- 情绪觉察日记第37天
露露_e800
今天是家庭关系规划师的第二阶最后一天,慧萍老师帮我做了个案,帮我处理了埋在心底好多年的一份恐惧,并给了我深深的力量!这几天出来学习,爸妈过来婆家帮我带小孩,妈妈出于爱帮我收拾东西,并跟我先生和婆婆产生矛盾,妈妈觉得他们没有照顾好我…。今晚回家见到妈妈,我很欣赏她并赞扬她,妈妈说今晚要跟我睡我说好,当我们俩躺在床上准备睡觉的时候,我握着妈妈的手对她说:妈妈这几天辛苦你了,你看你多利害把我们的家收拾得
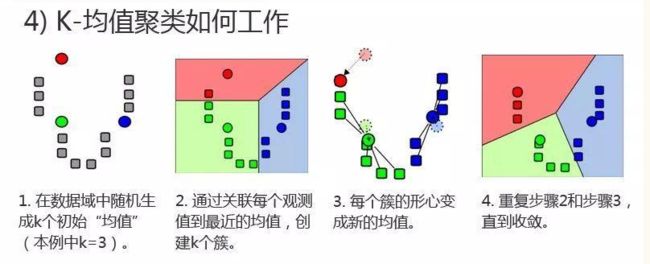
- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- 2020-01-25
晴岚85
郑海燕坚持分享590天2020.1.24在生活中只存在两个问题。一个问题是:你知道想要达成的目标是什么,但却不知道如何才能达成;另一个问题是:你不知道你的目标是什么。前一个是行动的问题,后一个是结果的问题。通过制定具体的下一步行动,可以解决不知道如何开始行动的问题。而通过去想象结果,对结果做预估,可以解决找不着目标的问题。对于所有吸引我们注意力,想要完成的任务,你可以先想象一下,预期的结果究竟是什
- element实现动态路由+面包屑
软件技术NINI
vue案例vue.js前端
el-breadcrumb是ElementUI组件库中的一个面包屑导航组件,它用于显示当前页面的路径,帮助用户快速理解和导航到应用的各个部分。在Vue.js项目中,如果你已经安装了ElementUI,就可以很方便地使用el-breadcrumb组件。以下是一个基本的使用示例:安装ElementUI(如果你还没有安装的话):你可以通过npm或yarn来安装ElementUI。bash复制代码npmi
- 理解Gunicorn:Python WSGI服务器的基石
范范0825
ipythonlinux运维
理解Gunicorn:PythonWSGI服务器的基石介绍Gunicorn,全称GreenUnicorn,是一个为PythonWSGI(WebServerGatewayInterface)应用设计的高效、轻量级HTTP服务器。作为PythonWeb应用部署的常用工具,Gunicorn以其高性能和易用性著称。本文将介绍Gunicorn的基本概念、安装和配置,帮助初学者快速上手。1.什么是Gunico
- 瑶池防线
谜影梦蝶
冥华虽然逃过了影梦的军队,但他是一个忠臣,他选择上报战况。败给影梦后成逃兵,高层亡尔还活着,七重天失守......随便一条,即可处死冥华。冥华自然是知道以仙界高层的习性此信一发自己必死无疑,但他还选择上报实情,因为责任。同样此信送到仙宫后,知道此事的人,大多数人都认定冥华要完了,所以上到仙界高层,下到扫大街的,包括冥华自己,全都准备好迎接冥华之死。如果仙界现在还属于两方之争的话,冥华必死无疑。然而
- 爬山后遗症
璃绛
爬山,攀登,一步一步走向制高点,是一种挑战。成功抵达是一种无法言语的快乐,在山顶吹吹风,看看风景,这是从未有过的体验。然而,爬山一时爽,下山腿打颤,颠簸的路,一路向下走,腿部力量不够,走起来抖到不行,停不下来了!第二天必定腿疼,浑身酸痛,坐立难安!
