腾讯百亿级请求高可用Redis(codis)分布式集群实践

文/腾讯技术团队
编辑/Emma
本文整理了腾讯技术团队, jackiej、liam等技术专家们的分享,内容包括:使用Redis(codis)的应用场景、遇到的问题及优化方案、脑裂处理、分布式集群、如何避坑等等。
01
Redis有哪些常用的应用场景
string |
计数器,用户信息(id)映射,唯一性(例如用户资格判断),bitmap |
hash |
常见场景:存储对象的属性信息(用户资料) |
list |
常见场景:评论存储,消息队列 |
set |
常见场景:资格判断(例如用户奖励领取判断),数据去重等 |
sorted set |
常见场景:排行榜,延时队列 |
其他 |
分布式锁设计 推荐2篇文章: 基于Redis的分布式锁到底安全吗(上) http://zhangtielei.com/posts/blog-redlock-reasoning.html 基于Redis的分布式锁到底安全吗(下) http://zhangtielei.com/posts/blog-redlock-reasoning-part2.html |
02
Redis选型思考
时延
时延=后端发起请求db(用户态拷贝请求到内核态)+ 网络时延 + 数据库寻址和读取
如果想要降低时延,只能减少请求数(合并多个后端请求)和减少数据库寻址和读取得时间。从降低时延的角度,基于单线程和内存的redis,每秒10万次得读写性能肯定远远胜过磁盘读写性能。
数据规模
以redis一组K-V为例(”hello” -> “world”),一个简单的set命令最终会产生4个消耗内存的结构。

关于Redis数据存储的细节,又要涉及到内存分配器(如jemalloc),简单说就是存储170字节,其实内存分配器会分配192字节存储。

那么总的花费就是
一个dictEntry,24字节,jemalloc会分配32字节的内存块
一个redisObject,16字节,jemalloc会分配16字节的内存块
一个key,5字节,所以SDS(key)需要5+9=14个字节,jemalloc会分配16字节的内存块
一个value,5字节,所以SDS(value)需要5+9=14个字节,jemalloc会分配16字节的内存块
综上,一个dictEntry需要32+16+16+16=80个字节。
03
三种Redis分布式解决方案对比

基于以上比较,codis作为开源产品,可以很直观的展示出codis运维成本低,扩容平滑最核心的优势.
对于数据安全目前我们基于机器本机48小时滚动备份加上公司刘备备份(每天定时目录备份的系统)的兜底备份,对于监控,目前接入monitor单机备份和米格监控告警)
04
Redis分布式解决方案
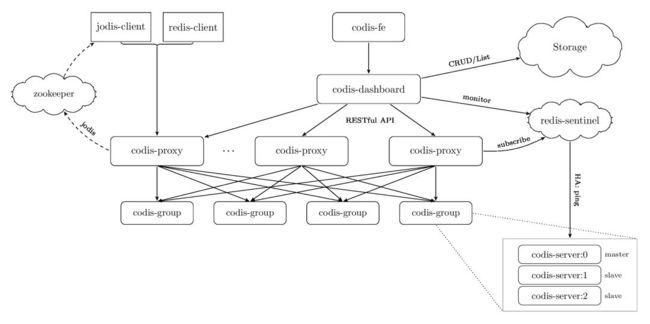
如上图所示,codis整体属于二层架构,proxy+存储,相对于ckv+无proxy的设计来说整体设计会相对简单,同时对于客户端连接数据逐渐增大的情况下,也不用去做数据层的副本扩容,而只需要做proxy层的扩容,从这一点上看,成本会低一些,但是对于连接数不大的情况下,还需要单独去部署proxy,从这一点上看,成本会高一些。
05
redis瓶颈和优化
HGETALL
最终存储到redis中的数据结构如下图。

采用同步的方式对三个月(90天)进行HGETALL操作,每一天花费30ms,90次就是2700ms!redis操作读取应该是ns级别的,怎么会这么慢?利用多核cpu计算会不会更快?

