【数据结构】查找:哈希表(散列表)——计算式查找法
#笔记整理
查找
- 查找的基本概念
- 静态查找表——基于线性表的查找法(二分查找)
- 动态查找表——基于树表的查找法(二叉排序树、平衡二叉树、B树、红黑树)
- 哈希表——计算式查找法
哈希表——计算式查找法
定义:
哈希法又称散列法、杂凑法或关键字地址计算法等,相应的表称为哈希表或散列表。
方法的基本思想:
在元素的关键字 Key 和元素的存储位置 p 之间建立一个对应关系 H,使得 p = H(Key),H 称为哈希函数(散列函数),是一个压缩映象。
当需要查找关键字为 key 的元素时,利用哈希函数计算出该元素的存储位置 p = H(key),从而达到按关键字直接存取元素的目的。
所以,哈希法既是一种存储方法,也是一种查找方法。
H(Key) 也称为哈希地址(又称散列地址)。把如此构造的表存储结构称为哈希表。
如果忽略发生冲突的情况,哈希法插入和查找元素的算法复杂度仅为 O(1),效率非常高。
哈希函数根据其用途不同会用到各种算法(比如加密技术),有时还会用到启发式计算式。
哈希法中的冲突
当关键字集合很大时,关键字值不同的元素可能会映象到哈希表的同一地址上,即 k1 ≠ k2,但 H(k1) = H(k2),这种现象称为“冲突”,此时称 k1 和 k2 为“同义词”。实际中,冲突是不可避免的, 只能通过改进哈希函数的性能来减少冲突。
综上所述, 哈希法主要包括以下两方面的内容:
(1)如何构造哈希函数;
(2)如何处理冲突。
哈希函数的构造方法
装填因子 α (Load Factor):α = n / m.
n: 表中关键字数;m: 表长。
装填因子代表着哈希表的装满程度。
1. 直接定址法
取关键字或关键字的某个线性函数值为哈希地址。直接定址法的哈希函数 H(key) 为:
H(key) = key 或 H(key) = a * key + b
计算简单,并且不可能有冲突发生。当关键字的分布基本连续时,可用直接定址法的哈希函数;否则,若关键字分布不连续将造成内存单元的大量浪费。
因此该方法需要事先知道关键字的分布情况。
2. 数字分析法
提取关键字中取值较均匀的数字位作为哈希地址的方法。它适合于所有关键字值都已知的情况,并需要对关键字中每一位的取值分布情况进行分析。
H(key) = H(d1 d2 d3 … d7 d8) = d4 d7
即:将关键字的一部分抽取出来,用于计算哈希地址的方法。
如下图的手机号:
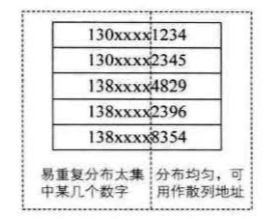
数字分析法通常适合处理关键字的长度比较大的情况,如果事先知道关键字的分布且关键字的若干位分布较均匀,就可以考虑使用该方法。
3. 平方取中法
当无法确定关键字中哪几位分布较均匀时, 可以先求出关键字的平方值,然后按需要取平方值的中间几位作为哈希地址。
实验证明:
一个数字的平方值的中间部分通常对各位数字都比较敏感。故不同关键字会以较高的概率产生不同的哈希地址。
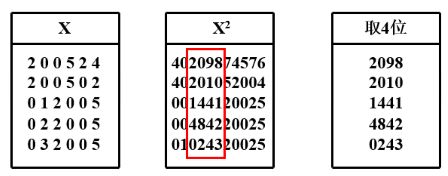
平法取中法比较适合于不知道关键字分布,而位数又不是很大的情况。
4. 折叠法
将关键字分割成位数相同的几部分,然后取这几部分的叠加和。

折叠法事先不需要知道关键字的分布,适合关键字位数较多的情况。
5. 除留余数法
假设哈希表长为 m,则哈希函数为:
H(key) = key % p
p 为不大于 m 的素数或是不含 20 以下的质因子的合数。
设 n 为哈希表中待装入的元素个数,经验表明, p为 1.1n~1.7n 之间的一个素数较好。
本方法的关键在于选择合适的 p,如果 p 选得不好,就可能容易产生同义词。
此方法为最常用的哈希函数构造方法。
6. 伪随机数法
采用一个伪随机函数作哈希函数,计算哈希地址,即:
H(key) = random(key)
当关键字的长度不等时,采用该方法比较合适。
构造方法总结
在实际应用中, 应根据具体情况, 灵活采用不同的方法, 并用实际数据测试它的性能,以便做出正确判定。 通常应考虑以下五个因素:
- 计算哈希函数所需的时间;
- 关键字的长度;
- 哈希表的大小;
- 关键字的分布情况;
- 记录查找的频率。
处理哈希冲突的方法
1. 开放定址法
开放定址法:一旦发生了冲突,就去寻找下一个空的可以插入的哈希地址,只要哈希表足够大,空的哈希地址总能找到,并将记录存入。
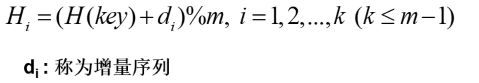
m : 哈希表的大小
根据增量序列的不同,开放定址法还能分为:

