hadoop开发步骤
1.安装vmware 虚拟机
2.安装centos7
3.配置网络 nmtui
4.三个ping
5.安装并使用 xshell,xftp
6.设置静态IP
7.三个ping 还可以进行 ip a 看一下有没有IP,还可以通过xshell
8.免密码登录
9.使用yum 安装vim
10.安装jdk(window,linux)
11.安装hadoop2.6
12.克隆虚拟机,修改IP
配置静态IP:
在新安装好的CentOS7上和之前的CentOS6版本一样,初始状态是没有网络配置的,则需要使用dhclient命令来自动获取IP地址,查看获取的IP地址则使用命令 ip addr,则会看到网卡信息和lo卡信息,进入配置文件修改IP信息
vi /etc/sysconfig/network-scripts/ifcfg-xxxxxxx
点击i进入编辑状态
修改:onboot=yes
bootproto=static
添加:IPADDR= #IP地址(ip地址通过 ip a 可以得到,ifconfig 也可以,如果没有此工具最下边有方法解决)
GATEWAY= #默认网关(route -n命令可以得到,图形界面同学可以找到,非图形界面的同学可以查看虚拟机网络配置如下图,选择vmnet8,点击net设置)
NETMASK= #子网掩码(下图类似,如果有/24 代表 子网掩码是255.255.255.0)
DNS1= #DNS(DNS输入8.8.8.8就可以)
DNS2=#网关 (如果不配置网络有可能连不上外网)
编辑完以后,按esc退出
输入:wq 保存退出
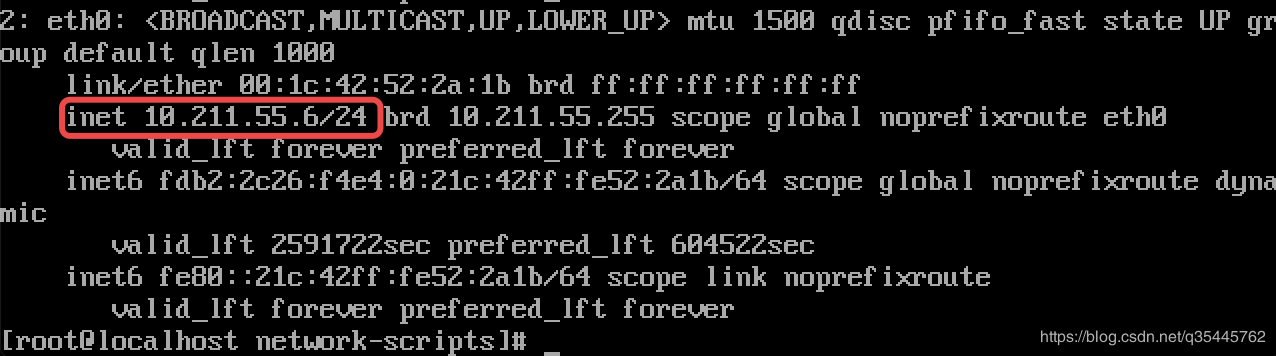
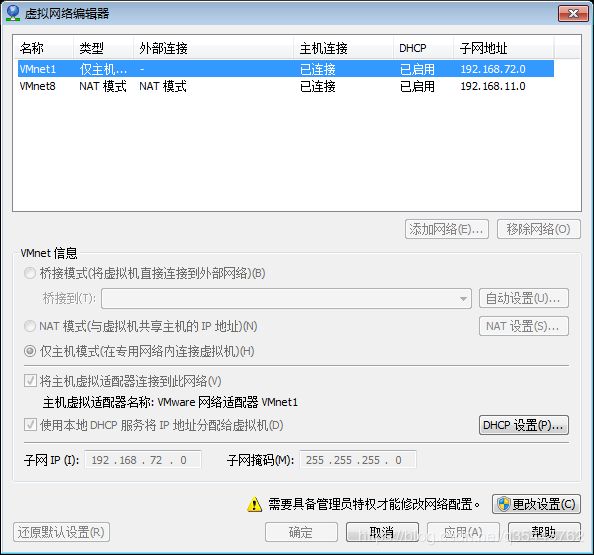

实例如下:

保存退出,重启网卡
service network restart;
(记得要关闭本机和虚拟机的防火墙!!!!!!!)
