数据库系统概念读书笔记——实体-联系模型
前言
为了重新回顾我写的消息系统架构,我需要重新读一下数据库系统概念的前三章,这里简单的做一个笔记,方便自己回顾
基本概念
实体-联系(E-R)数据模型基于对现实世界的这样一种认识:世界由一组称为实体的基本对象及这些对象间的联系组成。E-R数据模型所采用的三个主要概念是:实体集、联系集和属性
实体集
实体是现实世界中可区别于其他对象的“事件”或“物体”
实体集是具有相同类型及共享相同性质(或属性)的实体集合
实体通过一组
属性来表示。属性是实体集中每个成员具有的描述性质。将一个属性赋予某实体集表明数据库为实体集中每个实体存储相似的信息,但每个实体在自己的每个属性上都有各自的值。属性类型划分:
- 简单属性和符合属性
- 单值属性和多值属性
- 派生属性
联系集
联系是多个实体间的相互关联
联系集是同类型联系的集合。规范的说,联系集是n(n >= 2)个实体集上的数学关系,这些实体集不必互异。如果E1, E2, ..., En为n个实体集,那么联系集R是{(e1,e2,e3,..,en)|e1 (- E1, e2 (-E2, ..., en (- En}的一个子集,其中(e1, e2, e3,...,en)是一个联系
约束
有了实体集合,有了联系集合,自然而然的就产生出来约束,约束描述的是实体集和实体集之间的关系,而这种关系具现为一个联系集。我们要讨论的是
映射基数和
参与约束
映射基数
映射基数,或基数比例,指明通过一个联系集能同时与另一个实体相联系的实体数目
对于实体集A和B之间的二元联系集R来说,映射基数必然是以下情况之一:
- 一对一
- 一对多
- 多对一
- 多对多
参与约束
如果实体集E中的每一个实体都参与到联系集R的至少一个联系中,我们称实体集E全部参与联系集R
如果实体集E中只有部分实体参与到联系集R的联系中,我们称实体集E部分参与联系集R
码
我们必须有一个能区分一个实体集中的所有实体的方法。概念上来说,各个实体是互异的;但从数据库的观点来看,它们的区别必须用其属性来表明
码概念使得我们可以区别实体,码同样可以唯一地标识联系,并将联系互相区分开来
- 超码:一个或多个属性的集合,这些属性的组合可以使我们在一个实体集中唯一地标识一个实体
- 候选码:任意真子集都不能称为超码的超码,也就是最小的超码
- 主码:数据库设计者选定的候选码
设计问题
实体集和联系集的概念并不精确,而且定义一组实体及它们的相互联系可以有多种不同的方式
用实体集还是属性
书里的电话号码和姓名的例子很清楚,哪个为属性哪个为实体集,
注意两点常见的错误:
- 一个常见的错误是用实体集的主码作为另一个实体集的属性,而不是用联系
- 另一个常见的错误是将有关系的实体集的主码属性作为联系集的属性
用实体集还是联系集
用联系集可能产生的两个问题:
- 数据多次存储,浪费存储空间
- 更新可能使数据处于不一致的状态,即两个联系中应该具有相同值的属性具有了不同的值
二元联系集与n元联系集
n元关系可以分解成为二元关系,但是会出现关系描述不准确的情况
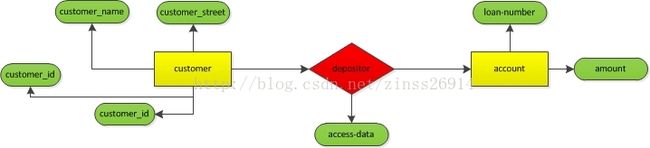
实体-联系图
E-R图包括如下几个主要组件:
- 矩形:实体集
- 椭圆:属性
- 菱形:联系集
- 线段:将属性连接到实体集或将实体集连接到属性集
- 双椭圆:多值属性
- 虚椭圆:派生属性
- 双矩形:弱实体集
举个书上的例子:
数据库规范化
数据库规范化,又称数据库或资料库的正规化、标准化,是数据库设计中的一系列原理和技术,以减少数据库中数据冗余,增进数据的一致性。关系模型的发明者埃德加.科德最早提出这一概念,并于1970年代初定义了第一范式、第二范式和第三范式的概念,还与Raymond f. Boyce于1974年共同定义了第三范式的改进范式-BC范式
第一范式
第一范式(1NF)是数据库规范化中所使用的一种正规形式。第一范式是为了要排除重复组的出现,所采用的方法是要求数据库的每个字段都只能存放单一值,而且每笔记录都要能利用一个唯一的主键来加以识别
重复组举例:
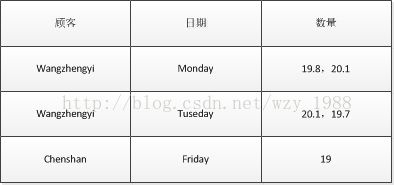
符合第一范式,就需要取消重复组,将数量中的每个数量单独作为一条记录,因为顾客可能会有多次购买记录,因此,需要有主键标识这张表

