二十八、电力窃漏电案例模型构建
1. 综合案例模型构建
- 构建窃漏电用户识别模型;
- 构建LM神经网络模型;
- 构建CART决策树模型;
- 模型评价
2. 构建窃漏电用户识别模型
2.1 构建专家样本
专家样本准备完成后,需要划分测试样本和训练样本,随机选取20%作为测试样本,剩下的作为训练样本。
2.3 资源
数据集
-
专家样本数据集的内容包括时间、用户编号、电量趋势下降指标、线损指标、告警类指标和是否窃漏电标签,数据集共有291条样本数据。
数据集详情参考model.xls

工具库
pandas==0.24.2
2.4 步骤
- 导入数据分析库pandas
- 导入随机函数shuffle,用于打乱顺序
- 设置训练数据比例,划分数据
2.5 代码
数据划分实现代码
import pandas as pd #导入数据分析库
from random import shuffle #导入随机函数shuffle,用来打算数据
datafile = '../data/model.xls' #数据名
data = pd.read_excel(datafile) #读取数据,数据的前三列是特征,第四列是标签
data = data.as_matrix() #将表格转换为矩阵
shuffle(data) #随机打乱数据
p = 0.8 #设置训练数据比例
train = data[:int(len(data)*p),:] #前80%为训练集
test = data[int(len(data)*p):,:] #后20%为测试集
3. 构建LM神经网络
3.1 模型搭建
使用Keras库建立神经网络模型。设定LM神经网络有三层模型,输入层为3个节点,隐藏层为10个结点,输出层为1个结点,使用Adam方法求解。
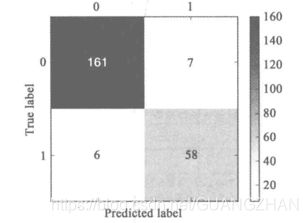
LM神经网络的混淆矩阵
- 通过混淆矩阵可得,模型的分类准确率为(161+58)/(161+58+6+7)=94.4%,正常用户被误判为漏电用户占正常用户对7/(161+7)=4.2%,窃漏电用户被误判为正常用户占窃漏电用户的6/(6+58)=9.4%。
3.2 资源
资源库
pandas==0.24.2
scipy==1.1.0
keras=2.2.0
Tensorflow=1.10
数据集
数据集详情参考model.xls
3.3 步骤
- 导入神经网络初始化函数
- 导入神经网络层函数,激活函数
- 构建模型存储路径
- 建立神经网络
- 编译模型,使用adam方法求解
- 保存模型
- 显示混淆矩阵及可视化结果
3.4 代码
LM神经网络实现代码
#构建LM神经网络模型
from keras.models import Sequential #导入神经网络初始化函数
from keras.layers.core import Dense, Activation #导入神经网络层函数、激活函数
netfile = '../tmp/net.model' #构建的神经网络模型存储路径
net = Sequential() #建立神经网络
net.add(Dense(input_dim = 3, output_dim = 10)) #添加输入层(3节点)到隐藏层(10节点)的连接
net.add(Activation('relu')) #隐藏层使用relu激活函数
net.add(Dense(input_dim = 10, output_dim = 1)) #添加隐藏层(10节点)到输出层(1节点)的连接
net.add(Activation('sigmoid')) #输出层使用sigmoid激活函数
net.compile(loss = 'binary_crossentropy', optimizer = 'adam', class_mode = "binary") #编译模型,使用adam方法求解
net.fit(train[:,:3], train[:,3], nb_epoch=1000, batch_size=1) #训练模型,循环1000次
net.save_weights(netfile) #保存模型
predict_result = net.predict_classes(train[:,:3]).reshape(len(train)) #预测结果变形
4 构建CART决策树模型
4.1 使用sklearn机器学习库构建决策树模型
通过scikit-learn利用训练样本构建CART决策树模型,得到的混淆矩阵如下图所示,分类准确率为(160+56)/(160+56+3+13)=93.1%,正常用户被误判为窃漏电用户占正常用户的 13/(13+160)=7.5%,窃漏电用户被误判为正常用户占窃漏电用户的3/(3+56)=5.1%。
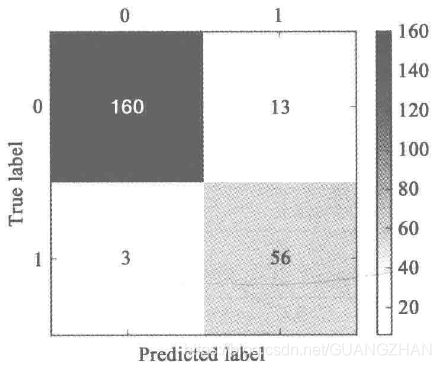
4. 2代码
决策树构建窃漏电用户识别代码
#构建CART决策树模型
from sklearn.tree import DecisionTreeClassifier #导入决策树模型
treefile = '../tmp/tree.pkl' #模型输出名字
tree = DecisionTreeClassifier() #建立决策树模型
tree.fit(train[:,:3], train[:,3]) #训练
#保存模型
from sklearn.externals import joblib
joblib.dump(tree, treefile)
from cm_plot import * #导入自行编写的混淆矩阵可视化函数
cm_plot(train[:,3], tree.predict(train[:,:3])).show() #显示混淆矩阵可视化结果
#注意到Scikit-Learn使用predict方法直接给出预测结果。
5 综合案例模型评价
5.1 使用测试数据
对于训练样本,LM神经网络和CART决策树的分类准确相差不大,分别为94%和93%,为了进一步评估模型分类的性能,故利用测试样本对两个模型进行评价,采用ROC曲线评价方法进行评估。
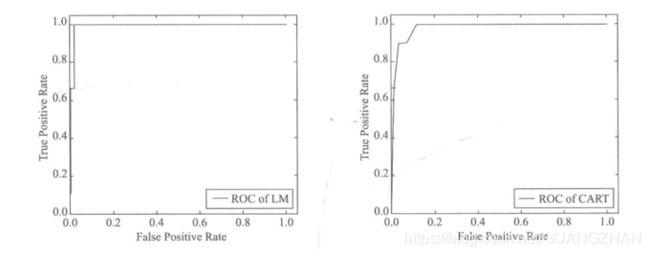
6 完成代码
6.1 Cart决策树模型
#-*- coding: utf-8 -*-
#构建并测试CART决策树模型
import pandas as pd #导入数据分析库
from random import shuffle #导入随机函数shuffle,用来打算数据
datafile = '../data/model.xls' #数据名
data = pd.read_excel(datafile) #读取数据,数据的前三列是特征,第四列是标签
