《Python数据分析与挖掘实战》第10章(下)——DNN
本文是基于《Python数据分析与挖掘实战》的实战部分的第10章的数据——《家用电器用户行为分析与事件识别》做的分析。
接着前一篇文章的内容,本篇博文重点是处理用水事件中的属性构造部分,然后进行构建模型分析。
1 属性构造
由文中可知:需要构造的属性如下:
热水事件起始数据编号、终止数据编号、开始时间(begin_time)、根据日志判断是否为洗浴(1表示是,0表示否)、洗浴时间点、总用水时长(w_time)、总停顿时长(w_pause_time)、平均停顿时长(avg_pause_time)、停顿次数(pause)、用水时长(use_water_time)、用水/总时长(use_water_rate)、总用水量(w_water)、平均水流量(water_rate)、水流量波动(flow_volatility)、停顿时长波动(pause_volatility)
此部分博主花了较长时间,其中很大原因是因为对文中作者描述的属性的相关定义进行的探索确定,以及编程实现。由于一次用水中可能存在停顿,因此,在实现属性构造之前,需要进行以下数据连接工作。
inputfile = 'dataExchange_divideEvent.xlsx'
data = pd.read_excel(inputfile)
# len(data)# 7696
inputfile1 = 'data_guiyue.xlsx'
data1 = pd.read_excel(inputfile1)
x = pd.merge(data1,data[[u'事件编号']],left_index = True, right_index=True,how='outer')
# 连接'data_guiyue.xlsx'和 'dataexchange_divideEvent.xlsx'的后两列,因为,属性规约里面包含水流量为0的数值,后一个表中,只含有水流量不为0的值,需要将两边进行连接,获知规约后的数据中的数据所属的事件数,利用处理后的数开始进行数据构造工作
x.head()#18840
x.to_excel('data_for_attr_const.xlsx')1.1 准备工作:
df = pd.read_excel('data_for_attr_const.xlsx')
# 将数据划分成一次用水事件!(*****)
#-----第*1*步-----做基本处理,获取用于构造属性的数据表
# 将数据划分成一次用水事件!(*****)
# 思路:获取每个事件的序号值所在的最小的index值和最大的index值,然后将其连接,
# 即: 去掉不同事件间的“事件编号”为空的值,保留同一个事件内的“事件编号”为空的值
l=list(df[u'事件编号'])
Adf = DataFrame([], columns = df.columns)# 创建一个空列表
pos=-1
MX = int(df[u'事件编号'].max())
for j in range(MX):
y = []
for i in range(l.count(j+1)):
pos=l.index(j+1,pos+1)
y.append(pos)
a = min(y)
b = max(y)
temp = df.iloc[a:b+1,:]
Adf = pd.concat([Adf,temp])
Adf[u'事件编号'].fillna(method='ffill',inplace = True) # 向后填充,填上了事件编号的空值
Adf[[u'水流量']] = Adf[[u'水流量']].astype('float64')
Adf.to_excel('1TimeWaterDivide.xlsx')
Adf.head()
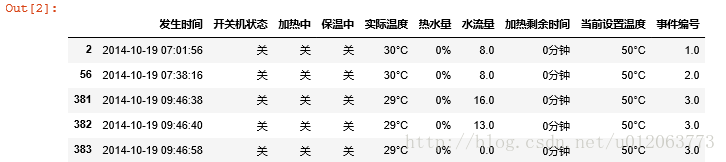
#-----第*2*步-----建立存放构造的属性的表
df2 = pd.read_excel('1TimeWaterDivide.xlsx')
df2['gap'] = df2[u'发生时间'].diff()
MX = int(df2[u'事件编号'].max())# 获取当前事件数172
fdf2 = DataFrame([], index = range(1,MX+1))# 创建一个空列表 用来存放属性规约结果1.2 开始构造属性
1.2.1 构造属性第一部分
包含用水事件开始编号、用水事件结束编号、用水开始时间、用水结束时间、用水总时间、用水间隔时间、一次用水期间“水流量”为0的记录数
fdf2.index.names = ['eventNUM']
fdf2['stDataIndex'] = np.nan #用水事件开始编号
fdf2['edDataIndex'] = np.nan #用水事件结束编号
fdf2['stUseTime'] = np.nan #用水开始时间
fdf2['enUseTime'] = np.nan #用水结束时间
fdf2['AllUseTime'] = np.nan #用水总时间
fdf2['gapTimes'] = np.nan #用水间隔时间
fdf2['stopLines'] = np.nan # 一次用水期间“水流量”为0的记录数
ds = pd.Timedelta(seconds = 2) # 发送阈值时间设置为2秒
pos=-1# 标记变量 ******
l=list(df2[u'事件编号'])
# 以下空列表均是暂时存储数据
stUI = []
enUI = []
