Python爬虫学习-第四篇 Scrapy框架抓取唯品会数据
上篇博文讲述了scrapy的框架和组件,对于scrapy有了基本的了解,那么我们进入今天的正题:使用Scrapy框架爬取数据。
1.创建Scrapy项目
创建Scrapy工程文件的命令:
scrapy startproject scrapytest此命令是python默认目下创建的工程。

指定目录文件下创建项目:
1.进入指定目录 cd D:\workspaces
2.该目录下执行:scrapy startproject scrapytest 2.scrpay项目结构
使用PyCharm,打开scrpy的工程文件,效果如下:
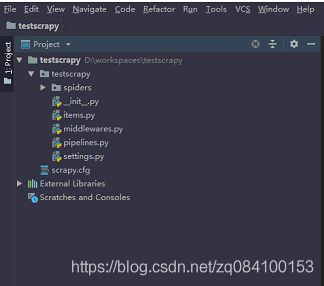
2.1 spiders 文件夹就是我们编写spider存放的目录
2.2 items是定义数据类型
2.3 pipeline 负责处理被spider提取出来的item
2.4 Middlewares 默认两个中间件,一个spider 一个是download
2.5 setting 配置信息 默认:

3.抓取某品会的纸尿裤数据
3.1 定义数据
class DiaperItem(scrapy.Item):
diaper_name = scrapy.Field() #纸尿裤商品名称
diaper_price = scrapy.Field()#价格
diaper_url = scrapy.Field() #详情路径
diaper_source_shop = scrapy.Field() #来源商城(默认为某品会)3.2 抓取目标分析

目标是抓取上图所有的纸尿裤数据。
3.2.1抓取页面代码
通过写spider直接访问路径:https://category.vip.com/suggest.php?keyword=纸尿裤
from scrapy.spiders import Spider
from scrapy.http.request import Request
class vipShopSpider(Spider):
name = "vipshopSpider"
allowed_domains = ["category.vip.com"]
start_url = 'https://category.vip.com/suggest.php?keyword=%E7%BA%B8%E5%B0%BF%E8%A3%A4'
def start_requests(self):
yield Request(url=self.start_url, callback=self.parse)
def parse(self, response):
body = response.body.decode('utf-8')
pass其中name就是爬虫的名称,必有字段
allowed_domains 允许爬去站点的域名,此域名内的访问才算有效。
start_url自定义参数,爬虫开始的爬去的页面路径。
start_request第一次请求,url请求页面路径,callback回调函数。
parse 自定义的方法,用于解析html ,主要爬取规则在这里实现。
通过pycharm 配置参数,调试爬虫,获取响应的内容body,用于我们第二次分析.
配置调试步骤:


填入python命令行路径 和执行scrapy的命令:crawl vipShopSpider
debug运行 ,设置断点,查看body:

复制body ,得到访问结果。经过分析,我们发现body没有商品的信息,得到是一段未经过js渲染的代码:

那该怎么办呢,我们用到与scrpy配套的js渲染中间件splash,通过这个splash,我们可以得到渲染后的body。
安装splash很简单,只需在docker环境 安装splash就可以了(这个不是此篇文章的重点)。具体百度。
splash安装成功后 界面如下:
setting配置splash:
SPLASH_URL = '你的splash的url'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
修改spider:
script = """
function main(splash, args)
splash:go(args.url)
local scroll_to = splash:jsfunc("window.scrollTo")
scroll_to(0, 2800)
splash:set_viewport_full()
splash:wait(5)
return {html=splash:html()}
end
"""
def start_requests(self):
#yield Request(url=self.start_url, callback=self.parse)
yield SplashRequest(url=self.start_url, callback=self.parse, endpoint='execute',
args={'lua_source': self.script})script的lua脚本,作用模拟拖动鼠标到页面最低端,保证页面把当前网页的数据加载完成。
再次debug运行爬虫,抓取body,查看最终的html代码。看到产品名称,价格信息。