此时,使用ifconfig提示没有该命令,则需要安装net-tools工具,yum install -y net-tools,安装完毕就可以ifconfig,查看网卡信息.
ifup eth0(设备名) 一般不需要执行此命令
免密码登录:
ssh [email protected] 需要登陆密码
1.ssh-keygen 生成公钥和私钥 可以去.ssh 查看是否有两个文件 id_rsa id_rsa.pub
ssh-copy-id [email protected] 复制公钥到远程服务器 可以去.ssh 查看是否有 authorized_keys
ssh [email protected] 不需要登陆密码了
使用yum安装应用:
1.cd /etc/yum.repos.d目录中,把除了Centos-media.repo 文件不改成.bak文件,其他都加.bak成备份文件
2.vi Centos-media.repo 修改文件
[c7-media]
name=CentOS-$releasever - Media
baseurl=file:///media/
gpgcheck=0
enabled=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
3.下边要进行挂载 mount /dev/cdrom /media
4.在/etc/sysconfig/network-scripts/ifcfg-ens33中加入
DNS2=虚拟机网关(不配置的话有有可能ping不通百度,ping不通的话,yum下载一定不行)
5.到/etc目录下配置resolv.conf加入nameserver IP,如:
nameserver 8.8.8.8
nameserver 8.8.4.4
search localdomain
保存再次运行上面的命令就可以。
6./在CentOS7中关闭防火墙使用以下命令,
systemctl stop firewalld
systemctl disable firewalld
7.并关闭 本机防火墙
8.把centos关机
9.再次清除系统yum缓存,并重新生成新的yum缓存
yum clean all
yum makecache
10.安装vim
yum install -y vim
如果以前yum 运行成功过。只需要做三步:
1.挂载 mount /dev/cdrom /media
2.查看磁盘挂载情况 df
3.yum install -y vim
安装jdk:
1.使用ftp工具把jdk-7u80-linux-x64.rpm 放在linux中的/opt目录中
2.在linux切换到/opt中
3.rpm -ivh jdk-7u80-linux-x64.rpm 安装jdk
4.查看jdk路径 /usr/java/jdk1.7.0_80/bin
5.备份环境变量文件 cp /etc/profile /etc/profile.bak
6.设置环境变量,vim /etc/profile
添加变量值:
export PATH=/usr/java/jdk1.7.0_80/bin:$PATH
7.使环境变量生效
source /etc/profile
7.java -version 查看java是否成功
安装hadoop:
1.把hadoop-2.6.4.tar.gz 上传到/opt目录中
2.在centos中切换到/opt目录中
3.执行 解压缩操作 tar -zxf hadoop-2.6.4.tar.gz -C /usr/local
4.切换到hadoop环境变量的文件中
cd /usr/local/hadoop-2.6.4/etc/hadoop
①core-site.xml 这是hadoop 核心配置文件
②hadoop-env.sh 这是hadoop运行基本环境的配置文件
③yarn-env.sh 这是hadoop 的yarn框架相关配置 计算使用
④mapred-site.xml 这是hadoop的mapreduce框架端口号相关配置 存储使用
⑤yarn-site.xml 这是hadoop的yarn框架端口号配置 计算使用
⑥slaves 这是hadoop的节点配置
⑦hdfs-site.xml 这是hadoop关于hdfs框架分布式文件存储的配置
core-site.xml 设置如下:
hadoop-env.sh配置如下:
export JAVA_HOME=/usr/java/jdk1.7.0_80
yarn-env.sh配置如下:
export JAVA_HOME=/usr/java/jdk1.7.0_80
mapred-site.xml配置如下:(此是通过 mapred-site.xml.template 模板复制出一份名字为mapred-site.xml)
yarn-site.xml配置如下:
<!--声明变量yarn.resourcemanager.hostname 为了后边使用-->
slaves 配置如下:(我们设置两个数据节点,所以设置两个slave)
slave1
slave2
hdfs-site.xml 配置如下:
5.修改 主机名(根据上边hadoop的需要 主节点主机名是:master ),修改完以后需要重启服务器!