- 扫地机类清洁产品之直流无刷电机控制
悟空胆好小
清洁服务机器人单片机人工智能
扫地机类清洁产品之直流无刷电机控制1.1前言扫地机产品有很多的电机控制,滚刷电机1个,边刷电机1-2个,清水泵电机,风机一个,部分中高端产品支持抹布功能,也就是存在抹布盘电机,还有追觅科沃斯石头等边刷抬升电机,滚刷抬升电机等的,这些电机有直流有刷电机,直接无刷电机,步进电机,电磁阀,挪动泵等不同类型。电机的原理,驱动控制方式也不行。接下来一段时间的几个文章会作个专题分析分享。直流有刷电机会自动持续
- 绘本讲师训练营【24期】8/21阅读原创《独生小孩》
1784e22615e0
24016-孟娟《独生小孩》图片发自App今天我想分享一个蛮特别的绘本,讲的是一个特殊的群体,我也是属于这个群体,80后的独生小孩。这是一本中国绘本,作者郭婧,也是一个80厚。全书一百多页,均为铅笔绘制,虽然为黑白色调,但并不显得沉闷。全书没有文字,犹如“默片”,但并不影响读者对该作品的理解,反而显得神秘,梦幻,給读者留下想象的空间。作者在前蝴蝶页这样写到:“我更希望父母和孩子一起分享这本书,使他
- 30天风格练习-DAY2
黄希夷
Day2(重义)在一个周日/一周的最后一天,我来到位于市中心/市区繁华地带的一家购物中心/商场,中心内人很多/熙熙攘攘。我注意到/看见一个独行/孤身一人的年轻女孩/,留着一头引人注目/长过腰际的头发,上身穿一件暗红色/比正红色更深的衣服/穿在身体上的东西。走下扶梯的时候,她摔倒了/跌向地面,在她正要站起来/让身体离开地面的时候,过长/超过一般人长度的头发被支撑身体/躯干的手掌压/按在下面,她赶紧用
- 2018-07-23-催眠日作业-#不一样的31天#-66小鹿
小鹿_33
预言日:人总是在逃避命运的路上,与之不期而遇。心理学上有个著名的名词,叫做自证预言;经济学上也有一个很著名的定律叫做,墨菲定律;在灵修派上,还有一个很著名的法则,叫做吸引力法则。这3个领域的词,虽然看起来不太一样,但是他们都在告诉人们一个现象:你越担心什么,就越有可能会发生什么。同样的道理,你越想得到什么,就应该要积极地去创造什么。无论是自证预言,墨菲定律还是吸引力法则,对人都有正反2个维度的影响
- 水平垂直居中的几种方法(总结)
LJ小番茄
CSS_玄学语言htmljavascript前端csscss3
1.使用flexbox的justify-content和align-items.parent{display:flex;justify-content:center;/*水平居中*/align-items:center;/*垂直居中*/height:100vh;/*需要指定高度*/}2.使用grid的place-items:center.parent{display:grid;place-item
- 本周第二次约练
2cfbdfe28a51
中原焦点团队中24初26刘霞2021.12.3约练161次,分享第368天当事人虽然是带着问题来的,但是咨询过程中发现,她是经过自己不断地调整和努力才走到现在的,看到当事人的不容易,找到例外,发现资源,力量感也就随之而来。增强画面感,或者说重温,会给当事人带来更深刻的感受。
- 2019-12-22-22:30
涓涓1016
