我的第一个爬虫项目---关于知道的爬虫和心得
最近在浏览百度知道的时候,突然间想将百度知道的问题和答案爬取下来,以便分析知道上大家关注的重点是哪些。
文章目录
- python版本
- 运行环境
- 前期准备工作
3.1 抓包工具
3.2 请求库
3.3 解析库 - 大致流程
- 分析网站及主要代码
- 运行结果
- GitHub地址
- 后记
一、python版本
使用的是python 3.6
二、运行环境
MAC OS 10.13
三、前期准备工作
3.1 抓包工具
在对网站进行爬取数据前,需要对其抓包分析,由于我使用的是MAC OS,所以这里我使用的抓包工具是:
Charles(青花瓷)
charles 是一款在Mac端代理服务器,它主要是通过将自己设置成系统(电脑或者浏览器)的网络访问代理服务器,然后截取请求和请求结果达到分析抓包的目的。一般用于Mac,但由于使用java编写,在windows和Linux上也能使用。
Fiddler
Fiddler 是一款在windows平台上使用的http协议调试代理工具,作用与Charles类似,在这里不过多描述
3.2 请求库
在python上最为热门的当属以下几个请求库:
requests库
requests 是python上使用得最多的的第三方HTTP库,它继承了urllib2所有的特性,实际上它最底层也是基于urllib3实现的,但是在用法上简洁与方便。
3.3 解析库
3.3.1 正则表达式
最难上手但同时也是最强大的解析工具。
3.3.2 lxml
支持xml、html的解析和xpath的解析方式,解析效率非常高,需要一定前端的知识。
3.3.3 BeautifulSoup4
beautifulsoup是一个可以从HTML或XML文件中提取数据的Python库,对待一些规范化的网站有着高效的解析速率。
四、大致流程
五、分析网站及主要代码
由于爬取的是百度知道页面,首先通过Charles进行抓包:
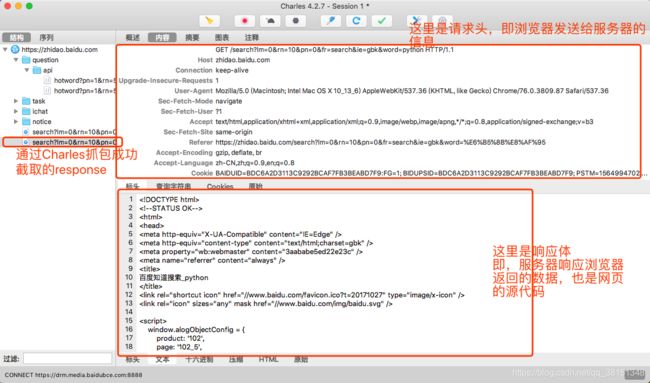
从上面可以看出,浏览器向知道服务器发送了一个请求,这个请求中携带了很多数据,服务器得到请求后,将数据返回给本地浏览器。
关于url组合部分,通过点击翻页跳转,观察url的变化,就能知道浏览器给服务器传了什么参数,再通过组合字符串,拼接url即可
关于请求的部分代码
import requests
# 获取html页面
def get_html(url):
response = requests.get(url)
html = response.text
return html
获得html源码后,通过解析工具进行解析,这里我用的是lxml中的xpath:
from lxml import etree
def parse(html):
content = etree.HTML(html)
content_list = content.xpath("//div/dl")
for link in content_list:
links = link.xpath('./dt/a[@class="ti"]/@href')[0] #提取链接
date = link.xpath('./dd/span[@class="mr-8"]/text()')[0]#提取提问日期
answerer = link.xpath('./dd/span/a[@target="_blank"]/text()')[0]#提取回答者
question = link.xpath('./dt/a/descendant::text()')
question = str(question).replace("'", "").replace(",", "").replace(" ", "")
id_list = re_id.findall(links)[0]
items = {
"question": question,
"links" : links,
"date" : date,
"id" : id_list,
"answer" : answerer
}
return items
return返回数据,最后将数据存入mysql:
import pymysql
def write_insterData(self, items):
#创建connection对象,将数据库连接信息存入
conn = pymysql.connect(host = 'localhost', port = 3306, db = 'python4', user = 'root', passwd = '123456', charset = 'utf8' )
cursors = conn.cursor()
try:
cursors.execute("insert into zhidao_new(id, question, link_list, date_list) VALUE ('%s', '%s', '%s', '%s')"%(items['id'], items['question'], items['links'], items['date']))
print("数据插入成功!!!")
except Exception as e:
print("id重复,继续执行!!")
conn.commit()
cursors.close()
conn.close()
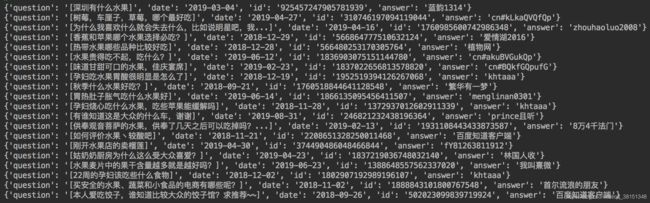
六、运行结果
注:知道页面分为两层,第一层只有问题和部分回答,第二层是问题的详细页面,第二层包含了问题、答案、浏览数、回答数等。由于这里只需要问题的内容,所以我只爬取了知道的第一层。
即:
七、GitHub地址
这个是本项目的GitHub地址,这次用单进程单线程来做的,下次如果学习了多线程,以及后面的协程,会直接在GitHub更新吧?
https://github.com/LiDQuan/zhidao_keyword
八、后记
这个项目是第一次通过自己自学来完成对数据的爬取,当时做这个爬虫的时候对爬虫这个东西也是一知半解,很多地方还有待改进?,现在写这篇文章也算是对自己的一个总结吧,以后会慢慢分享一些自己对爬虫的理解以及一些新的项目。