startU = []
endU = []
allUT = []
gapTS = []
stopLines = []
for j in range(MX):
# 计算事件编号j在列表中的最开始出现的index和最后出现的index
y = []# 存储时间编号j出现的所有的index(临时存储)
for i in range(l.count(j+1)):
pos=l.index(j+1,pos+1)
y.append(pos)
a = min(y)#出现值i最小的index
b = max(y)#出现值i最大的index
#记录一次用水的开始事件编号、结束事件编号
stui= df2.index[a]
enui= df2.index[b]
stUI.append(stui)
enUI.append(enui)
#记录一次用水开始时间、结束时间
stu = df2.iloc[a,0]-ds/2 # 设置用水开始时间=起始数据时间-发送阈值/2
enu = df2.iloc[b,0]+ds/2 # 设置结束用水时间=结束数据时间+发送阈值/2
startU.append(stu)
endU.append(enu)
#记录一次用水总时长
allut = enu-stu
allUT.append(allut)
#判断停顿的行数(一次事件中水流量为0的记录的条数)
stpts = df2.iloc[a:b+1,:]
f =list(stpts[u'水流量'])
stpt = f.count(0)#计算空值的个数
stopLines.append(stpt)
n =0
#判断停顿次数,中间有一个或多个空值均算作一次停顿
if a==b :
n=0
else:
tgap = df2.iloc[a:b+1,:]
for t in range(a,b):
g = tgap.ix[df2.index[t],[u'水流量']].values
g1 = tgap.ix[df2.index[t+1],[u'水流量']].values
if g1 == 0 and g!= 0:
n+=1
gapTS.append(n)
fdf2['stUseTime'] = startU
fdf2['enUseTime'] = endU
fdf2['stDataIndex'] = stUI
fdf2['edDataIndex'] = enUI
fdf2['AllUseTime'] = allUT
fdf2['gapTimes'] =gapTS
# 将一次用水事件的总时间转成以秒计
fdf2['AllUseTime(s)']= fdf2['AllUseTime']/np.timedelta64(1, 's')
fdf2['stopLines']= stopLines1.2.2 构造属性第二部分
获取用水的时间点的小时数,即洗浴时间点
fdf2['WashHour'] = np.nan
for i in range(1,len(fdf2['stUseTime'])+1):
temp = fdf2.ix[i,'stUseTime'].strftime('%Y-%m-%d %H:%M:%S')# 将时间格式转成字符串,通过字符串截取获得时间点
c = temp[11:13]
d =int(c)
fdf2.ix[i,'WashHour'] = d1.2.3 属性构造第三部分
确定一次用水时间和停顿时间、总用水量、水流量波动、平均用户水量
fdf2['UseTime'] = np.nan # 用水时间
fdf2['GapTime'] = np.nan # 停顿时间
fdf2['w_water'] = np.nan # 总用水量
fdf2['flow_volatility'] = np.nan # 水流量波动
fdf2['water_rate'] = np.nan #平均用水量
# 计算停顿时间(具体所有方法见time_gap_compute.py,此处采用的是第二种方法)
def gap_time_2(y):
gap_time_2 = pd.Timedelta(seconds = 0)
templist = []
allgap = 0
# 获取一次用水时间中间隔的行编号
for i in range(len(y)):
if y.iloc[i,6] == 0:
templist.append(i)
# 计算停顿时间
if (len(y) ==1) | (templist==[]):# 如果该事件只有一个或者两个非零用水记录,直接让用水停顿时间等于0
gap_time_2 = gap_time_2
else:
for j in templist:# 采用书上公式:每条用水数据时长的和=(和上条数据的间隔时间/2+和下条数据的间隔时间/2)的和
gap_time_2 = gap_time_2 + y.iloc[j,-1]/2 + y.iloc[j+1,-1]/2
gap_time = gap_time_2/np.timedelta64(1,'s')
return gap_time
# 计算用水时间 和 总用水量
def use_time(y):
send_time = pd.Timedelta(seconds = 2) # 定义信息发送延迟时间为2秒
use_time = pd.Timedelta(seconds = 0)
templist = []
w_water = 0 # 记录总用水量
# 获取一次用水时间用水的行编号
LASTIME = []#记录每个用水记录的持续用水时间