今天是冬至,写下我的日更,是因为这两天的学习真的是能量的满满,让我看到了自己,未来另外一种可能性,也让我看到了这两年这几年的过程中我所接受那些痛苦的来源。一切的根源和痛苦都来自于人生,家庭,而你的原生家庭,你的爸爸和妈妈,是因为你这个灵魂在那一刻选择他们作为你的爸爸和妈妈来的,所以你得接受他,你得接纳他,他就是因为他的存在而给你的学习和成长带来这些痛苦,那其实是你必然要经历的这个过程,当你去接纳的
- 第四天旅游线路预览——从换乘中心到喀纳斯湖
陟彼高冈yu
基于Googleearthstudio的旅游规划和预览旅游
第四天:从贾登峪到喀纳斯风景区入口,晚上住宿贾登峪;换乘中心有4路车,喀纳斯①号车,去喀纳斯湖,路程时长约5分钟;将上面的的行程安排进行动态展示,具体步骤见”Googleearthstudio进行动态轨迹显示制作过程“、“Googleearthstudio入门教程”和“Googleearthstudio进阶教程“相关内容,得到行程如下所示:Day4-2-480p
- 相信相信的力量
孙丽_cdb3
孙丽中级十期坚持分享第345天有一个特别有哲理的故事:有一只老鹰下了蛋,这个蛋,不知怎的就滚到了鸡窝里去了,鸡也下了一窝蛋,然后鸡妈妈把这些蛋全都浮出来了,孵出来之后等小鸡长大一点了,就觉得鹰蛋孵出来的那只小鹰怪模怪样,这些小鸡都嘲笑它,真难看,真笨,丑死了,那只小鹰觉得自己真是谁也不像,真是不好看,后来鸡妈妈也不喜欢他,我怎么生出你这样的孩子来了?真烦人,后来这群小鸡和小鹰一起生活,有一天,老鹰
- 今天我破防了
sin信仰
今天本来是大年初一,新年的第一天,应该是高高兴兴的一天,但是我怎么也高兴不起来。具体原因很简单,原本计划年后去县城找了一份会计的工作,被公公婆婆否定了,我心里立马就不舒服了,但是当时刚好肚子疼,我去了厕所,等我上完厕所,公公由于喝了酒还在那里和婆婆唠叨个没完。然后我就在心情极度压抑的情况下把午饭吃完的碗筷和锅给刷了。边刷碗筷和锅,边在那里难受,感觉自己在这个家里真的是过的憋屈死了,公婆不让我去上班
- LLM 词汇表
落难Coder
LLMsNLP大语言模型大模型llama人工智能
Contextwindow“上下文窗口”是指语言模型在生成新文本时能够回溯和参考的文本量。这不同于语言模型训练时所使用的大量数据集,而是代表了模型的“工作记忆”。较大的上下文窗口可以让模型理解和响应更复杂和更长的提示,而较小的上下文窗口可能会限制模型处理较长提示或在长时间对话中保持连贯性的能力。Fine-tuning微调是使用额外的数据进一步训练预训练语言模型的过程。这使得模型开始表示和模仿微调数
- 基于社交网络算法优化的二维最大熵图像分割
智能算法研学社(Jack旭)
智能优化算法应用图像分割算法php开发语言
智能优化算法应用:基于社交网络优化的二维最大熵图像阈值分割-附代码文章目录智能优化算法应用:基于社交网络优化的二维最大熵图像阈值分割-附代码1.前言2.二维最大熵阈值分割原理3.基于社交网络优化的多阈值分割4.算法结果:5.参考文献:6.Matlab代码摘要:本文介绍基于最大熵的图像分割,并且应用社交网络算法进行阈值寻优。1.前言阅读此文章前,请阅读《图像分割:直方图区域划分及信息统计介绍》htt
- 18-115 一切思考不能有效转化为行动,都TM是扯淡!