data = data.as_matrix() #将表格转换为矩阵
shuffle(data) #随机打乱数据
p = 0.8 #设置训练数据比例
train = data[:int(len(data)*p),:] #前80%为训练集
test = data[int(len(data)*p):,:] #后20%为测试集
#构建CART决策树模型
from sklearn.tree import DecisionTreeClassifier #导入决策树模型
treefile = '../tmp/tree.pkl' #模型输出名字
tree = DecisionTreeClassifier() #建立决策树模型
tree.fit(train[:,:3], train[:,3]) #训练
#保存模型
from sklearn.externals import joblib
joblib.dump(tree, treefile)
from cm_plot import * #导入自行编写的混淆矩阵可视化函数
cm_plot(train[:,3], tree.predict(train[:,:3])).show() #显示混淆矩阵可视化结果
#注意到Scikit-Learn使用predict方法直接给出预测结果。
from sklearn.metrics import roc_curve #导入ROC曲线函数
fpr, tpr, thresholds = roc_curve(test[:,3], tree.predict_proba(test[:,:3])[:,1], pos_label=1)
plt.plot(fpr, tpr, linewidth=2, label = 'ROC of CART', color = 'green') #作出ROC曲线
plt.xlabel('False Positive Rate') #坐标轴标签
plt.ylabel('True Positive Rate') #坐标轴标签
plt.ylim(0,1.05) #边界范围
plt.xlim(0,1.05) #边界范围
plt.legend(loc=4) #图例
plt.show() #显示作图结果
6.2 LM神经网络模型
#-*- coding: utf-8 -*-
import pandas as pd
from random import shuffle
datafile = '../data/model.xls'
data = pd.read_excel(datafile)
data = data.as_matrix()
shuffle(data)
p = 0.8 #设置训练数据比例
train = data[:int(len(data)*p),:]
test = data[int(len(data)*p):,:]
#构建LM神经网络模型
from keras.models import Sequential #导入神经网络初始化函数
from keras.layers.core import Dense, Activation #导入神经网络层函数、激活函数
netfile = '../tmp/net.model' #构建的神经网络模型存储路径
net = Sequential() #建立神经网络
net.add(Dense(input_dim = 3, output_dim = 10)) #添加输入层(3节点)到隐藏层(10节点)的连接
net.add(Activation('relu')) #隐藏层使用relu激活函数
net.add(Dense(input_dim = 10, output_dim = 1)) #添加隐藏层(10节点)到输出层(1节点)的连接
net.add(Activation('sigmoid')) #输出层使用sigmoid激活函数
net.compile(loss = 'binary_crossentropy', optimizer = 'adam', class_mode = "binary") #编译模型,使用adam方法求解
net.fit(train[:,:3], train[:,3], nb_epoch=1000, batch_size=1) #训练模型,循环1000次
net.save_weights(netfile) #保存模型
predict_result = net.predict_classes(train[:,:3]).reshape(len(train)) #预测结果变形
'''这里要提醒的是,keras用predict给出预测概率,predict_classes才是给出预测类别,而且两者的预测结果都是n x 1维数组,而不是通常的 1 x n'''
from cm_plot import * #导入自行编写的混淆矩阵可视化函数
cm_plot(train[:,3], predict_result).show() #显示混淆矩阵可视化结果
from sklearn.metrics import roc_curve #导入ROC曲线函数
predict_result = net.predict(test[:,:3]).reshape(len(test))
fpr, tpr, thresholds = roc_curve(test[:,3], predict_result, pos_label=1)
plt.plot(fpr, tpr, linewidth=2, label = 'ROC of LM') #作出ROC曲线
plt.xlabel('False Positive Rate') #坐标轴标签
plt.ylabel('True Positive Rate') #坐标轴标签
plt.ylim(0,1.05) #边界范围
plt.xlim(0,1.05) #边界范围
plt.legend(loc=4) #图例
plt.show() #显示作图结果
6.3 混淆矩阵代码
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix #导入混淆矩阵函数
cm = confusion_matrix(y, yp) #混淆矩阵
import matplotlib.pyplot as plt #导入作图库
plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。
plt.colorbar() #颜色标签
for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
return plt
for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
return plt