for i in range(len(y)):# 将所有用水量不为0的记录的行号进行记录
if y.iloc[i,6] != 0:
templist.append(i)
if len(y) ==1:# 如果用水量不为0的仅为1条,则用水时间为发送时间,用水持续时间为发送时间
use_time = send_time
lastime = send_time
w_water = lastime/np.timedelta64(1,'s')* y.iloc[0,6]# 该次用水量为用水持续时间*水流量
LASTIME.append(lastime/np.timedelta64(1,'s'))
else:
lastime = pd.Timedelta(seconds = 0)#用水时间=每条用水数据时长的和=(和上条数据的时间间隔/2+和下条数据的时间间隔/2)的和
for j in templist:
if j == 0:# 每一个用水事件开始时刻的用水持续时间=和下条数据的时间间隔/2+发送时间/2
lastime = y.iloc[j+1,-1]/2 + send_time/2
elif j == (len(y)-1):#每一个用水事件最后时刻的用水持续时间=和上条数据的时间间隔/2+发送时间/2
lastime = y.iloc[j,-1]/2 + send_time/2
else:
lastime = y.iloc[j,-1]/2 + y.iloc[j+1,-1]/2
use_time = use_time + lastime
w_water = w_water + lastime/np.timedelta64(1,'s')* y.iloc[j,6]
LASTIME.append(lastime/np.timedelta64(1,'s'))
usetime = use_time/np.timedelta64(1,'s')
avg = w_water/usetime# 平均水流量=总用水量/总用水时间
allwater = 0 # 计算水流量波动 = sum((单次水流的值-平均水流量)**2*持续时间)/总用水时间
if len(y) ==1:
allwater = (y.iloc[0,6]-avg)**2
else:
for i in range(len(templist)):
allwater = allwater + LASTIME[i]*(y.iloc[templist[i],6]-avg)**2
flow_vola = allwater/100/usetime# 水流量波动 # 此处除以100为了让数字看起来正常点,符合原作者给出的配书中给的数据值
return usetime, w_water/100, avg, flow_vola
useTIME = []# 用水时间
gapTIME = []# 间隔时间
w_wat = []# 总用水量
flow_volatility = []# 水流量波动
avg_water_rate = [] # 平均水流量
for n in range(1,int(MX+1)):
gp= gap_time_2(df2[df2[u'事件编号'] == n])
use,w_water,avg,flow_vola = use_time(df2[df2[u'事件编号'] == n])
gapTIME.append(gp)
useTIME.append(use)
w_wat.append(w_water)
flow_volatility.append(flow_vola)
avg_water_rate.append(avg)
fdf2['GapTime'] = gapTIME
fdf2['UseTime'] = useTIME # fdf2['AllUseTime(s)']- fdf2['GapTime']
fdf2['w_water'] = w_wat
fdf2['water_rate'] = avg_water_rate
fdf2['flow_volatility'] = flow_volatility
fdf2.head()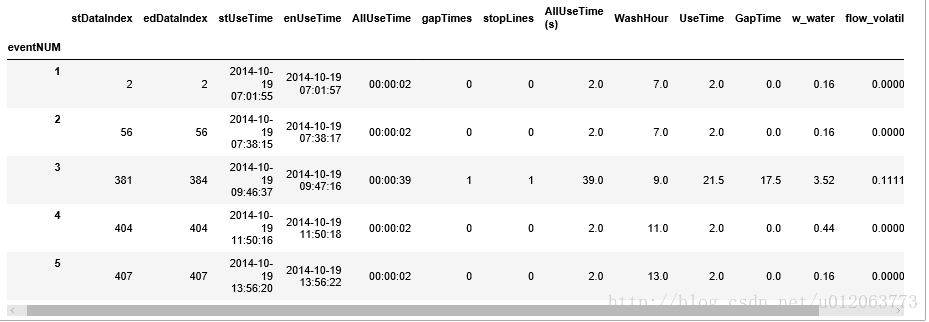
1.2.4 构造属性第四部分
计算停顿时长波动
fdf2['pause_volatility'] = np.nan
pause_volatility = [] # 停顿时长波动
# 获取事件编号为eventnum的停顿次数
def get_gaptimes(eventnum):
return fdf2['gapTimes'][eventnum]
# 计算得出停顿时间和停顿时长波动(具体所有方法见time_gap_compute.py,此处采用的是第一种方法),因为这样可以算出单次停顿的具体时间
# 停顿时长波动=sum((单次停顿时长-平均停顿时长)**2*持续时间)/总停顿时间
def gap_time(x,gapTimes):
gap_time = pd.Timedelta(seconds = 0)
GAPTIME = []
pause_vola = 0
if len(x) ==1:
gap_time = gap_time
pause_vola = 0
else:
i=0
tempdf = DataFrame([])
while i< len(x)-1:
i= i+1
if (x.loc[x.index[i],u'水流量']) == 0:#若第i条水量为0
tempdf = tempdf.append(x.ix[x.index[i],:])# 存储所有水流量为0的数据的记录