成长时间线
7月25号写了一篇关于为什么会断更如此严重的反思,然而,之后日更仅仅维持了一周,又出现了这次更严重的现象。从8月2号到昨天8月6号,5天!又是5天没有更文!虽然这次断更时间和上次一样,那为什么说这次更严重?因为上次之后就分析了问题的原因,以及应该如何解决,按理说应该会好转,然而,没过几天严重断更的现象再次出现,想想,经过反思,问题依然没有解决与改变,这让我有些担忧。到底是哪里出了问题,难道我就真的
- 《中华小厨师》单行VS爱藏:姜是老的辣,书是新的好
cicoky
《汉书·郦食其传》有曰:“王者以民为天,而民以食为天。”自古以来,吃饱饭是每一个人的基本要求,而吃好饭却是每一个人的最终追求。于是,厨师这一职业孕育而生,其渊源之久,甚至可追溯到4000年前的奴隶时代。职业本身无贵贱,但职业能力却有高低之分。所以一家餐馆生意好不好,厨师的水平决定一切,而站在所有厨师顶端的就被称之为“特级厨师”。今天要说的就是一个关于“特级厨师刘昴星”的故事。连载历程1995年第4
- 读《人世间》有感
一0一
这个寒假,就如同朋友圈中的一段话:一闭眼,一睁眼假期还有5天,在一闭眼一睁眼假期还有12天;再一闭眼一睁眼假期还有20天;不敢睡,不敢睡啊……受疫情影响,这个假期变得漫长又煎熬,我也无时无刻不关注着疫情的变化。当然这样的一个假期,我还真得要感谢周翔,因为他有个爱看书的习惯,所以家里有不少他看过的书,可以让我随意挑选,因此也让我的假期不至于那么无所事事。这次我选了一本梁晓声的《人世间》,作为一名语文
- DIV+CSS+JavaScript技术制作网页(旅游主题网页设计与制作)云南大理
STU学生网页设计
网页设计期末网页作业html静态网页html5期末大作业网页设计web大作业
️精彩专栏推荐作者主页:【进入主页—获取更多源码】web前端期末大作业:【HTML5网页期末作业(1000套)】程序员有趣的告白方式:【HTML七夕情人节表白网页制作(110套)】文章目录二、网站介绍三、网站效果▶️1.视频演示2.图片演示四、网站代码HTML结构代码CSS样式代码五、更多源码二、网站介绍网站布局方面:计划采用目前主流的、能兼容各大主流浏览器、显示效果稳定的浮动网页布局结构。网站程
- 特殊的拜年
飘雪的天堂
文/雪儿大年初一,家家户户没有了轰响的鞭炮声,大街上没有了人流涌动的喧闹,几乎看不到人影,变得冷冷清清。天刚亮不大会儿,村里的大喇叭响了起来:由于当前正值疾病高发期,流感流行的高峰期。同时,新型冠状病毒感染的肺炎进入第二波流行的上升期。为了自己和他人的健康安全着想,请大家尽量不要串门拜年,不要在街里走动。可以通过手机微信,视频,电话,信息拜年……今年的春节真是特别。禁止燃放鞭炮,烟花爆竹,禁止出村
- 使用Faiss进行高效相似度搜索
llzwxh888
faisspython
在现代AI应用中,快速和高效的相似度搜索是至关重要的。Faiss(FacebookAISimilaritySearch)是一个专门用于快速相似度搜索和聚类的库,特别适用于高维向量。本文将介绍如何使用Faiss来进行相似度搜索,并结合Python代码演示其基本用法。什么是Faiss?Faiss是一个由FacebookAIResearch团队开发的开源库,主要用于高维向量的相似性搜索和聚类。Faiss
- 深入理解 MultiQueryRetriever:提升向量数据库检索效果的强大工具
nseejrukjhad
数据库python
深入理解MultiQueryRetriever:提升向量数据库检索效果的强大工具引言在人工智能和自然语言处理领域,高效准确的信息检索一直是一个关键挑战。传统的基于距离的向量数据库检索方法虽然广泛应用,但仍存在一些局限性。本文将介绍一种创新的解决方案:MultiQueryRetriever,它通过自动生成多个查询视角来增强检索效果,提高结果的相关性和多样性。MultiQueryRetriever的工
- 想明白这个问题,你才能写下去
文自拾
春节放假的时候,又有一天梦见她,第二天她冒着漫天大雪,傻傻地跑来见我。她说,见见傻傻的我,天很冷,心很暖。她回去后,我写了一篇文章,题目叫——从此梦中只有你。我们没在一起的很长一段时间里,她都在我的心底,一次次出现在我的梦里。我对她说,在一起之前,是胆小且闷骚,在一起之后,我变得不要脸了。不要脸的——去爱你。那文章没写完,火车上,给她看了。我有点小失望,花了好几个小时写,她分分钟就看完,很希望她逐
- 无题,感慨
竹间书编辑
玉生烟,雪落天,枯叶随雪葬行边,何有芳名,流落人世间。雪中行,路中停,风送鹅雪风无情,且将留此,风波却未平
- 2019-08-08
65454