常识告诉我,redis指令执行速度 >> 网络通信(内网) > read/write等系统调用。因此这里其实是I/O密集型场景,就算利用多核cpu,也解决不到根本的问题,最终影响redis性能,**其实是网卡收发数据和用户态内核态数据拷贝**。
pipeline
这个需求qps很小,所以网卡也不是瓶颈了,想要把需求优化到1s以内,减少I/O的次数是关键。换句话说,充分利用带宽,增大系统吞吐量。
于是我把代码改了一版,原来是90次I/O,现在通过redis pipeline操作,一次请求半个月,那么3个月就是6次I/O。很开心,时间一下子少了1000ms。

pipeline携带的命令数
代码写到这里,我不经反问自己,为什么一次pipeline携带15个HGETALL命令,不是30个,不是40个?换句话说,一次pipeline携带多少个HGETALL命令才会发起一次I/O?
我使用是golang的redisgo 的客户端,翻阅源码发现,redisgo执行pipeline逻辑是 把命令和参数写到golang原生的bufio中,如果超过bufio默认最大值(4096字节),就发起一次I/O,flush到内核态。

redisgo编码pipeline规则如下图,*表示后面参数加命令的个数,$表示后面的字符长度,一条HGEALL命令实际占45字节。
那其实90天数据,一次I/O就可以搞定了(90 * 45 < 4096字节)!

果然,又快了1000ms,耗费时间达到了1秒以内

对吞吐量和qps的取舍
笔者需求任务算是完成了,可是再进一步思考,redis的pipeline一次性带上多少HGETALL操作的key才是合理的呢?换句话说,服务器吞吐量大了,可能就会导致qps急剧下降(网卡大量收发数据和redis内部协议解析,redis命令排队堆积,从而导致的缓慢),而想要qps高,服务器吞吐量可能就要降下来,无法很好的利用带宽。
06
Redis高可用及容灾处理
作为codis的实现来讲,数据高可靠主要是redis本身的能力,通常存储层的数据高可靠,主要是单机数据高可靠+远程数据热备+定期冷备归档实现的
单机数据高可靠主要是借助于redis本身的持久化能力,rdb模式(定期dum)与aof模式(流水日志),这块可以参考前文所示的2本书来了解,其中aof模式的安全性更高,目前我们线上也是将aof开关打开,在文末也会详细描述一下。
远程数据热备主要是借助于redis自身具备主从同步的特性,全量同步与增量同步的实现,让redis具体远程热备的能力
定期冷备归档由于存储服务在运行的过程中可能存在人员误操作数据,机房网络故障,硬件问题导致数据丢失,因此我们需要一些兜底方案,目前主要是单机滚动备份备份最近48小时的数据以及sng的刘备系统来做冷备,以备非预期问题导致数据丢失,能够快速恢复。
codis的架构本身分成proxy集群+redis集群,proxy集群的高可用,可以基于zk或者l5来做故障转移,而redis集群的高可用是借助于redis开源的哨兵集群来实现,那边codis作为非redis组件,需要解决的一个问题就是如何集成redis哨兵集群。本节将该问题分成三部分,介绍redis哨兵集群如何保证redis高可用,codisproxy如何感知redis哨兵集群的故障转移动作,redis集群如何降低“脑裂”的发生概率。
哨兵集群如何保证redis高可用
Sentinel(哨岗,哨兵)是Redis的高可用解决方案:由一个或多个Sentinel实例组成的Sentinel系统,可以监视任意多个主服务器,以及这些主服务器属下的所有的从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器,然后由主服务器代替已下线的主服务器继续处理命令请求。

07
Redis脑裂处理
脑裂(split-brain)集群的脑裂通常是发生在集群中部分节点之间不可达而引起的。如下述情况发生时,不同分裂的小集群会自主的选择出master节点,造成原本的集群会同时存在多个master节点。,结果会导致系统混乱,数据损坏。

