Hadoop之MapReduce程序的3种集群提交运行模式详解
1.MapReduce程序的集群运行模式1
MapReduce程序的集群运行模式1—将工程打成jar包,上传到服务器,然后用hadoop命令hadoop jar xxx.jar 将jar包分发到集群中运行。
wordcount代码:
package MapReduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class WordCount
{
public static String path1 = "hdfs://hadoop20:9000/word.txt";//读取HDFS中的数据
public static String path2 = "hdfs://hadoop20:9000/dir1/";//数据输出到HDFS中
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = Job.getInstance(conf,"wordcount");
job.setJarByClass(WordCount.class);
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setNumReduceTasks(1);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
job.waitForCompletion(true);
}
public static class MyMapper extends Mapper
{
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
String[] splited = v1.toString().split("\t");
for (String string : splited)
{
context.write(new Text(string),new LongWritable(1L));
}
}
}
public static class MyReducer extends Reducer
{
protected void reduce(Text k2, Iterable v2s,Context context)throws IOException, InterruptedException
{
long sum = 0L;
for (LongWritable v2 : v2s)
{
sum += v2.get();
}
context.write(k2,new LongWritable(sum));
}
}
} 打成jar包后在集群中运行:
[root@hadoop20 local]# hadoop jar wordcount.jar查看运行结果:
[root@hadoop20 local]# hadoop fs -cat /dir/part-r-00000
hello 2
me 1
you 12. MapReduce程序的集群运行模式2
MapReduce程序的集群运行模式2—在linux的eclipse中直接运行main方法,进而将程序提交到集群中去运行,但是必须采取以下措施:
①在工程src目录下加入 mapred-site.xml 和 yarn-site.xml 这两个配置文件或者在代码中加入: Configuration conf = new Configuration();
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.hostname", "hadoop20");② 同时将工程打成jar包(xxx.jar),并在main方法中添加一个conf的配置参数 conf.set(“mapreduce.job.jar”,”路径/xxx.jar”);
还是以WordCount程序为例:
先导出个jar包: 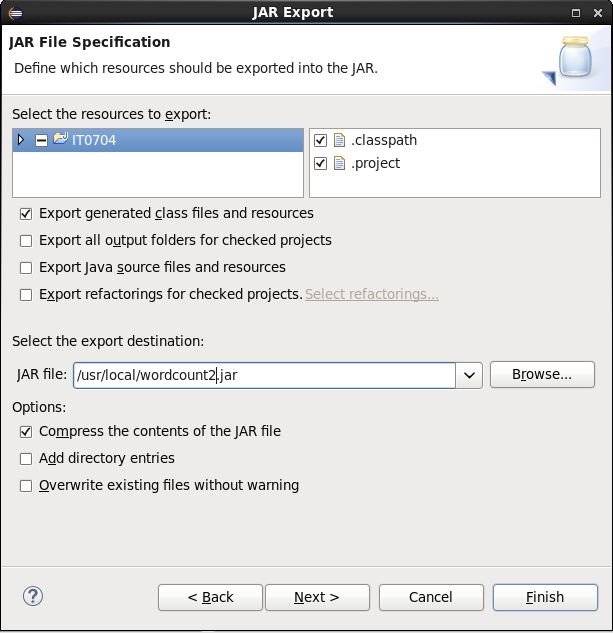
查看jar包:
[root@hadoop20 local]# ll
total 415748
drwxrwxr-x. 8 root root 4096 Jul 5 01:22 eclipse
-rw-r--r--. 1 root root 262311443 Jul 3 06:26 eclipse-committers-neon-R-linux-gtk.tar.gz
drwxr-xr-x. 11 67974 users 4096 Jul 1 01:47 hadoop
-rw-r--r--. 1 root root 3620 Jul 2 05:55 hadoop-env.cmd
drwxr-xr-x. 8 uucp 143 4096 Jun 16 2014 jdk
-rw-r--r--. 1 root root 159958812 Jul 3 19:17 jdk-8u11-linux-i586.tar.gz
-rw-r--r--. 1 root root 3400818 Apr 7 05:28 Skin_NonSkin.txt
-rw-r--r--. 1 root root 6573 Jul 5 01:33 wc.jar
-rw-r--r--. 1 root root 5230 Jul 5 05:31 wordcount2.jar //这是导出的jar包wordcount2.jar
-rw-r--r--. 1 root root 5106 Jul 5 04:56 wordcount.jar
-rw-r--r--. 1 root root 19 Jun 24 00:15 word.txt
[root@hadoop20 local]# pwd
/usr/local接下来在linux的eclipse代码中添加配置文件:
package MapReduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class WordCount
{
public static String path1 = "hdfs://hadoop20:9000/word.txt";//读取HDFS中的数据
public static String path2 = "hdfs://hadoop20:9000/dir2/";//数据输出到HDFS中
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
conf.set("mapreduce.job.jar","/usr/local/wordcount2.jar"); //change
conf.set("fs.defaultFS", "hdfs://hadoop20:9000/"); //change
conf.set("mapreduce.framework.name", "yarn"); //change
conf.set("yarn.resourcemanager.hostname", "hadoop20"); //change
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = Job.getInstance(conf,"wordcount");
job.setJarByClass(WordCount.class);
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setNumReduceTasks(1);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
job.waitForCompletion(true);
}
public static class MyMapper extends Mapper
{
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
String[] splited = v1.toString().split("\t");
for (String string : splited)
{
context.write(new Text(string),new LongWritable(1L));
}
}
}
public static class MyReducer extends Reducer
{
protected void reduce(Text k2, Iterable v2s,Context context)throws IOException, InterruptedException
{
long sum = 0L;
for (LongWritable v2 : v2s)
{
sum += v2.get();
}
context.write(k2,new LongWritable(sum));
}
}
} 接下来我们通过shell命令查看运行结果:
[root@hadoop20 local]# hadoop fs -cat /dir2/part-r-00000
hello 2
me 1
you 13. MapReduce程序的集群运行模式3
MapReduce程序的集群运行模式3—在windows的eclipse中直接运行main方法,进而将程序提交给集群运行,但是因为平台不兼容,需要做很多的设置修改:
①要在windows中存放一份hadoop的安装包(解压好的)
②要将其中的lib和bin目录替换成根据你的windows版本重新编译出的文件(lib和bin都是和本地平台相关的东西)
③再要配置系统环境变量 HADOOP_HOME 和 PATH
④修改YarnRunner这个类的源码
4. MR程序的几种提交运行模式的具体指令
1/在windows的eclipse里面直接运行main方法,就会将job提交给本地执行器localjobrunner执行
----输入输出数据可以放在本地路径下(c:/wc/srcdata/)
----输入输出数据也可以放在hdfs中(hdfs://weekend110:9000/wc/srcdata)
2/在linux的eclipse里面直接运行main方法,但是不要添加yarn相关的配置,也会提交给localjobrunner执行
----输入输出数据可以放在本地路径下(/home/hadoop/wc/srcdata/)
----输入输出数据也可以放在hdfs中(hdfs://weekend110:9000/wc/srcdata)
集群模式运行
1/将工程打成jar包,上传到服务器,然后用hadoop命令提交 hadoop jar wc.jar cn.itcast.hadoop.mr.wordcount.WCRunner
2/在linux的eclipse中直接运行main方法,也可以提交到集群中去运行,但是,必须采取以下措施:
----在工程src目录下加入 mapred-site.xml 和 yarn-site.xml
----将工程打成jar包(wc.jar),同时在main方法中添加一个conf的配置参数 conf.set("mapreduce.job.jar","wc.jar");
3/在windows的eclipse中直接运行main方法,也可以提交给集群中运行,但是因为平台不兼容,需要做很多的设置修改
----要在windows中存放一份hadoop的安装包(解压好的)
----要将其中的lib和bin目录替换成根据你的windows版本重新编译出的文件
----再要配置系统环境变量 HADOOP_HOME 和 PATH
----修改YarnRunner这个类的源码