东莞家庭聚会出行旅游去哪里玩住?想起来有很久没有和家里人聚会啦,这次组织家人来到威廉古堡别墅轰趴,一大家子27个人,在别墅订了一天办,玩的非常的开心,小孩子玩游戏机,也很放心不会丢,我们就在唱歌、打麻将、打桌球一系列的活动,还准备小次等小孩生日在别墅举办,还可以给孩子做一个生日的策划
- 2.0践行没有你的参与就不完美
x秀丽x
亲爱的伙伴们早上好,今天早上我们开了一次班委竞选的会议,全程只有20多个人参与,宫班本着对大家负责任的态度告诉我们,此次竞选作废,原因是这没有达到2.0的100%参会要求,如果没有大家的参与那么这个班委选出来还有什么意义,这说明选出来的人也是不一定是我们大家心目中认可的那个人,所以为了让大家的这个90天能够更好的激发出自己的的“做”的能力,那么要从第一次竞选班委的会议开始做到100%出席会议,竞选
- jdk tomcat 环境变量配置
Array_06
javajdktomcat
Win7 下如何配置java环境变量
1。准备jdk包,win7系统,tomcat安装包(均上网下载即可)
2。进行对jdk的安装,尽量为默认路径(但要记住啊!!以防以后配置用。。。)
3。分别配置高级环境变量。
电脑-->右击属性-->高级环境变量-->环境变量。
分别配置 :
path
&nbs
- Spring调SDK包报java.lang.NoSuchFieldError错误
bijian1013
javaspring
在工作中调另一个系统的SDK包,出现如下java.lang.NoSuchFieldError错误。
org.springframework.web.util.NestedServletException: Handler processing failed; nested exception is java.l
- LeetCode[位运算] - #136 数组中的单一数
Cwind
java题解位运算LeetCodeAlgorithm
原题链接:#136 Single Number
要求:
给定一个整型数组,其中除了一个元素之外,每个元素都出现两次。找出这个元素
注意:算法的时间复杂度应为O(n),最好不使用额外的内存空间
难度:中等
分析:
题目限定了线性的时间复杂度,同时不使用额外的空间,即要求只遍历数组一遍得出结果。由于异或运算 n XOR n = 0, n XOR 0 = n,故将数组中的每个元素进
- qq登陆界面开发
15700786134
qq
今天我们来开发一个qq登陆界面,首先写一个界面程序,一个界面首先是一个Frame对象,即是一个窗体。然后在这个窗体上放置其他组件。代码如下:
public class First { public void initul(){ jf=ne
- Linux的程序包管理器RPM
被触发
linux
在早期我们使用源代码的方式来安装软件时,都需要先把源程序代码编译成可执行的二进制安装程序,然后进行安装。这就意味着每次安装软件都需要经过预处理-->编译-->汇编-->链接-->生成安装文件--> 安装,这个复杂而艰辛的过程。为简化安装步骤,便于广大用户的安装部署程序,程序提供商就在特定的系统上面编译好相关程序的安装文件并进行打包,提供给大家下载,我们只需要根据自己的
- socket通信遇到EOFException
肆无忌惮_
EOFException
java.io.EOFException
at java.io.ObjectInputStream$PeekInputStream.readFully(ObjectInputStream.java:2281)
at java.io.ObjectInputStream$BlockDataInputStream.readShort(ObjectInputStream.java:
- 基于spring的web项目定时操作
知了ing
javaWeb
废话不多说,直接上代码,很简单 配置一下项目启动就行
1,web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="h
- 树形结构的数据库表Schema设计
矮蛋蛋
schema
原文地址:
http://blog.csdn.net/MONKEY_D_MENG/article/details/6647488
程序设计过程中,我们常常用树形结构来表征某些数据的关联关系,如企业上下级部门、栏目结构、商品分类等等,通常而言,这些树状结构需要借助于数据库完成持久化。然而目前的各种基于关系的数据库,都是以二维表的形式记录存储数据信息,
- maven将jar包和源码一起打包到本地仓库
alleni123
maven
http://stackoverflow.com/questions/4031987/how-to-upload-sources-to-local-maven-repository
<project>
...
