(2)ElasticSearch--rest api 进行客户端操作
一、Elasticsearch核心概念
Elasticsearch比传统关系型数据库如下:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
1. 索引 index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
2. 类型 type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
3. 字段Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
4. 映射 mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
5. 文档 document
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
二、ElasticSearch客户端操作
1. ElasticSearch的接口语法
curl -X '://:/?' -d ''
其中:
| 参数 | 解释 |
|---|---|
VERB |
适当的 HTTP 方法 或 谓词 : GET、 POST、 PUT、 HEAD 或者 DELETE。 |
PROTOCOL |
http 或者 https(如果你在 Elasticsearch 前面有一个 https 代理) |
HOST |
Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点。 |
PORT |
运行 Elasticsearch HTTP 服务的端口号,默认是 9200 。 |
PATH |
API 的终端路径(例如 _count 将返回集群中文档数量)。Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvm 。 |
QUERY_STRING |
任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读) |
BODY |
一个 JSON 格式的请求体 (如果请求需要的话) |
2. RESTFul API 操作es
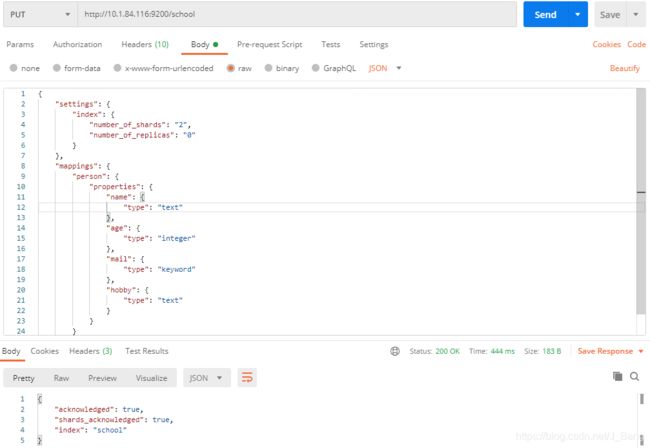
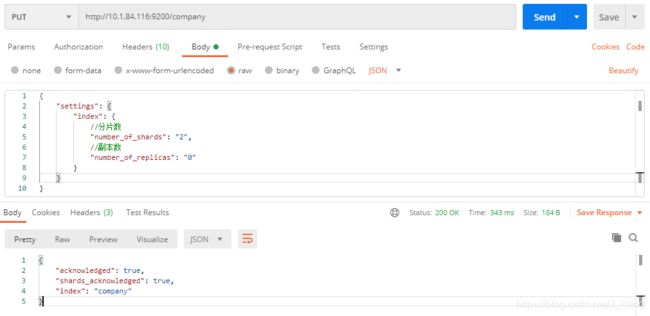
2.1创建索引
URL规则:PUT /{索引}
// 创建空索引
PUT /company
{
"settings": {
"index": {
//分片数
"number_of_shards": "2",
//副本数
"number_of_replicas": "0"
}
}
}
2.2 删除索引
URL规则:DELETE /{索引}
//删除索引
DELETE /company

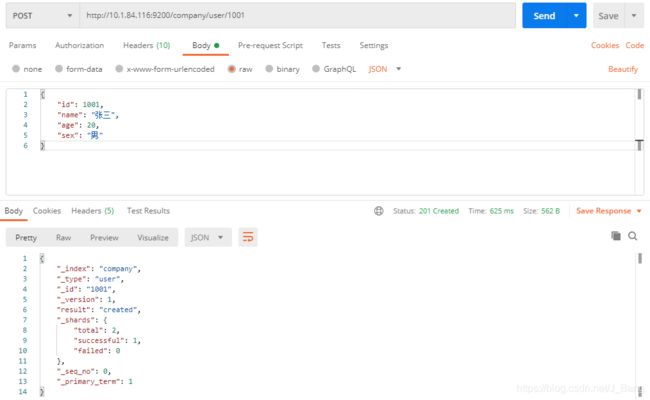
2.3 插入数据
URL规则:POST /{索引}/{类型}/{id}
POST /company/user/1001
//数据
{
"id": 1001,
"name": "张三",
"age": 20,
"sex": "男"
}
2.4 修改数据
URL规则:PUT /{索引}/{类型}/{id}
(1)整体更新


(2)局部更新
#注意:这里多了_update标识
POST /company/user/1001/_update
{
"doc":{
"age":23
}
}


2.5 删除数据
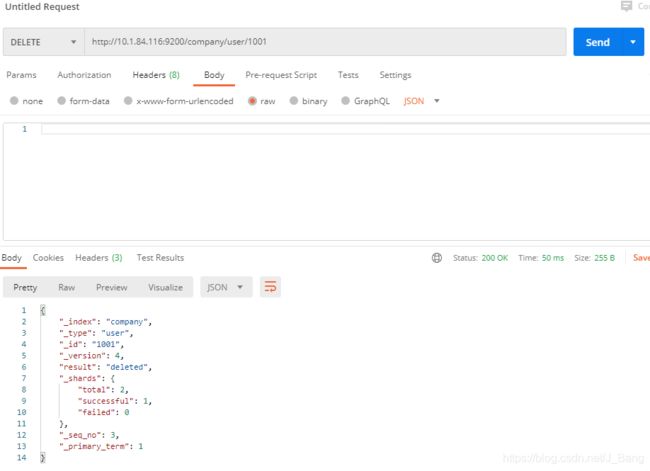
URL规则:DELETE /{索引}/{类型}/{id}
DELETE /company/user/1001