if (x.loc[x.index[i+1],u'水流量']) != 0:# 若第i+1条水量不为0,说明这是一次停顿的结束
start = tempdf.loc[tempdf.index[0],u'发生时间'] # 计算该次停顿的开始时刻
end = tempdf.loc[tempdf.index[-1],u'发生时间'] # 计算该次停顿的结束时刻
b = list(x.index).index(tempdf.index[0])-1# 获取该次停顿发生的前一个用水量非0的记录的index
start_gap = x.iloc[b,0]
c = list(x.index).index(tempdf.index[-1])+1# 获取该次停顿结束的后一个用水量非0的记录的index
end_gap = x.iloc[c,0]
# print start_gap,start,end,end_gap
tempdf = DataFrame([]) # 清空tempdf,以记录下一次停顿时间
t1 = (start-start_gap)/2 # 停顿开始时与上一条非零数据的时间间隔/2
t2 = (end_gap-end)/2# 停顿结束时与下一条非零数据的时间间隔/2
t3 = end-start # 中间停顿时间
t = t1+t2+t3
# print t1,t2,t3,t
gap_time = gap_time+t
GAPTIME.append(t/np.timedelta64(1,'s'))#将每一小段的停顿时间存入,以计算停顿时长波动
gap_time = gap_time/np.timedelta64(1,'s') # 将停顿时间转成“秒”
# 计算平均停顿时间 = 总停顿时间/停顿次数
if gapTimes != 0:# 若停顿次数不为0
avg = gap_time/gapTimes
else:# 若停顿次数为0,则平均停顿时间等于停顿的时间
avg = gap_time
Allgap=0# 所有的停顿时间
for i in range(len(GAPTIME)):
Allgap = Allgap + GAPTIME[i]*(GAPTIME[i]-avg)**2
pause_vola = Allgap/gap_time# 水流量波动
return gap_time, pause_vola
for n in range(1,MX+1):
gp, pause_vola = gap_time(df2[df2[u'事件编号'] == n], get_gaptimes(n))
pause_volatility.append(pause_vola)
fdf2['pause_volatility'] = pause_volatility
fdf2.head()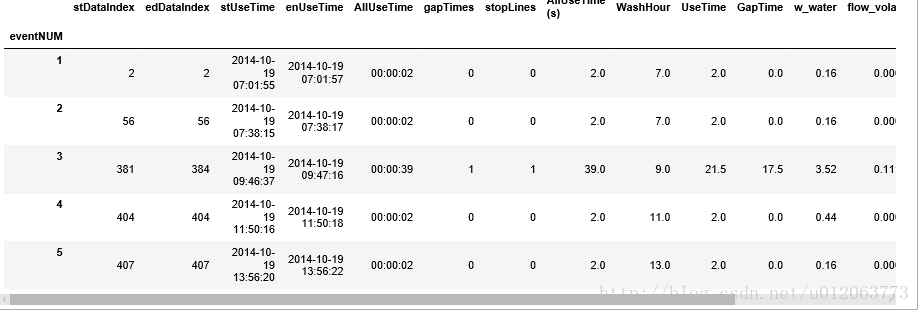
1.2.5 构造属性第五部分
一次用水事件中,用水时长的所占比重
fdf2['use_water_rate'] = fdf2['UseTime']/fdf2['AllUseTime(s)']
# 平均停顿时间
# fdf2['avg_pause_time'] = fdf2['GapTime']/fdf2['gapTimes']# 不能这样除,除数可能为0
fdf2['avg_pause_time'] = np.nan
for i in range(1,len(fdf2)+1):
if fdf2.ix[i,['gapTimes']].values[0] != 0:
fdf2.ix[i,['avg_pause_time']] = fdf2.ix[i,['GapTime']].values[0] / fdf2.ix[i,['gapTimes']].values[0]
else :
fdf2.ix[i,['avg_pause_time']] = 0
fdf2.head()此处不放截图了,反正也看不全。。。
1.3 属性构造结束
属性构造结束,将各列重命名,然后保存
# 属性构造结束,将各列重命名,然后保存
fdf2.rename(columns={'stDataIndex':u'起始数据编号','edDataIndex':u'终止数据编号','stUseTime':u'开始时间','enUseTime':u'结束时间',\
'AllUseTime':u'总用水时长(w_time)', 'gapTimes':u'停顿次数(pause)','stopLines':u'停顿行数','AllUseTime(s)':\
u'所有使用时间总用水时长(s)','WashHour':u'洗浴时间点','UseTime':u'用水时长(use_water_time)','GapTime':\
u'总停顿时长(w_pause_time)','w_water':u'总用水量(w_water)','flow_volatility':u'水流量波动(flow_volatility)',\
'water_rate':u'平均水流量(water_rate)','use_water_rate':u'用水/总时长(use_water_rate)','avg_pause_time':\
u'平均停顿时长(avg_pause_time)','pause_volatility':u'停顿时长波动(pause_volatility)'},inplace='True' )
fdf2.index.name=u'事件编号'
fdf2.to_excel('attrConst_results.xlsx')