<build>
<plugins>
<plugin>
<groupI
- java IO操作 与 File 获取文件或文件夹的大小,可读,等属性!!!
百合不是茶
类 File
File是指文件和目录路径名的抽象表示形式。
1,何为文件:
标准文件(txt doc mp3...)
目录文件(文件夹)
虚拟内存文件
2,File类中有可以创建文件的 createNewFile()方法,在创建新文件的时候需要try{} catch(){}因为可能会抛出异常;也有可以判断文件是否是一个标准文件的方法isFile();这些防抖都
- Spring注入有继承关系的类(2)
bijian1013
javaspring
被注入类的父类有相应的属性,Spring可以直接注入相应的属性,如下所例:1.AClass类
package com.bijian.spring.test4;
public class AClass {
private String a;
private String b;
public String getA() {
retu
- 30岁转型期你能否成为成功人士
bijian1013
成长励志
很多人由于年轻时走了弯路,到了30岁一事无成,这样的例子大有人在。但同样也有一些人,整个职业生涯都发展得很优秀,到了30岁已经成为职场的精英阶层。由于做猎头的原因,我们接触很多30岁左右的经理人,发现他们在职业发展道路上往往有很多致命的问题。在30岁之前,他们的职业生涯表现很优秀,但从30岁到40岁这一段,很多人
- 【Velocity四】Velocity与Java互操作
bit1129
velocity
Velocity出现的目的用于简化基于MVC的web应用开发,用于替代JSP标签技术,那么Velocity如何访问Java代码.本篇继续以Velocity三http://bit1129.iteye.com/blog/2106142中的例子为基础,
POJO
package com.tom.servlets;
public
- 【Hive十一】Hive数据倾斜优化
bit1129
hive
什么是Hive数据倾斜问题
操作:join,group by,count distinct
现象:任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成;查看未完成的子任务,可以看到本地读写数据量积累非常大,通常超过10GB可以认定为发生数据倾斜。
原因:key分布不均匀
倾斜度衡量:平均记录数超过50w且
- 在nginx中集成lua脚本:添加自定义Http头,封IP等
ronin47
nginx lua csrf
Lua是一个可以嵌入到Nginx配置文件中的动态脚本语言,从而可以在Nginx请求处理的任何阶段执行各种Lua代码。刚开始我们只是用Lua 把请求路由到后端服务器,但是它对我们架构的作用超出了我们的预期。下面就讲讲我们所做的工作。 强制搜索引擎只索引mixlr.com
Google把子域名当作完全独立的网站,我们不希望爬虫抓取子域名的页面,降低我们的Page rank。
location /{
- java-3.求子数组的最大和
bylijinnan
java
package beautyOfCoding;
public class MaxSubArraySum {
/**
* 3.求子数组的最大和
题目描述:
输入一个整形数组,数组里有正数也有负数。
数组中连续的一个或多个整数组成一个子数组,每个子数组都有一个和。
求所有子数组的和的最大值。要求时间复杂度为O(n)。
例如输入的数组为1, -2, 3, 10, -4,
- Netty源码学习-FileRegion
bylijinnan
javanetty
今天看org.jboss.netty.example.http.file.HttpStaticFileServerHandler.java
可以直接往channel里面写入一个FileRegion对象,而不需要相应的encoder:
//pipeline(没有诸如“FileRegionEncoder”的handler):
public ChannelPipeline ge
- 使用ZeroClipboard解决跨浏览器复制到剪贴板的问题
cngolon
跨浏览器复制到粘贴板Zero Clipboard
Zero Clipboard的实现原理
Zero Clipboard 利用透明的Flash让其漂浮在复制按钮之上,这样其实点击的不是按钮而是 Flash ,这样将需要的内容传入Flash,再通过Flash的复制功能把传入的内容复制到剪贴板。
Zero Clipboard的安装方法
首先需要下载 Zero Clipboard的压缩包,解压后把文件夹中两个文件:ZeroClipboard.js
- 单例模式
cuishikuan
单例模式
第一种(懒汉,线程不安全):
public class Singleton { 2 private static Singleton instance; 3 pri
- spring+websocket的使用