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master
6.修改/etc/hosts文件 master新增一行IP 域名的对应
192.168.11.129 master
注意:当不能修改时执行(永久修改主机名)
hostnamectl set-hostname slave17.修改完,需要重启服务器生效(重启后,输入命令: hostname 看下主机名是否变成master)
reboot
8.修改本机的hosts文件 和虚拟机的hosts文件(为了通过主机名可以ping通,而不是通过ip)
本机的hosts文件在C:\Windows\System32\drivers\etc下(在此文件下增加一行,配置虚拟机的IP和主机名对应关系)
192.168.11.129 master
虚拟机的hosts文件在/etc/hosts下(在此文件下增加一行,以后通过admin,可以在虚拟机中ping通本机)
克隆虚拟机,修改ip:
1.克隆虚拟机 生成一个名字叫slave1的虚拟机
centos7只需要修改IP
vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改IP地址
2.查看ip 地址 ip a
3.三个ping ping的通
4.两台虚拟机通过IP ping
5.修改主机名
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave1
并执行(永久修改主机名)
hostnamectl set-hostname slave1
6.修改hosts文件(想通过机器名互相访问,在master/slave1虚拟机中都要增加)
虚拟机中 vim /etc/hosts 新增一行,做一下slave1 的ip 和以后想通过一个访问名字对应关系
192.168.11.130 slave1
本机中编辑 C:\Windows\System32\drivers\etc\hosts文件,新增一行
192.168.11.130 slave1
创建组
1.创建 /usr/local/hadoop-2.6.4/tmp文件夹为了core-site.xml放置nameNode存储元数据使用。
cd /usr/local/hadoop-2.6.4/
mkdir tmp
2.注意修改环境变量 /etc/profile 文件增加 ,修改后别忘记 source /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_80
export HADOOP_HOME=/usr/local/hadoop-2.6.4
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
3.执行格式化 进入 /usr/local/hadoop-2.6.4/bin
sh hdfs namenode -format
如果出现
common.Storage: Storage directory /data/hadoop/hdfs/name has been successfully formatted.
代表格式化成功!
4.启动hdfs(第一次启动的话,会验证一下,输入yes)
sh start-dfs.sh
5.验证是否启动成功(如果出现 SecondaryNameNode、 DataNode、NameNode代表成功)
jps
6.访问HDFS页面是否成功(务必关闭防火墙systemctl status firewalld //查看状态
开机禁用 : systemctl disable firewalld 关闭: systemctl stop firewalld)
http://master:50070
7.安装NTP时间同步服务
【在安装前注意先检查是否关闭防火墙
务必关闭防火墙systemctl status firewalld //查看状态
开机禁用 : systemctl disable firewalld 关闭: systemctl stop firewalld)
master上安装ntp组件
yum -y install ntp
master上调整时间
这一步为确保master上的时间与本地时间保持一致,如果可以联网的情况下执行命令
ntpdate 0.centos.pool.ntp.org #该网址为centos网络上的时间同步服务器一般情况下,我们的集群为内网环境,无法和外网进行联网同步之间,那么手动执行命令调整时间(可以不操作)
date -s '2008-05-23 01:01:01' #2008-05-23 01:01:01为将要设定的时间host1上修改配置文件/etc/ntp.conf,把本机时间作为同步时间源
vim /etc/ntp.conf-
