注意看代码注释,解析全在注释里面!!!
1. 代码:
import torch
import torch.utils.data as Data
import torch.nn.functional as F
import matplotlib.pyplot as plt
"""
此段代码用于对比各种优化器在神经网络训练时候的训练速度
"""
# 定义一些参数,学习率,每一批的训练数据,以及训练的次数
LR = 0.01
BATCH_SIZE = 32
EPOCH = 12
# 构造我们要训练的数据,手动构造
x = torch.unsqueeze(torch.linspace(-1,1,1000),dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
print(*x.size()) # 输出为 1000 1
print(torch.zeros(*x.size())) # 输出得知这是1000行一列的全是0的数据
"""
normal函数代表从给定参数的离散正太分布中抽取随机数,normal(means,std,out)三个参数,
means - 均值
std - 标准差
out - 可选的输出张量
这里torch.zeros。。。得到的全是0,就意味着它会随机从每个均值为0的正太分布中去取出每一个值。
"""
print(torch.normal(torch.zeros(*x.size())))
# 画出点
# plt.scatter(x.numpy(),y.numpy())
# plt.show()
# 将数据放到dataset中加载
torch_dataset = Data.TensorDataset(x,y)
loader = Data.DataLoader(
dataset=torch_dataset, # 加载数据集
batch_size=BATCH_SIZE, # 每次训练的数据量
shuffle=True, # 随机打乱数据
num_workers=2, # 线程数
)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1,20)
self.predict = torch.nn.Linear(20,1)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
if __name__ == '__main__':
# 构建四个使用不同优化器的神经网络
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
# 创建不同的优化器
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
loss_func = torch.nn.MSELoss()
losses_lis = [[],[],[],[]] # 用来存储每种优化器的损失值
# 训练
for epoch in range(EPOCH): # 训练多少次
print('Epoch: ', epoch)
for step, (b_x, b_y) in enumerate(loader): # 每次训练分几步,这个是由我的batch数量决定的
for net, opt, l_his in zip(nets, optimizers, losses_lis):
output = net(b_x) # get output for every net
loss = loss_func(output, b_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.data.numpy()) # loss recoder
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_lis):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()
2. 运行结果
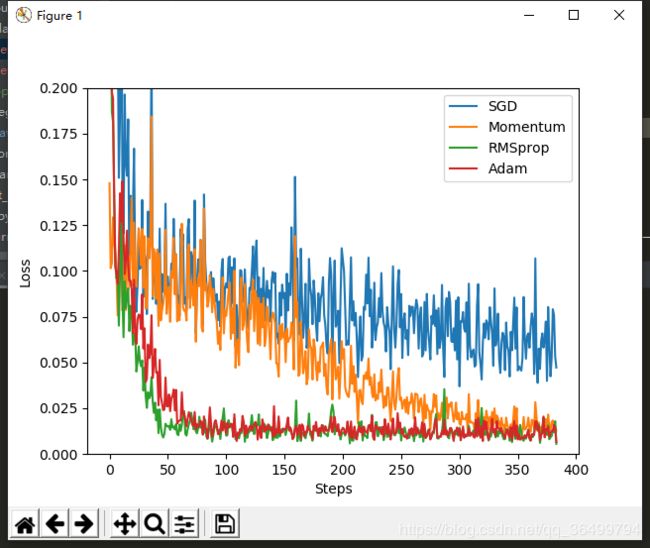
其实我们可以看出来平时最常用的SGD优化是效率最低的哈哈哈