2 筛选得“候选洗浴事件”
接下来进行数据处理和筛选得到“候选洗浴事件,用于接下来的模型构建
# 去掉 用水时长小于100秒
# 去掉 总用水时长小于120秒
# 去掉 一次用水事件中总用水量(纯热水)小于10升
data_filter = fdf2[(fdf2[u'所有使用时间总用水时长(s)']>=120) & (fdf2[u'总用水量(w_water)']>=10) & (fdf2[u'用水时长(use_water_time)']>=100)]
data_filter.to_excel('data_filter.xlsx')
# data_filter.iloc[:3]
data_filter.head(3)备注:文中在这一步骤之后进行了数据清洗的工作,旨在补充缺失的数据状态,但是,本人认为,该意义不大,因此没有进行该操作,若是有路过的朋友对待这一步操作有不同的意见和建议,欢迎留言。
3 构建模型
# 目标:判断是否是洗浴事件,是则1,不是则0
# 建立、训练多层神经网络 并完成模型的检验
# 选取”候选洗浴事件“的11个属性作为网络的输入,分别为:洗浴时间点、总用水时长、总停顿时长、平均停顿时长、停顿次数、
# 用水时长、用水时长/总用水时长、总用水量、平均水流量、水流量波动和停顿时长波动
备注:
# 由于此单元的中间数据处理原书中存在一定问题,所以此处采用书中给的训练数据,和测试数据,旨在测试模型在此数据上的效果
from __future__ import print_function
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
inputfile1 = 'train_neural_network_data.xls' # 训练数据
inputfile2 = 'test_neural_network_data.xls' # 测试数据
testoutputfile = 'test_output_data.xls' #测试数据模型输出文件
data_train = pd.read_excel(inputfile1) # 读入训练数据
data_test = pd.read_excel(inputfile2) # 读入测试数据x_train = data_train.iloc[:,5:17].as_matrix() # 训练样本特征
y_train = data_train.iloc[:,4].as_matrix() # 训练样本标签列
x_test = data_test.iloc[:,5:17].as_matrix() # 测试样本特征
y_test = data_test.iloc[:,4].as_matrix() # 训练样本标签列# 训练神经网络时,对神经网络的参数进行寻优,发现含两个隐含层的神经网络训练效果较好
# 其中两个隐层的节点数分别为17和10时训练效果较好
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
netfile = 'net.model'# 构建的神经网络模型存储路径
model = Sequential() # 建立模型
model.add(Dense(units=17, input_dim=11)) # 添加输入层、隐藏层的连接
model.add(Activation('relu')) # 以relu函数为激活函数
model.add(Dense(units=10, input_dim=17)) # 添加隐藏层、二层隐藏层的连接
model.add(Activation('relu')) # 以relu函数为激活函数
model.add(Dense(units=1, input_dim=10)) # 添加二层隐藏层、输出层的连接
model.add(Activation('sigmoid')) # 以sigmoid函数为激活函数
# 编译模型,损失函数为binary_crossentropy,用adam法求解
model.compile(loss = 'binary_crossentropy', optimizer = 'adam')
model.fit(x_train, y_train, nb_epoch = 1000, batch_size = 1)
model.save_weights(netfile)# 保存模型参数
predict_result_train = model.predict_classes(x_train).reshape(len(data_train)) #给出预测类别(训练集)
from cm_plot import * # 从编写好的包中导入画图函数
cm_plot(y_train, predict_result_train).show() #显示混淆矩阵可视化结果 看训练结果正确率
from sklearn.metrics import confusion_matrix
predict_result_test = model.predict_classes(x_test).reshape(len(data_test)) #给出预测类别(测试集)
from cm_plot import *
cm = confusion_matrix(y_test, predict_result_test)
cm_plot(y_test, predict_result_test).show() #显示混淆矩阵可视化结果 看训练结果正确率