#添加下面两行,表示将本地的硬件时间也作为同步的时间源之一,这样在不联网的时候可以把本机时间作为同步时间源, 在内网##环境下,可以把配置文件中其他的server都删除掉。 -
server 127.127.1.0 # local clock -
fudge 127.127.1.0 stratum 10 -
#如果集群是在一个封闭的局域网内,可以屏蔽掉默认的server: -
#server 0.centos.pool.ntp.org iburst -
#server 1.centos.pool.ntp.org iburst -
#server 2.centos.pool.ntp.org iburst -
#server 3.centos.pool.ntp.org iburst
host1上修改配置文件/etc/ntp.conf,host1上配置对客户端的授权(要根据自己的集群环境配置网关、子网掩码)
restrict 10.211.55.1 mask 255.255.255.0 nomodify notrap也就是给指定的机器(客户端)设置访问NTP Server的权限,这是通过restrict配置项实现的,以下是它的格式说明。
其中parameter的参数主要有:
ignore : 拒绝所有类型的ntp连接
nomodify : 客户端不能使用ntpc与ntpq两支程式来修改服务器的时间参数
noquery : 客户端不能使用ntpq、ntpc等指令来查询服务器时间,等于不提供ntp的网络校时
notrap : 不提供trap这个远程时间登录的功能
notrust : 拒绝没有认证的客户端
nopeer : 不与其他同一层的ntp服务器进行时间同步
让我们通过一个例子来解释一下,在 /etc/ntp.conf中加入如下一行:
restrict 10.211.55.1 mask 255.255.255.0 nomodify notrap
这一行的含义是授权10.211.55.1网段上的所有机器可以从这台机器上查询和同步时间。这里的配置涉及到了一些网络知识。 对于第一个参数[address] 它可能是一个IP,也可能是一个网段,这取决于后面给出的子网掩码。如果这里的子网掩码是255.255.255.255,那么配置就变成了只授权给IP是10.211.55.1的那一台机器连接!但是这里子网掩码是255.255.255.0,则此时的10.211.55.1就是一个网络标识了!它代表的是这样一个网段:
| 网络标识 (网段名) |
主机 | 广播地址 | |
| 起始 | 结束 | ||
| 10.211.55.1 | 10.211.55.2 | 10.211.55.254 | 10.211.55.255 |
master上启动ntp组件
-
service ntpd start #启动ntpd时间服务器 -
chkconfig ntpd on #开机自启动
需要同步时间的服务器 slave1,slave2上对ntp组件安装
这里指的就是slave1,slave2
slave1,slave2上安装ntp组件
在slave1,slave2上分别执行命令安装ntp,跟上面《slave1上安装ntp组件》安装方式一致,其余安装方式也参考上面
yum -y install ntpslave1,slave2上修改配置文件/etc/ntp.conf
vi /etc/ntp.conf
删除其他的server 开头的配置项,这里一定要删除,只同步我们配置的那台服务器,添加上面设置的NTP服务器地址
server host1slave1,slave2上启动ntp组件并测试
-
ntpdate master #同步时间 -
service ntpd start #启动ntpd时间服务器 -
chkconfig ntpd on #开机自启动
查看与时间同步服务器的时间偏差
-
[root@host2 ~]# ntpdc -c loopinfo -
offset: 0.001014 s #时间偏差极小,即同步了 -
frequency: 29.720 ppm -
poll adjust: 30 -
watchdog timer: 929 s
查看当前同步的时间服务器,查看没问题就安装成功了
-
[root@host2 ~]# ntpq -p -
#remote refid st t when poll reach delay offset jitter -
#============================================================================== -
#host1 202.112.29.82 3 u 764 1024 377 0.369 7.155 7.045 -
#这里出现host1就表示host2与host1自动同步时间,host1前面的*表示正在使用的时间同步服务器,如果配置#多个,还有出现+开头的,表示候选的时间同步服务器】
8.关闭hdfs
sh stop-dfs.sh