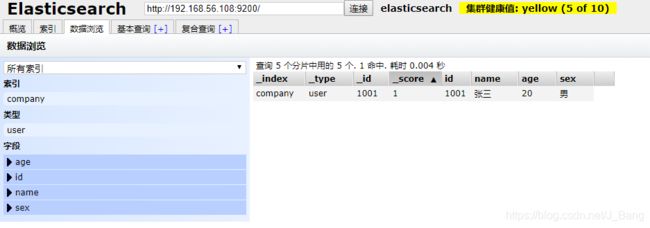
2.6 搜索数据
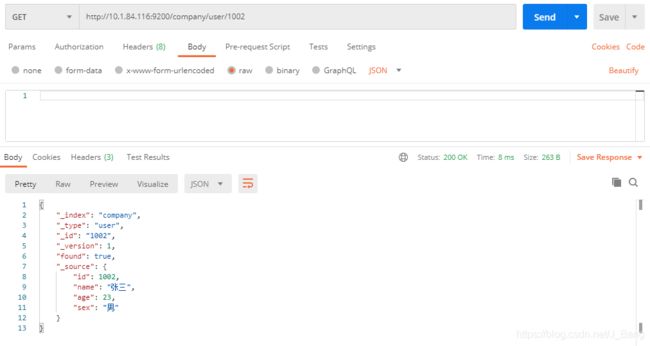
URL规则:GET /{索引}/{类型}/{id}
(1)查询单条数据
GET /company/user/1002
(2)查询所有数据
GET /company/user/_search

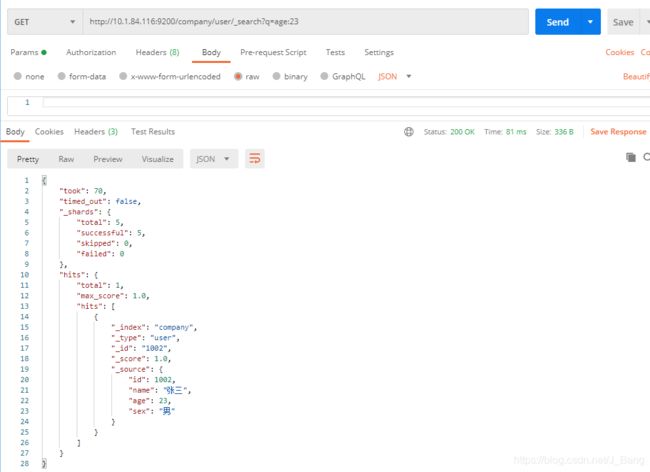
(2)关键词搜索
//查询年龄等于23的用户
GET /company/user/_search?q=age:23
2.7 DSL搜索
Elasticsearch提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。
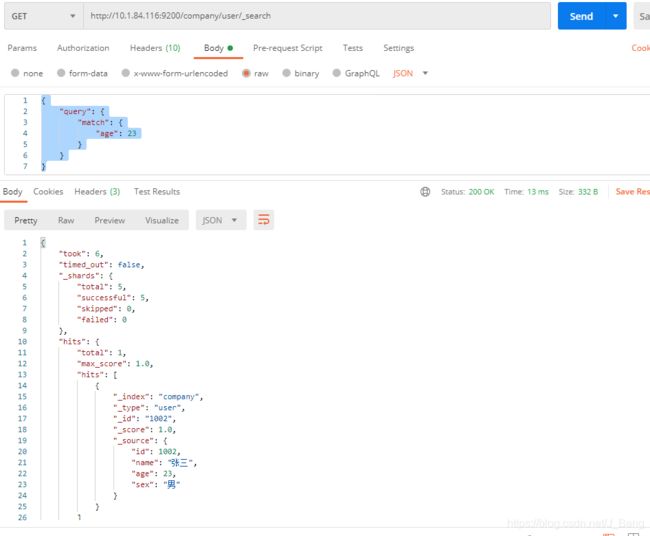
POST /company/user/_search
//年龄为23
{
"query": {
"match": {
"age": 23
}
}
}
//查询年龄大于30岁的男性用户。
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"gt": 30
}
}
},
"must": {
"match": {
"sex": "男"
}
}
}
}
}
//姓名为张三或李四
{
"query": {
"match": {
"name": "张三 李四"
}
}
}
2.8 高亮查询
{
"query": {
"match": {
"name": "李四"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}

2.9 聚合
在es中,支持聚合操作,类似SQL中的group by操作。
{
"aggs": {
"all_interests": {
"terms": {
"field": "age"
}
}
}
}

2.10 分页
GET /_search?size=5
GET /_search?size=5&from=5
GET /_search?size=5&from=10
2.11 映射
创建的索引以及插入数据,有些时候我们是需要进行明确字段类型的,否则,自动判断的类型和实际需求是不相符的。
(1)自动判断规则
| json type | field type |
|---|---|
| Boolean: true or false | “boolean” |
| Whole number: 123 | “long” |
| Floating point: 123.45 | “double” |
| String, valid date: “2014-09-15” | “date” |
| String: “foo bar” | “long” |
| Whole number: 123 | “string” |
(2)es中支持的类型
| 类型 | 表示的数据 |
|---|---|
| String | string , text , keyword |
| Boolean | boolean |
| Whole number | byte , short , integer , long |
| Floating point | float , double |
| Date | date |
(3)创建明确类型的索引