from __future__ import division
correctRate = (cm[1,1] + cm[0,0]) / cm.sum()
correctRate0.80952380952380953
r = DataFrame(predict_result_test, columns = [u'预测结果']) # 给出预测类别测试集
# predict_rate = DataFrame(model.predict(x_test), columns = [u'预测正确率']) # 给出预测类别测试集
res = pd.concat([data_test.iloc[:,:5],r], axis=1)#测试集
res.to_excel(testoutputfile)
res

至此,文章中提到的分析已经结束。
备注:本章节完整代码详见点击打开链接
=======================================================================
Ps: 博主在计算不同热水事件间的时间间隔的时候,采用了多种不同的计算方式得到结果,有感兴趣的同学,可看一下。详见链接代码中的2_3_1time_gap_compute.py
文中给出的计算时间间隔的方法: 与上条不为0的数据的间隔/2 + (本段间隔结束时间-本段间隔开始时间) + 与下条不为0的数据的间隔/2
import pandas as pd
import numpy as np
from pandas import DataFrame
inputfile = 'data_exchange_divideEvent.xlsx'
data = pd.read_excel(inputfile)
inputfile1 = 'data_guiyue.xlsx'
data1 = pd.read_excel(inputfile1)
x = pd.merge(data1,data[[u'用水停顿时间间隔',u'事件编号']],left_index = True, right_index=True,how='outer')
x.to_excel('attr_const_for_gap.xlsx')
ifile = 'attr_const_for_gap.xlsx'
df = pd.read_excel(ifile)
# 将数据划分成一次用水事件!(*****)
l=list(df[u'事件编号'])
Adf = DataFrame([], columns = df.columns)# 创建一个空列表
pos=-1
MX = int(df[u'事件编号'].max())
for j in range(MX):
y = []
for i in range(l.count(j+1)):
pos=l.index(j+1,pos+1)
y.append(pos)
a = min(y)
b = max(y)
temp = df.iloc[a:b+1,:]
Adf = pd.concat([Adf,temp])
Adf[u'事件编号'].fillna(method='ffill',inplace = True)
Adf[[u'水流量']] = Adf[[u'水流量']].astype('float64')
Adf['gap'] = Adf[u'发生时间'].diff()
Adf.to_excel('gap_time_compute.xlsx')
data_all = Adf
#-----*第 1 种方法*-----
def gap_time(x):
gap_time = pd.Timedelta(seconds = 0)
if len(x) ==1:
gap_time = gap_time
else:
i=0
tempdf = DataFrame([])
while i< len(x)-1:
i= i+1
if (x.loc[x.index[i],u'水流量']) == 0:
tempdf = tempdf.append(x.ix[x.index[i],:])
if (x.loc[x.index[i+1],u'水流量']) != 0:
start = tempdf.loc[tempdf.index[0],u'发生时间']
end = tempdf.loc[tempdf.index[-1],u'发生时间']
b = list(x.index).index(tempdf.index[0])-1
start_gap = x.iloc[b,0]
c = list(x.index).index(tempdf.index[-1])+1
end_gap = x.iloc[c,0]
# print start_gap,start,end,end_gap
t1 = (start-start_gap)/2
t2 = (end_gap-end)/2
t3 = end-start
t = t1+t2+t3
# print t1,t2,t3,t
gap_time = gap_time+t
tempdf = DataFrame([])
gap_time = gap_time/np.timedelta64(1,'s') # 将间隔时间转成“秒”
return gap_time
dt_list = []
for n in range(1,int(data_all[u'事件编号'].max())+1):
dt = gap_time(data_all[data_all[u'事件编号'] == n] )
dt_list.append(dt)
