数据库mysql 主从方案
双机热备的概念简单说一下,就是要保持两个数据库的状态自动同步。对任何一个数据库的操作都自动应用到另外一个数据库,始终保持两个数据库数据一致。 这样做的好处多。 1. 可以做灾备,其中一个坏了可以切换到另一个。 2. 可以做负载均衡,可以将请求分摊到其中任何一台上,提高网站吞吐量。 对于异地热备,尤其适合灾备。废话不多说了。我们直接进入主题。 我们会主要介绍两部分内容:
一, MySQL 备份工作原理
二, 备份实战
我们开始。
我使用的是mysql 5.5.34,

一, mysql 备份工作原理
简单的说就是把 一个服务器上执行过的sql语句在别的服务器上也重复执行一遍, 这样只要两个数据库的初态是一样的,那么它们就能一直同步。
当然这种复制和重复都是mysql自动实现的,我们只需要配置即可。
我们进一步详细介绍原理的细节, 这有一张图:
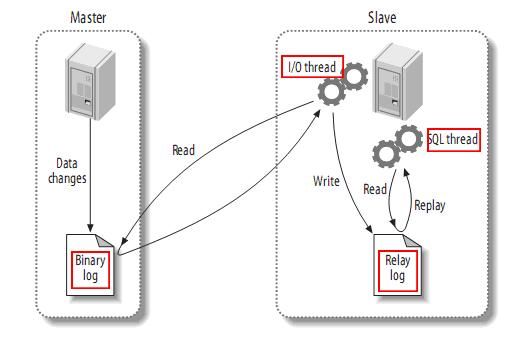
上图中有两个服务器, 演示了从一个主服务器(master) 把数据同步到从服务器(slave)的过程。
这是一个主-从复制的例子。 主-主互相复制只是把上面的例子反过来再做一遍。 所以我们以这个例子介绍原理。
对于一个mysql服务器, 一般有两个线程来负责复制和被复制。当开启复制之后。
1. 作为主服务器Master, 会把自己的每一次改动都记录到 二进制日志 Binarylog 中。 (从服务器会负责来读取这个log, 然后在自己那里再执行一遍。)
2. 作为从服务器Slave, 会用master上的账号登陆到 master上, 读取master的Binarylog, 写入到自己的中继日志 Relaylog, 然后自己的sql线程会负责读取这个中继日志,并执行一遍。 到这里主服务器上的更改就同步到从服务器上了。
在mysql上可以查看当前服务器的主,从状态。 其实就是当前服务器的 Binary(作为主服务器角色)状态和位置。 以及其RelayLog(作为从服务器)的复制进度。
例如我们在主服务器上查看主状态:

mysql> show master status\G
*************************** 1. row ***************************
File: mysql-bin.000014
Position: 107
Binlog_Do_DB:
Binlog_Ignore_DB: mysql,information_schema,performance_schema,amh
1 row in set (0.00 sec)稍微解释一下这几行的意思:
1. 第一行表明 当前正在记录的 binarylog文件名是: mysql-bin.000014.
我们可以在mysql数据目录下,找到这个文件:

2. 第二行, 107. 表示当前的文件偏移量, 就是写入在mysql-bin.000014 文件的记录位置。
这两点就构成了 主服务器的状态。 配置从服务器的时候,需要用到这两个值。 告诉从服务器从哪读取主服务器的数据。 (从服务器会登录之后,找到这个日志文件,并从这个偏移量之后开始复制。)
3. 第三行,和第四行,表示需要记录的数据库和需要忽略的数据库。 只有需要记录的数据库,其变化才会被写入到mysql-bin.000014日志文件中。 后面会再次介绍这两个参数。
我们还可以在从服务器上,查看从服务器的复制状态。