dalan_123
一、spring配置文件
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.or
- 细节问题:ZEROFILL的用法范围。
dcj3sjt126com
mysql
1、zerofill把月份中的一位数字比如1,2,3等加前导0
mysql> CREATE TABLE t1 (year YEAR(4), month INT(2) UNSIGNED ZEROFILL, -> day
- Android开发10——Activity的跳转与传值
dcj3sjt126com
Android开发
Activity跳转与传值,主要是通过Intent类,Intent的作用是激活组件和附带数据。
一、Activity跳转
方法一Intent intent = new Intent(A.this, B.class); startActivity(intent)
方法二Intent intent = new Intent();intent.setCla
- jdbc 得到表结构、主键
eksliang
jdbc 得到表结构、主键
转自博客:http://blog.csdn.net/ocean1010/article/details/7266042
假设有个con DatabaseMetaData dbmd = con.getMetaData(); rs = dbmd.getColumns(con.getCatalog(), schema, tableName, null); rs.getSt
- Android 应用程序开关GPS
gqdy365
android
要在应用程序中操作GPS开关需要权限:
<uses-permission android:name="android.permission.WRITE_SECURE_SETTINGS" />
但在配置文件中添加此权限之后会报错,无法再eclipse里面正常编译,怎么办?
1、方法一:将项目放到Android源码中编译;
2、方法二:网上有人说cl
- Windows上调试MapReduce
zhiquanliu
mapreduce
1.下载hadoop2x-eclipse-plugin https://github.com/winghc/hadoop2x-eclipse-plugin.git 把 hadoop2.6.0-eclipse-plugin.jar 放到eclipse plugin 目录中。 2.下载 hadoop2.6_x64_.zip http://dl.iteye.com/topics/download/d2b
- 如何看待一些知名博客推广软文的行为?
justjavac
博客
本文来自我在知乎上的一个回答:http://www.zhihu.com/question/23431810/answer/24588621
互联网上的两种典型心态:
当初求种像条狗,如今撸完嫌人丑
当初搜贴像条犬,如今读完嫌人软
你为啥感觉不舒服呢?
难道非得要作者把自己的劳动成果免费给你用,你才舒服?
就如同 Google 关闭了 Gooled Reader,那是
- sql优化总结
macroli
sql
为了是自己对sql优化有更好的原则性,在这里做一下总结,个人原则如有不对请多多指教。谢谢!
要知道一个简单的sql语句执行效率,就要有查看方式,一遍更好的进行优化。
一、简单的统计语句执行时间
declare @d datetime ---定义一个datetime的变量set @d=getdate() ---获取查询语句开始前的时间select user_id
- Linux Oracle中常遇到的一些问题及命令总结
超声波
oraclelinux
1.linux更改主机名
(1)#hostname oracledb 临时修改主机名
(2) vi /etc/sysconfig/network 修改hostname
(3) vi /etc/hosts 修改IP对应的主机名
2.linux重启oracle实例及监听的各种方法
(注意操作的顺序应该是先监听,后数据库实例)
&nbs
- hive函数大全及使用示例
superlxw1234
hadoophive函数
具体说明及示例参 见附件文档。
文档目录:
目录
一、关系运算: 4
1. 等值比较: = 4
2. 不等值比较: <> 4
3. 小于比较: < 4
4. 小于等于比较: <= 4
5. 大于比较: > 5
6. 大于等于比较: >= 5
7. 空值判断: IS NULL 5
- Spring 4.2新特性-使用@Order调整配置类加载顺序
wiselyman
spring 4
4.1 @Order
Spring 4.2 利用@Order控制配置类的加载顺序
4.2 演示
两个演示bean
package com.wisely.spring4_2.order;
public class Demo1Service {
}
package com.wisely.spring4_2.order;
public class