随机森林预测Age只保留了Title和Pclass两个特征值。最后得分0.808