由于redis集群不能单纯的依赖过半选举的模式,因为redismaster自身没有做检测自身健康状态而降级的动作,所以我们需要一种master健康状态辅助判断降级的方式。具体实现为
1)降级双主出现的概率,让Quorums判断更加严格,让主机下线判断时间更加严格,我们部署了5台sentinel机器覆盖各大运营商IDC,只有4台主观认为主机下线的时候才做下线。
2)被隔离的master降级,基于共享资源判断的方式,redis服务器上agent会定时持续检测zk是否通常,若连接不上,则向redis发送降级指令,不可读写,牺牲可用性,保证一致性。
08
使用Redis趟过的坑
主从切换: 每次主从切换之后,都确认一下被切的主或者备机上的conf文件都已经rewriteok。
grep "Generatedby CONFIG REWRITE" -C 10 {redis_conf路径}/*.conf
迁移数据:关键操作前,备份数据,若涉及切片信息,备份切片信息
A迁移B时间过长的命令查看:连上Acodisserver,命令行中执行slotsmgrt-async-status查看正在迁移的分片信息(尤其是大key),做到心中有数。千万级别的key约20秒左右可以迁移完成
异常处理:redis宕机后重启,重启之后加载key快加载完时,页面上报error
原因 |
可能是宕机后,redis命令写入aof,只写了命令的部分或者事务提交之后只写入了事务的部分命令导致启动失败,此时日志会aof的异常 |
修复 |
第一步 备份aof文件 第二步 执行VIP_CodisAdmin/bin中的redis-check-aof --fix appendonly.aof 第三步 重启 |
客户端出现大量超时
1)网络原因,联系“连线NOC智能助手”,确认链路网络是否出现拥塞 2)观察视图,查看监听队列是否溢出 全连接队列的大小取决于:min(backlog, somaxconn) ,backlog是在socket创建的时候传入的,somaxconn是一个os级别的系统参数,基于命令ss -lnt,观察监听队列目前的长度是否与预期一致, 调整参数:vim /etc/sysctl.conf net.core.somaxconn=1024 sysctl -p 3)慢查询,slowlogget,确认是否有耗时操作执行,现网默认是10ms slowlog-log-slower-than和slowlog-max-len 其中注意:慢查询不包含请求排队时间,只包含请求执行时间,所以有可能是redis本身排队导致的问题,但通过慢查询可能查不出来 |
fork耗时高
原因 |
1)当Redis做RDB或AOF重写时,一个必不可少的操作就是执行fork操作创建子进程,虽然fork创建的子进程不需要拷贝父进程的物理内存空间,但是会复制父进程的空间内存页表,可以在info stats统计中查latest_fork_usec指标获取最近一次fork操作耗时,单位(微秒)。 |
改善 |
1)优先使用物理机或者高效支持fork操作的虚拟化技术。 2)控制redis单实例的内存大小。fork耗时跟内存量成正比,线上建议每个Redis实例内存控制在10GB以内。 3)适度放宽AOF rewrite触发时机,目前线上配置:auto-aof-rewrite-percentage增长100 % |
子进程开销 监控与优化 |
cpu 不要和其他CPU密集型服务部署在一起,造成CPU过度竞争 如果部署多个Redis实例,尽量保证同一时刻只有一个子进程执行重写工作 1G内存fork时间约20ms |
内存 背景:子进程通过fork操作产生,占用内存大小等同于父进程,理论上需要两倍的内存来完成持久化操作,但Linux有写时复制机制(copy-on-write)。父子进程会共享相同的物理内存页,当父进程处理写请求时会把要修改的页创建副本,而子进程在fork操作过程中共享整个父进程内存快照。 Fork耗费的内存相关日志:AOF rewrite: 53 MB of memory used by copy-on-write,RDB: 5 MB of memory used by copy-on-write 关闭巨页,开启之后,复制页单位从原来4KB变为2MB,增加fork的负担,会拖慢写操作的执行时间,导致大量写操作慢查询 “sudo echo never>/sys/kernel/mm/transparent_hugepage/enabled 硬盘 不要和其他高硬盘负载的服务部署在一起。如:存储服务、消息队列 |
不小心手抖执行了flushdb
如果配置appendonlyno,迅速调大rdb触发参数,然后备份rdb文件,若备份失败,赶紧跑路。配置了appedonlyyes, 办法调大AOF重写参数auto-aof-rewrite-percentage和auto-aof-rewrite-minsize,或者直接kill进程,让Redis不能产生AOF自动重写。·拒绝手动bgrewriteaof。备份aof文件,同时将备份的aof文件中写入的flushdb命令干掉,然后还原。若还原不了,则依赖于冷备。
线上redis想将rdb模式换成aof模式
切不可,直接修改conf,重启
正确方式:备份rdb文件,configset的方式打开aof,同时configrewrite写回配置,执行bgrewriteof,内存数据备份至文件
-End-
阿里中台系列文章:
1.阿里技术总监,讲透技术中台,16页PPT
2.阿里架构总监,讲透中台架构,13页PPT
3.阿里数据科学家,讲透数据中台,15页PPT
4.闲鱼架构专家,详解Flutter技术架构15页ppt
5.京东架构师王新栋:大型开放平台的技术架构
想下载“阿里中台架构”的PPT?第一步,关注“技术领导力”公众号第二步,在对话框输入:中台

想跟文章作者、100位互联网大咖交流学习?
添加助理小姐姐Emma
注明“加群”,稍后她会拉你进社区群

往期精彩推文:
1.男,40,总监,失业,中年人,愿你终能体面的离开
2.90后美女CEO想找个CTO,我给她个技术经理
3.我用了10年,从深圳工厂妹到Google程序媛
4.来做技术总监吧.要写代码吗?不写你来干嘛