1: mysql> show slave status\G
2: *************************** 1. row ***************************
3: Slave_IO_State: Waiting for master to send event
4: Master_Host: 198.**.***.***
5: Master_User: r*******
6: Master_Port: 3306
7: Connect_Retry: 60
8: Master_Log_File: mysql-bin.000014
9: Read_Master_Log_Pos: 107
10: Relay_Log_File: mysqld-relay-bin.000013
11: Relay_Log_Pos: 253
12: Relay_Master_Log_File: mysql-bin.000014
13: Slave_IO_Running: Yes
14: Slave_SQL_Running: Yes
15: Replicate_Do_DB:
16: Replicate_Ignore_DB: mysql,information_schema,amh,performance_schema
17: Replicate_Do_Table:
18: Replicate_Ignore_Table:
19: Replicate_Wild_Do_Table:
20: Replicate_Wild_Ignore_Table:
21: Last_Errno: 0
22: Last_Error:
23: Skip_Counter: 0
24: Exec_Master_Log_Pos: 107
25: Relay_Log_Space: 556
26: Until_Condition: None
27: Until_Log_File:
28: Until_Log_Pos: 0
29: Master_SSL_Allowed: No
我们还是来重点解释途中的红圈的部分:
1. Master_host 指的是 主服务器的地址。
2. Master_user 指的是主服务器上用来复制的用户。 从服务器会用此账号来登录主服务。进行复制。
3. Master_log_file 就是前面提到的, 主服务器上的日志文件名.
4. Read_Master_log_pos 就是前面提到的主服务器的日志记录位置, 从服务器根据这两个条件来选择复制的文件和位置。
5. Slave_IO_Running: 指的就是从服务器上负责读取主服务器的线程工作状态。 从服务器用这个专门的线程链接到主服务器上,并把日志拷贝回来。
6. Slave_SQL_Running: 指的就是专门执行sql的线程。 它负责把复制回来的Relaylog执行到自己的数据库中。 这两个参数必须都为Yes 才表明复制在正常工作。
其他的参数之后再介绍。
二, mysql 双机热备实战
了解了上面的原理之后, 我们来实战。 这里有两个重点, 要想同步数据库状态, 需要相同的初态,然后配置同步才有意义。 当然你可以不要初态,这是你的自由。 我们这里从头开始配置一遍。

我们先以A服务器为起点, 配置它的数据库同步到B。 这就是主-从复制了。 之后再反过来做一次,就可以互相备份了。
1, 第一步,
在A上面创建专门用于备份的 用户:

grant replication slave on *.* to 'repl_user'@'192.***.***.***' identified by 'hj34$%&mnkb';
上面把ip地址换成B机器的ip地址。 只允许B登录。安全。
用户名为: repl_user
密码为: hj34$********nkb
这个等会在B上面要用。
2. 开启主服务器的 binarylog。
很多服务器是默认开启的,我们这里检查一下:
打开 /etc/my.cnf

我来解释一下红框中的配置:
前面三行, 你可能已经有了。
binlog-do-db 用来表示,只把哪些数据库的改动记录到binary日志中。 可以写上关注hello数据库。 但是我把它注释掉了。 只是展示一下。 可以写多行,表示关注多个数据库。
binlog-ignore-db 表示,需要忽略哪些数据库。我这里忽略了其他的4个数据库。
后面两个用于在 双主(多主循环)互相备份。 因为每台数据库服务器都可能在同一个表中插入数据,如果表有一个自动增长的主键,那么就会在多服务器上出现主键冲突。 解决这个问题的办法就是让每个数据库的自增主键不连续。 上图说是, 我假设需要将来可能需要10台服务器做备份, 所以auto-increment-increment 设为10. 而 auto-increment-offset=1 表示这台服务器的序号。 从1开始, 不超过auto-increment-increment。
这样做之后, 我在这台服务器上插入的第一个id就是 1, 第二行的id就是 11了, 而不是2.
(同理,在第二台服务器上插入的第一个id就是2, 第二行就是12, 这个后面再介绍) 这样就不会出现主键冲突了。 后面我们会演示这个id的效果。
3. 获取主服务器状态, 和同步初态。
假设我现在有这些数据库在A上面。
如果你是全新安装的, 那么不需要同步初态,直接跳过这一步,到后面直接查看主服务器状态。
这里我们假设有一个 hello 数据库作为初态。

先锁定 hello数据库:
FLUSH TABLES WITH READ LOCK; 
然后导出数据:
我这里只需要导出hello数据库, 如果你有多个数据库作为初态的话, 需要导出所有这些数据库:

然后查看A服务器的binary日志位置:
记住这个文件名和 位置, 等会在从服务器上会用到。

主服务器已经做完了, 可以解除锁定了:

4. 设置从服务器 B 需要复制的数据库
打开从服务器 B 的 /etc/my.cnf 文件:

解释一下上面的内容。
server-id 必须保证每个服务器不一样。 这可能和循环同步有关。 防止进入死循环。
replicate-do-db 可以指定需要复制的数据库, 我这里注掉了。 演示一下。
replicate-ignore-db 复制时需要排除的数据库, 我使用了,这个。 除开系统的几个数据库之外,所有的数据库都复制。
relay_log 中继日志的名字。 前面说到了, 复制线程需要先把远程的变化拷贝到这个中继日志中, 在执行。
log-slave-updates 意思是,中继日志执行之后,这些变化是否需要计入自己的binarylog。 当你的B服务器需要作为另外一个服务器的主服务器的时候需要打开。 就是双主互相备份,或者多主循环备份。 我们这里需要, 所以打开。
保存, 重启mysql。
5. 导入初态, 开始同步。
把刚才从A服务器上导出的 hello.sql 导入到 B的hello数据库中, 如果B现在没有hello数据库,请先创建一个, 然后再导入:
创建数据库:
mysql> create database hello default charset utf8;把hello.sql 上传到B上, 然后导入:

如果你刚才导出了多个数据库, 需要把他们都一一上传导入。
开启同步, 在B服务器上执行:
CHANGE MASTER TO
MASTER_HOST='192.***.***.***',
MASTER_USER='repl_user',
MASTER_PASSWORD='hj3****',
MASTER_LOG_FILE='mysql-bin.000004',
MASTER_LOG_POS=7145; 
上面几个参数我就不解释了。 前面说过了。
重启mysql, 然后查看slave线程开启了没:

注意图中的红框, 两个都是Yes, 说明开启成功。
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
如果其中一个是No, 那就说明不成功。需要查看mysql的错误日志。 我在第一次做的时候就遇到这个问题。有时候密码填错了, 有时候防火墙的3306没有打开。ip地址不对,等等。 都会导致失败。
我们看错误日志: mysql的错误日志一般在:

文件名应该是你的机器名, 我这里叫做host1.err 你换成你自己的。
到这里主-从复制已经打开了。 我们先来实验一下。
我们在A的数据库里面去 添加数据:

我在A的 hello数据库的test表中 连续插入了3条数据, 注意看他们的自增长id, 分别是1,11,21. 知道这是为什么吗。 前面已经说过了,不懂再回去看。
我们去看一下B数据库有没有这三条数据:
打开B的数据库:

发现已经在这了。 这里效果不直观。
此时不要在B中修改数据。 我们接着配置从B到A的复制。 如果你只需要主从复制的话, 到这里就结束了。后面可以不看了。 所有A中的修改都能自动同步到B, 但是对B的修改却不能同步到A。 因为是单向的。 如果需要双向同步的话,需要再做一次从B到A的复制。
基本跟上面一样:我们简单一点介绍:
1. 在B中创建用户;
2. 打开 /etc/my.cnf , 开启B的binarylog:

注意红框中所新添加的部分。
3. 我们不需要导出B的初态了,因为它刚刚才从A导过来。 直接记住它的master日志状态:

记住这两个数值,等会在A上面要用。
B服务器就设置完了。
4. 登录到A 服务器。 开启中继:

注意框中心添加的部分, 不解释了。
5. 启动同步:

上面的ip地址是B的ip地址, 因为A把B当做master了。 不解释了。
然后重启mysql服务。
然后查看,slave状态是否正常:

图中出现了两个No。
Slave_IO_Running: No
Slave_SQL_Running: No
说明slave没有成功, 即,从B到A的同步没有成功。 我们去查看mysql错误日志,前面说过位置:

找到 机器名.err 文件,打开看看:

看图中的error信息。 说找不到中继日志文件。
这是因为我们在配置A的中继文件时改了中继文件名,但是mysql没有同步。解决办法很简单。

先停掉mysql服务。 找到这三个文件,把他们删掉。 一定要先停掉mysql服务。不然还是不成功。你需要重启一下机器了。 或者手动kill mysqld。
好了, 启动mysql之后。 我们在来检查一下slave状态:

注意图中两个大大的Yes。 哈哈。
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
证明从B到A的复制也成功了。
此时我们去B服务器中插入几条数据试试:

我在B中插入了两条数据。 注意看他们的id。 不解释。
然后我们,登录去A中看看,A数据库变了没。

可以看到已经自动同步到A了。
至此, AB双主互相热备就介绍完了。
主从Master/Slave维护命令:
master端:
show master status;—查看状态:
show processlist; –查看slave下MySQL进程信息
reset master; #慎用,将清空日志及同步position
slave端:
CHANGE MASTER TO MASTER_LOG_FILE=’master.000019′;
show slave status;
show slave logs;
show processlist;
reset slave; #慎用,将清空slave配置信息、日志及同步position
在从服务器上跳过错误事件
mysql>stop slave;
mysql>set global sql_slave_skip_counter = n(跳过主服务器中的接下来的 n 个事件。此命令对于由语句引起的复制终止有效。仅在从服务器线程没运行的时候有效);
mysql>start slave;
mysql 主服务器中同步用户 必须具有 SUPER ,RELOAD,REPLICATION SLAVE 权限
当新加从服务器时,需要先在从库上 load data master; 保证和其他从库数据一致
set global sql_slave_skip_counter=n # 客户端运行,用来跳过几个事件,只有当同步进程出现错误而停止的时候才可以执行。
reset master #主机端运行,清除所有的日志,这条命令就是原来的flush master
reset slave #从机运行,清除日志同步位置标志,并重新生成master.info
虽然重新生成了master.info,但是并不起用,最好,将从机的mysql进程重启一下,
load table tblname from master
#从机运行,从主机端重读指定的表的数据,每次只能读取一个,受timeout时间限制,需要调整timeout时间。执行这个命令需要同步账号有reload和super权限。以及对相应的库有select权限。如果表比较大,要增加net_read_timeout 和 net_write_timeout的值
load data from master #从机执行,从主机端重新读入所有的数据。执行这个命令需要同步账号有reload和super权限。以及对相应的库有select权限。如果表比较大,要增加net_read_timeout 和 net_write_timeout的值
change master to master_def_list #在线改变一些主机设置,多个用逗号间隔,比如
change master to
master_host=’master2.mycompany.com’,
master_user=’replication’,
master_password=’bigs3cret’
master_pos_wait() #从机运行
show master status #主机运行,看日志导出信息
show slave hosts #主机运行,看连入的从机的情况。
show slave status (slave)
show master logs (master)
show binlog events [ in 'logname' ] [ from pos ] [ limit [offset,] rows ]
purge [master] logs to ‘logname’ ; purge [master] logs before ‘date’
//显示所有本机上的二进制日志
mysql> SHOW MASTER LOGS;
//删除所有本机上的二进制日志
mysql> RESET MASTER;
//删除所有创建时间在binary-log.xxx之前的二进制日志
mysql> PURGE MASTER LOGS TO ‘binary-log.xxx’;
//只保留最近6天的日志,之前的都删掉
find /var/intra -type f -mtime +6 -name “*.log” -exec rm -f {} \;
//用键盘左上角(也就是Esc下面)那个键包围起来,说明是命令。-1d是昨天,以此类推-1m是上个月等等
day=`/bin/date -v -1d +%Y%m%d`;
//给文件改名
mv xxx.log xxx-${day}.log;
//这里还要加上数据库的用户名密码,作用是更新日志(包括二进制日志和查询日志等等)
mysqladmin flush-logs
show processlist;查看进程
kill proId;杀掉进程
参考:
1. mysql-keepalived-实现双主热备读写分离
http://gitsea.com/2013/06/16/mysql-keepalived-%E5%AE%9E%E7%8E%B0%E5%8F%8C%E4%B8%BB%E7%83%AD%E5%A4%87%E8%AF%BB%E5%86%99%E5%88%86%E7%A6%BB/
2. MySQL数据同步【双主热备】http://www.cnblogs.com/zhongweiv/archive/2013/02/01/mysql_replication_circular.html
3. Mysql双机热备实现
http://yunnick.iteye.com/blog/1845301
4. 高性能Mysql主从架构的复制原理及配置详解http://blog.csdn.net/hguisu/article/details/7325124
5. mysql 基于 master-master 的双机热备配置