其中二次探测法可以双向寻找到可能的空位置,增加平方运算的目的是为了不让关键字都聚集在某一块区域。
2. 再哈希法
当哈希地址发生冲突时,再使用另一种哈希函数构造法,计算另一个哈希函数地址,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
同时构造多个不同的哈希函数:
![]()
RHi 表示不同的哈希函数,每当冲突发生时,就换一个哈希函数进行计算,知道冲突不再产生。
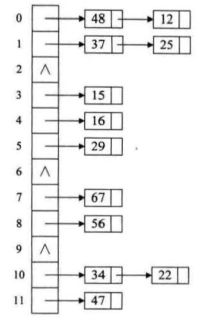
3. 链地址法
将所有同义词存储在一个单链表里,称这种表为同义词子表,在哈希表中只存储所有同义词字表的头指针。
无论多少个冲突,都只是在当前位置给单链表增加结点而已。
该方法对于可能会造成很多冲突的哈希函数而言,提供了绝不会出现找不到地址的保障。
缺点是查找时需要遍历单链表,增加了性能损耗。
4. 公共溢出区法
将哈希表分为基本表和溢出表两部分,凡是与基本表发生冲突的元素一律填入溢出表。
在查找时,对给定值通过哈希函数计算出哈希地址后,先与基本表进行比对,如果有相等的,则查找成功,否则去溢出表进行顺序查找。如果对于基本表而言,有冲突的数据很少,公共溢出区的结构对于查找性能来说还是非常高的。
哈希表的查找及分析
- 由于冲突的存在,哈希法仍需进行关键字比较, 因此仍需用平均查找长度来评价哈希法的查找性能。
- 哈希法中影响关键字比较次数的因素有三个:哈希函数、 处理冲突的方法以及哈希表的装填因子。
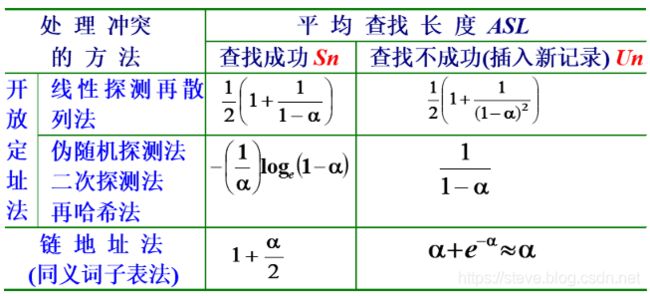
- 哈希表的装填因子 α 表明了表中的装满程度。α 越大,说明表越满,再插入新元素时发生冲突的可能性就越大。
- 哈希的查找性能,即平均查找长度依赖于哈希表的装填因子,不直接依赖于 n 或 m。
- 不论表的长度有多大,总能选择一个合适的装填因子,以把平均查找长度限制在一定范围内。
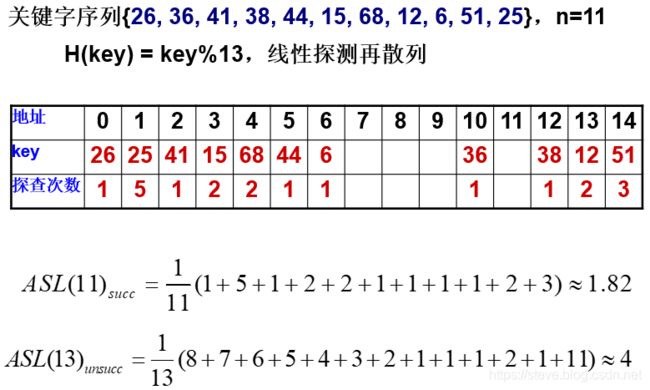
查找分析示例:

总结
哈希表是一种非常高效的查找数据结构,在原理上也与前面的查找不尽相同,它回避了关键字之间反复比较的繁琐,直接一步到位查找结果。当然,这也带来了记录之间没有任何关联的弊端。
所以,哈希表对于那些查找性能要求高,记录之间关系无要求的数据有非常好的适用性。
参考资料:
- 《数据结构(C语言版)》----严蔚敏
- 《数据结构》课堂教学ppt ---- 刘立芳
- 《数据结构算法与解析(STL版)》 ---- 高一凡
- 《大话数据结构》 ---- 程杰
- 《挑战程序设计竞赛2:算法和数据结构》 ---- 渡部有隆