print dt_list#-----*第 2 种方法*-----
# 第二种方法:
def gap_time_2(y):
gap_time_2 = pd.Timedelta(seconds = 0)
templist = []
for i in range(len(y)):
if y.iloc[i,6] == 0:
templist.append(i)
if (len(y) ==1) | (templist==[]):
gap_time_2 = gap_time_2
else:
for j in templist:
gap_time_2 = gap_time_2 + y.iloc[j,-1]/2 + y.iloc[j+1,-1]/2
return gap_time_2/np.timedelta64(1,'s')
gp_list = []
for n in range(1,int(data_all[u'事件编号'].max())+1):
gp = gap_time_2(data_all[data_all[u'事件编号'] == n] )
gp_list.append(gp)
print gp_list
# 计算用水时间
def use_time(y):
send_time = pd.Timedelta(seconds = 2)
use_time = pd.Timedelta(seconds = 0)
templist = []
for i in range(len(y)):
if y.iloc[i,6] != 0:
templist.append(i)
if len(y) ==1:
use_time = send_time
else:
for j in templist:
if j == 0:
use_time = use_time + y.iloc[j+1,-1]/2 + send_time/2
elif j == (len(y)-1):
use_time = use_time + y.iloc[j,-1]/2 + send_time/2
else:
use_time = use_time + y.iloc[j,-1]/2 + y.iloc[j+1,-1]/2
return use_time/np.timedelta64(1,'s')
dt_list = []
for n in range(1,int(data_all[u'事件编号'].max())+1):
dt = use_time(data_all[data_all[u'事件编号'] == n] )
dt_list.append(dt)
print dt_list
df2 = data_all
# 确定一次用水时间和停顿时间
dtest = DataFrame(df2[[u'事件编号',u'水流量']],columns=[u'事件编号',u'水流量'])
dtest['realindex'] = range(len(df2[u'事件编号']))
dtest
l=list(dtest[u'事件编号'])
pos=-1
useTIME = []
gapTIME = []
for j in range(int(data_all[u'事件编号'].max())):
TIME = pd.Timedelta(seconds = 0)
y = []
for i in range(l.count(j+1)):
pos=l.index(j+1,pos+1)
y.append(pos)
a = min(y)#出现值i最小的index````````
b = max(y)#出现值i最大的index
n =0
tgap = dtest.iloc[a:b+1,:]
# print tgap
TG = tgap[tgap[u'水流量']==0]
if (a==b) | (len(TG)==0):
TIME = TIME
else:
th = 1
d = TG['realindex'].diff() > th
TG[u'tgtimes'] = d.cumsum() + 1
z = list(TG[u'tgtimes'])
OP = []
pos1=-1
for m in range(TG[u'tgtimes'].max()):
y1 = []
for m1 in range(z.count(m+1)):
pos1 =z.index(m+1,pos1+1)
y1.append(pos1)
c = min(y1)#出现值i最小的index````````
d = max(y1)#出现值i最大的index
c0 = TG.index[c]
c1 = list(df2.index).index(c0)
c2 = c1-1
d0 = TG.index[d]
d1 = list(df2.index).index(d0)
d2 = d1+1
# print c,d,c0,d0,c1,d1,c2,d2
stu1 = (df2.iloc[c1,0]-df2.iloc[c2,0])/2# 设置用水开始时间=起始数据时间-发送阈值/2
enu1 = (df2.iloc[d2,0]-df2.iloc[d1,0])/2# 设置用水开始时间=起始数据时间-发送阈值/2
meu1 = df2.iloc[d1,0]-df2.iloc[c1,0]
tempgap = enu1+stu1+meu1
TIME = TIME + tempgap
gaptime= TIME/np.timedelta64(1, 's')
gapTIME.append(gaptime)
print gapTIME