我用Paddle Lite在树莓派3b+上从零开始搭建“实时表情识别”项目
点击左上方蓝字关注我们

【飞桨开发者说】孙飘宇:OPPO软件工程师,毕业于中南大学,第十四届全国大学生智能汽车竞赛一等奖。

项目简介
本项目搭建的表情识别系统,是包含了多门学科知识的深度学习应用。在实际生活中,表情识别在人机交互、安全、机器人制造、无人驾驶和医疗都有着一定的作用。本项目实践的是基于嵌入式系统的表情识别系统的设计方法,将图像采集、人脸检测、表情识别和结果输出整合到树莓派中。
项目使用USB摄像头实时采集数据,利用PyramidBox算法在复杂环境下检测人脸,将检测到的人脸截取,使用飞桨(PaddlePaddle)搭建MobileNetV2深度学习网络,使用fer2013数据集训练模型,并对截取的人脸进行表情分类,最后将模型转化,使用飞桨轻量化推理引擎Paddle Lite部署到Raspberry Pi 3B+中,实现实时表情识别。
从模型训练到部署,飞桨都有成熟的配套工具和流程,大大降低了项目开发的时间成本。最终效果如何?怎么做的呢?且看接下来的详细分解。
数据集及模型评估
其中训练模型的数据是Kaggle ICML2013 fer2013人脸表情识别数据集,总数据量35866。将csv数据转图片后分别保存在不同类别的文件夹即可用来训练模型。项目选取happy、normal、surprised和angry四种类别辨识度较高的数据。
读者可以自行添加其他的表情类别。数据按照70%、20%和10%的比例切分为训练集、验证集和测试集。训练集用于模型参数训练,验证集评估模型预测准确率,测试集在生成模型后使用,直观的感受模型效果。该数据集的图片数据,均为48*48的单通道数据。
训练好的MobileNetV2和DenseNet121模型,top1准确率分别为85.33%和87.50%。在树莓派3b+中,单张图片处理耗时30ms,整个项目在树莓派3b+中的fps为20~30。
最终效果(截取视频)




项目过程回放如下:
树莓派环境搭建
首先,搭建好程序运行的环境。模型最终部署在树莓派3b+中,其环境要求如下:
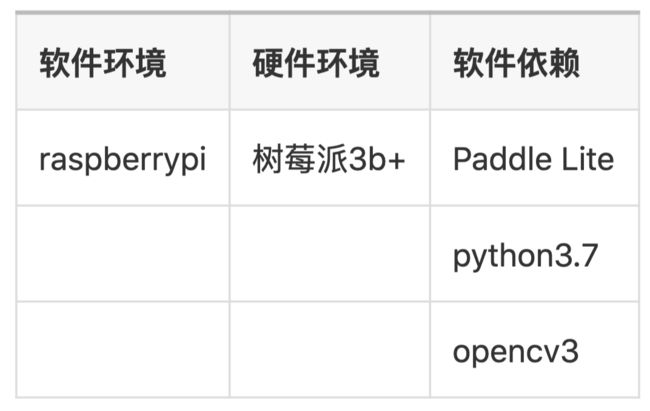
树莓派的系统推荐安装raspberrypi,官网即可下载系统镜像(https://www.raspberrypi.org/downloads/)
同时,项目需要调用opencv,推荐官网下载源码放入树莓派编译(https://opencv.org/releases/)
树莓派Paddle Lite编译步骤
在树莓派中进行模型预测,需要安装飞桨轻量化推理引擎Paddle lite。Paddle Lite支持包括手机移动端、嵌入式端在内的多种端侧场景的轻量化高效推理,支持广泛的硬件和平台,是一个高性能、轻量级的深度学习推理引擎。除了支持Paddle模型,也可以通过X2Paddle工具转换支持TensorFlow,PyTorch,Caffe等其他框架产出的模型。完整使用文档位于:
https://paddle-lite.readthedocs.io/zh/latest/user_guides/model_optimize_tool.html
1.准备编译环境
gcc、g++、git、make、wget、python
cmake(建议使用3.10或以上版本)
具体步骤:
# 1. Install basic softwareapt updateapt-get install -y --no-install-recomends \ gcc g++ make wget python unzip
# 2. install cmake 3.10 or abovewget https://www.cmake.org/files/v3.10/cmake-3.10.3.tar.gztar -zxvf cmake-3.10.3.tar.gzcd cmake-3.10.3./configuremakesudo make install
可通过cmake --version查看cmake是否安装成功。 至此,完成 Linux 交叉编译环境的准备。
2.编译Paddle Lite
下载代码:
git clone https://github.com/PaddlePaddle/Paddle-Lite.gitcd Paddle-Litegit checkout v2.6.1
编译:
./lite/tools/build_android.sh --arch=armv7hf
至此,树莓派的环境搭建完成,开始进行模型训练。项目的数据准备、网络搭建、模型训练步骤均在百度AI Studio一站式开发实训平台完成,无需搭建训练环境。项目地址:
https://aistudio.baidu.com/aistudio/projectdetail/439995
模型训练
解压数据集并通过代码生成训练集文件夹、测试集文件夹以及相应的路径txt文件。随机读取表情数据并存放在训练集、测试集文件夹中。
img = Image.open(os.path.join(image_path_pre, file)) if random.uniform(0, 1) <= train_ratio: shutil.copyfile(os.path.join(image_path_pre, file), os.path.join(train_image_dir, file)) train_file.write("{0}\t{1}\n".format(os.path.join(train_image_dir, file), label_id)) else: shutil.copyfile(os.path.join(image_path_pre, file), os.path.join(eval_image_dir, file)) eval_file.write("{0}\t{1}\n".format(os.path.join(eval_image_dir, file), label_id))
对数据进行预处理后,就开始搭建网络,训练网络。项目使用的网络是MobileNetV2,使用save_inference_model接口将模型保存为可预测的模型:
fluid.io.save_inference_model(dirname=train_parameters['save_freeze_dir'], feeded_var_names=['img'], target_vars=[out], main_program=main_program, executor=exe)
训练好的模型文件保存在fer_model文件夹中,模型格式为Seperated Param,即参数信息分开保存在多个参数文件中,模型的拓扑信息保存在__model__文件中。训练好模型后可以运行eval.py文件评估模型。
模型转化
PaddlePaddle训练好的模型保存在fer-model文件夹中,保存格式是Seperated Param,这种格式的模型需要使用opt工具转化后才能成为Paddle lite可以预测的模型。
opt(opt完整文档:https://paddle-lite.readthedocs.io/zh/latest/user_guides/model_optimize_tool.html)主要执行量化、子图融合、Kernel优选等等模型优化手段,优化后的模型更轻量级,耗费资源更少,从而执行速度也更快;可以将PaddlePaddle的模型格式转化为Paddle Lite 支持的.nb格式模型。
opt是 x86 平台上的可执行文件,需要在PC端运行,支持Linux终端和Mac终端。也可以使用AI studio来完成转化工作。使用pip安装Paddle-Lite opt工具(需要在x86 PC端安装,支持x86 Linux和Mac上安装):
pip install paddlelite
安装成功后,运行下方指令,转化模型文件:
paddle_lite_opt --model_dir=./fer-model \ --valid_targets=arm \ --optimize_out_type=naive_buffer \ --optimize_out=fer_opt
转化结果为:fer_opt.nb 文件
树莓派项目部署
完整项目文件fer_detection.zip已经上传AI Studio:
https://aistudio.baidu.com/aistudio/projectdetail/439995
下载fer_detection.zip,放入树莓派中解压,项目文件结构如下:

将训练好的模型fer_opt.nb放入model文件夹中,并且修改run_camera.sh文件中的模型名称,在终端执行:
cd fer_detectionsudo ./run_camera.sh
即可运行表情识别项目。
关键代码展示
指定模型文件,配置构建轻量级PaddlePredictor:
//人脸检测模型配置 MobileConfig config; //设置工作线程数 config.set_threads(CPU_THREAD_NUM); //设置CPU能耗模式 config.set_power_mode(CPU_POWER_MODE); //设置模型文件夹路径,加载老格式模型的接口。加载人脸检测模型(pymidbox模型) config.set_model_dir(detect_model_dir); //表情识别模型配置 MobileConfig config2; config2.set_threads(CPU_THREAD_NUM); config2.set_power_mode(CPU_POWER_MODE); //设置模型文件,加载表情识别模型 config2.set_model_from_file(classify_model); // 创建检测模型预测器 std::shared_ptr predictor = CreatePaddlePredictor(config); // 创建分类模型预测器 std::shared_ptr predictor2 = CreatePaddlePredictor(config2);
读取摄像头数据:
cv::VideoCapture cap(-1); cap.set(CV_CAP_PROP_FRAME_WIDTH, 640); cap.set(CV_CAP_PROP_FRAME_HEIGHT, 480); cv::Mat input_image; cap >> input_image;
执行预测:
cv::Mat img =RunModel(input_image,predictor,predictor2); cv::Mat RunModel(cv::Mat img, std::shared_ptr &predictor, std::shared_ptr &predictor2) { //部分代码 //设置输入,检测人脸 std::unique_ptr input_tensor0(std::move(predictor->GetInput(0))); input_tensor0->Resize({1, 3, s_height, s_width}); auto* data = input_tensor0->mutable_data(); //执行预测 predictor->Run(); //获得结果,即人脸的位置信息。 std::unique_ptr output_tensor0( std::move(predictor->GetOutput(0))); auto* outptr = output_tensor0->data(); auto shape_out = output_tensor0->shape(); int64_t out_len = ShapeProduction(shape_out); //表情分类输入为人脸检测结果,代码类似。 }
设置开机自启
个人感觉树莓派开机后表情识别程序自启动会更方便,所以这里提供一种开机自启方法。
1.打开lxtermial输入:
cd .config/autostartnano fer.desktop
2.输入代码:
[Desktop Entry]Comment=my programExec=lxterminal --working-directory=/home/pi/fer_detection/code/ --command=./run_camera.shTerminal=flaseMultipleArgs=falseType=ApplicationName=ferCategories=Application;Development;StartupNotify=true
3.ctrl+o、回车保存ctrl+x退出
sudo reboot
总结
本项目使用了百度的飞桨开源框架,在AI Studio上完成了项目的训练、模型转化等工作。飞桨让深度学习技术的创新与应用更简单,它的上手难度低,从编程到部署,整个流程简单快捷。使用飞桨后我最大的感受是百度飞桨为开发者提供了免费的开发平台和完备的开发工具,并且开发者可以零距离的和飞桨团队沟通,请教开发过程中遇到的问题。在项目遇到了一些困难的时候,飞桨详细的使用文档,以及飞桨团队给了我帮助和解答。
由于个人的需求,目前本项目可以很好的识别四种表情,如果读者想要识别更多的表情,可以通过增加数据集的表情分类来实现,开发流程与本文介绍的一致。
完整项目包括训练文件、移动端文件公开在AI Studio上,欢迎Fork。
https://aistudio.baidu.com/aistudio/projectdetail/439995
如在使用过程中有问题,可加入飞桨推理部署QQ群交流:959308808。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:
https://www.paddlepaddle.org.cn
飞桨开源框架项目地址:
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle
END