第二范式
第二范式(2NF)是数据库规范化中使用的一种正规形式。它的规则是要求数据库表里的所有数据都要和该数据表的主键有完全依赖关系;如果有哪些数据只和主键的一部分有关的话,就得把它们独立出来变成另一个数据表。如果一个数据表的主键只有一个单一字段的话,它就一定符合第二范式
示例:
有一个数据表记录了设备组件的信息,如下图所示:

这个数据表的每个字段都是单一值,所以它符合第一范式。因为同一个组件有可能由不能的供应商提供,所以得把组件id和供应商id合在一起组成一个主键
主键和价格之间的关系很正确:同一组件在不同供应商有可能会有不同的报价,所以价格确实和主键完全相关(完全依赖)
另一方面,供应商名称和住址就只和供应商ID有关(部分依赖),这不符合第二范式的原则。最好把供应商名称和地址独立出来变成另一个数据表
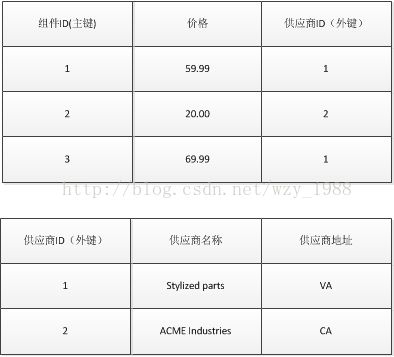
检查数据表里的每个字段,确认它们是不是都和主键完全相关,这样才能知道这个数据表是不是符合第二范式。如果不是的话,就把那些不完全相关的字段移动到独立的数据表里。接下来的步骤是要确保所有不是键的字段和彼此没有相依关系,这就叫做第三范式
第三范式
第三范式是数据库规范化中所使用的一种正规形式,用来检验是否所有非键属性都只和候选键有相关性,也就是说所有非键属性互相之间应该是无关的
满足第三范式(3NF)必须先满足第二范式(2NF)。第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息
所谓传递函数依赖,指的是如果存在“A -> B -> C”的决定关系,则C传递函数依赖于A
因此,满足第三范式的数据库应该不存在如下依赖关系:
关键字段 -> 非关键字段x -> 非关键字段y
假设学生关系表为Student(学号,姓名,年龄,所在学院,学院地点,学院电话),关键字为单一关键字“学号”,因为存在如下决定关系:
(学号) -> (姓名,年龄,所在学院,学院地点,学院电话)
这个数据库是符合2NF的,但是不符合3NF,因为存在如下决定关系:
(学号) -> (所在学院) -> (学院地点,学院电话)
即存在非关键字字段“学院地点”、“学院电话”对关键字字段“学号”的传递函数依赖
把学生关系表分为如下两个表:
学生: (学号,姓名,年龄,所在学院)
学院: (学院,地点,电话)
这样的数据库是符合第三范式的,消除了数据冗余,更新异常,插入异常和删除异常
BCNF
BCNF是在第三范式的基础上,数据库表中如果不存在任何字段对任一候选关键字段的传递函数依赖则符合BCNF范式
假设仓库管理关系表为StorehouseManage(仓库ID,存储物品ID,管理员ID,数量),且有一个管理员只在一个仓库工作;一个仓库可以存储多种物品。这个数据库表中存在如下决定关系:
(仓库ID,存储物品ID) ——> (管理员ID,数量)
(管理员ID,存储物品ID)——> (仓库ID,数量)
所以,(仓库ID,存储物品ID)和(管理员ID,存储物品ID)都是StorehouseManage的候选关键字,表中唯一非关键字段为数量,它是符合第三范式的。但是,由于存在如下决定关系:
(仓库ID)——> (管理员ID)
(管理员ID)——> (仓库ID)
即存在关键字段决定关键字段的情况,所以其符合BCNF范式。它会出现如下异常情况:
四种范式之间存在如下关系:

主键和索引的区别
所谓主键,就是能够唯一标识表中某一行的属性或属性组,一个表只能有一个主键,但可以有多个候选索引。因为主键可以唯一标识某一行记录,所以可以确保执行数据更新、删除的时候不会出现张冠李戴的错误。主键除了上述作用外,常常与外键构成参照完整性约束,防止出现数据不一致的情况
- 主键是唯一性索引,唯一性索引不一定是主键
- 一个表中可以右多个唯一性索引,但只能有一个主键
- 主键列不允许有空值,而唯一性索引列允许有空值
后记
纯粹为了回顾E-R模型和E-R图的画法,比较水,高手可以直接跳过了!