开源大数据开发平台DataSphereStudio&Linkis安装记录
Linkis:https://github.com/WeBankFinTech/Linkis
DataSphereStudio:https://github.com/WeBankFinTech/DataSphereStudio
编译部署常见问题:https://github.com/WeBankFinTech/Linkis/wiki/%E9%83%A8%E7%BD%B2%E5%92%8C%E7%BC%96%E8%AF%91%E9%97%AE%E9%A2%98%E6%80%BB%E7%BB%93
DSS常见问题列表:https://github.com/WeBankFinTech/DataSphereStudio/blob/master/docs/zh_CN/ch1/DSS%E5%AE%89%E8%A3%85%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E5%88%97%E8%A1%A8.md
用户登录认证方式:
https://mp.weixin.qq.com/s/OB3H0xnWIZ9-mTy9FI3UkA
LDAP参考文档:
https://www.sohu.com/a/284300312_283613
安装方式:
https://github.com/WeBankFinTech/DataSphereStudio/blob/master/docs/zh_CN/ch2/DSS_LINKIS_Quick_Install.md
DataSphereStudio(DSS)是微众银行开源的一站式大数据开发平台,开源于19年7月左右,目前市面上只发现这一个产品。基于公司需求,我们调研后发现基本满足现有的需求,于是安装。安装过程踩了些坑,在这里记录分享下。
环境:
centOS7
原生集群
DSS 0.7.0
Linkis 0.9.3
1.spark任务请求资源报错,版本不兼容,如下:
ERROR DWCException{errCode=20010, desc='NoSuchMethodError: org.apache.hadoop.io.retry.RetryPolicies.retryOtherThanRemoteException(Lorg/apache/hadoop/io/retry/RetryPolicy;Ljava/util/Map;)Lorg/apache/hadoop/io/retry/RetryPolicy;', ip='nl-dss2', port=9106, serviceKind='sparkEntrance'
微众使用的hadoop版本是2.7.2,spark使用的是2.4.3,spark内hadoop的相关的包是2.7.3版本,在安装成功后请求spark资源的时候会报错,将linkis-ujes-spark-enginemanager下原有的hadoop移出,把spark jars下面的hadoop复制到linkis-ujes-spark-enginemanager的lib下,就可以了
2.分布式安装的时候报错(获取Yarn队列信息异常)需要你的hadoop集群互相免密
先排查下访问yarn的web接口是否有问题,可以把yarn的web地址直接配成wds.linkis.yarn.rm.web.address属性,在RM的linkis.properties里
分布式安装时distribution.sh不要有默认的127.0.0.1,全都写成真实的ip或者主机名,安装后最好检查下每个任务的application.yml,里面的defaultZone可能有错。分布式安装后,其他台的机器我还需要自己启动,start-all.sh无法启动其他机器上的服务,希望这点后面版本能够改进。
3.新增用户后,查看不了元数据
我是开启了hive权限,grant all on database default to user test 后好了。
4.visualis显示没有权限查看:暂未解决
5.总资源数会变动,本来有48G内存,用到24G的时候显示100%使用

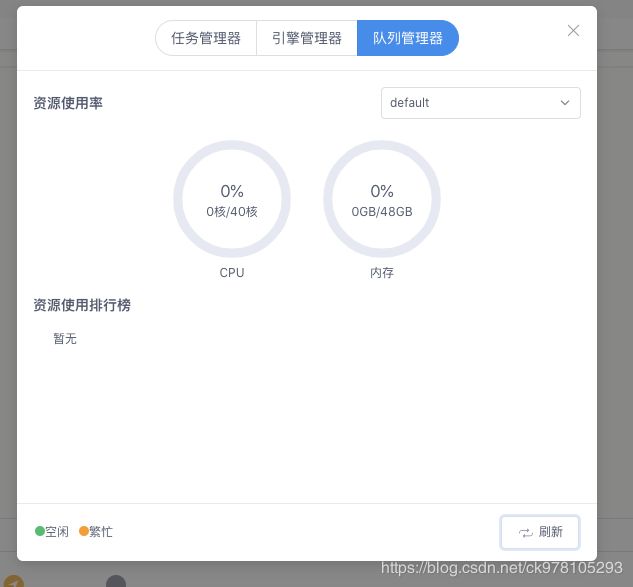
解决办法:我们一开始用的Capacity Scheduler,后来换成Fair Scheduler就好了
6.启动一次spark任务,结果启动了两个引擎,还在检查,可能是同时请求的并发数太多了,等待时间过了,导致重新请求,结果起了两个:原因可能是多次点击运行和取消。

7.hive执行计算的时候报错:
The ownership on the staging directory /tmp/hadoop-yarn/staging/test4/.staging is not as expected. It is owned by root. The directory must be owned by the submitter test4 or by test4
权限问题,需要把新建用户放到supergroup里,工作流删除重建就可以了,不然还会报这个错:
![]()
8.更新到DSS0.8.0后,使用ldap上的账号建工作流时报错:
![]()
解决办法:新增用户需要在dss-serve/conf下的token.properties和azkaban/conf下的azkaban-users.xml增加相关用户信息
9.我们测试20个人的时候报错,因为可能因为我们只用了一台256G服务器搭了DSS:

原因:总资源数受限
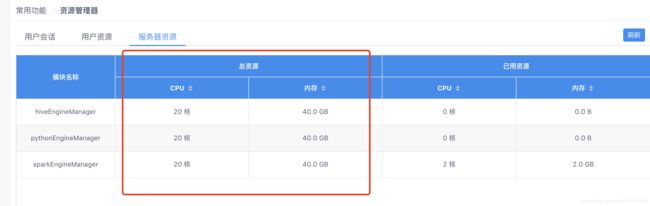
解决办法:在EM配置文件linkis.properties修改参数
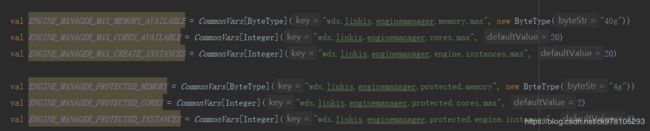
结果报了另一个错:
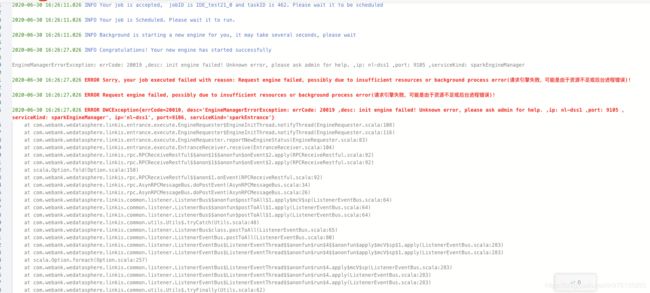
原因:当在同一台机器上提交多个spark任务时 并且是以client的方式提交,会报端口占用错误,spark.port.maxRetries太低
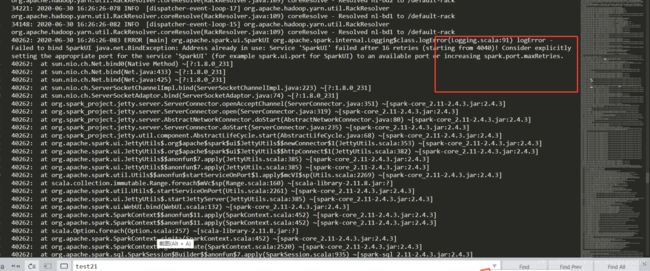
修改spark/conf下的spark-defaults.conf,添加或者修改spark.port.maxRetries 128就可以了
10.yarn资源有两百多G,却只能启动31个spark任务
原因:每个spark driver需要至少1核,我们用的32核机器单台部署,所以受到限制
解决办法:分布式部署DSS,多起一份spark服务,两台64核的可以跑50多个任务没问题。
11.shellEngineManager启动报错
java.lang.VerifyError: Stack map does not match the one at exception
将shellEM lib下的jackson-core-2.4.3.jar移除就可以了
12.执行azkaban调度任务的时候报错:
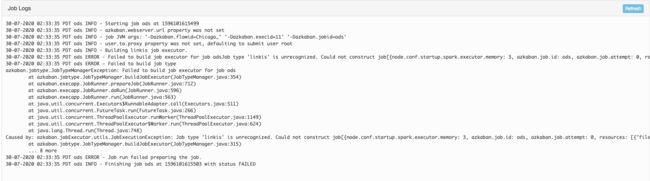
日志显示:
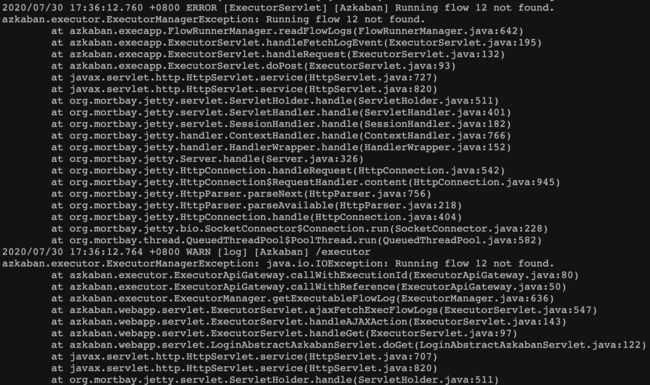
尚未解决
-----------使用HDP部署集群
HDP版本2.6.5
遇到的问题:
1.查看队列管理器报错
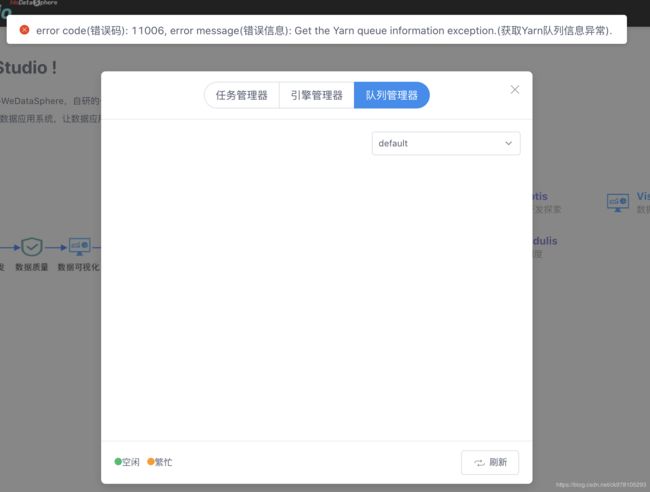
解决方法:
YarnUtils里第136行的报错那里,有两个JDecimal,需要改成JDouble,重新打包上传替换,重启linkis-resourcemanager