3.2.2抓取规则
从html代码中获取到制定数据,selector(选择器)就在这时候大显身手,scapy选择器是依赖于lxml库,在我的博文《Python爬虫学习-第三篇 Scrapy框架初探和安装》提到过,所以在这儿我就不多讲,直接贴出我的筛选规则代码:
def parse(self, response):
sel = Selector(response)
items = sel.xpath('//div[@class="goods-list-item c-goods J_pro_items"]')
for data in items:
diaper_name = data.xpath('.//h4[@class="goods-info goods-title-info"]/a/@title').extract_first()
diaper_price = data.xpath(
'.//div[@class="goods-price-wrapper"]/em/span[@class="price"]/text()').extract_first()
diaper_url = data.xpath('.//h4[@class="goods-info goods-title-info"]/a/@href').extract_first()
shop_diaper_item = DiaperItem()
shop_diaper_item['diaper_name'] = diaper_name
shop_diaper_item['diaper_price'] = (re.findall(r"\d+\.?\d*", diaper_price))[0]
shop_diaper_item['diaper_url'] = 'https:' + diaper_url
shop_diaper_item['diaper_source_shop'] = '唯品会'
yield shop_diaper_item
next_url = sel.xpath(
'//div[@class="m-cat-paging ui-paging"]/a[@class="cat-paging-next next"]/@href').extract_first()
if next_url is not None:
next_url = response.urljoin(next_url)
yield SplashRequest(next_url, callback=self.parse, endpoint='execute', args={'lua_source': self.script}) 第一步: sel = Selector(response)
items = sel.xpath('//div[@class="goods-list-item c-goods J_pro_items"]') 选取class是"goods-list-item c-goods J_pro_items"的元素
第二步:遍历选取的元素,找到名称、价格、详情url,赋值给自定义DiaperItem,返回DiaperItem
第三步:找取下一页:
next_url = sel.xpath(
'//div[@class="m-cat-paging ui-paging"]/a[@class="cat-paging-next next"]/@href').extract_first() 找取分页的下一页href。得到类似的结果:![]()
判断是否为空,不为空,拼接成类似https://category.vip.com/suggest.php?keyword=纸尿裤&page=2&count=100&suggestType=brand#catPerPos的链接
在加入splash的渲染中间件,循环调取。
ps:scrapy 是默认开启了,url去重的访问,所以即使有重复url路径请求,scrapy会自动清除。
3.2.3保存数据
使用pipeline来处理数据,使用mssql数据库来存储数据:
from DiaperService.MssqlService import MssqlService
class DiaperPipeline(object):
def process_item(self, item, spider):
name = item['diaper_name'].replace("'", "''")
ms = MssqlService(server='192.168.200.200', user='sa', password='123456aA', db_name='test')
sql = 'insert into [dbo].[Diaper](Name,Price,DetailUrl,SourceShop) ' \
'values(\'%s\',%f,\'%s\',\'%s\') ' % (name,
float(item['diaper_price']),
item['diaper_url'],
item['diaper_source_shop'])
# print(sql)
ms.exec_non_query(sql)
return item封装的mssql服务:
import pymssql
class MssqlService(object):
def __init__(self, server, user, password, db_name):
self.host = server
self.user = user
self.password = password
self.database = db_name
self.conn = self.__get_Conn()
def __get_Conn(self):
conn = pymssql.connect(self.host, self.user, self.password, self.database)
return conn
def exec_query(self, sql):
cur = self.conn.cursor()
cur.execute(sql)
result_list = cur.fetchall()
cur.close()
return result_list
def exec_non_query(self, sql):
cur = self.conn.cursor()
cur.execute(sql)
self.conn.commit()
cur.close()setting配置pipeline的优先级300:
ITEM_PIPELINES = {
'Diaper.pipelines.DiaperPipeline': 300,
}那么到现在我们已经把爬虫从请求网页,获取相应,解析内容,保存数据的都完成开发,所以我们运行下程序,查看是否成功抓取数据。

数据库中的数据:

4.总结
scrapy还有很多强大的功能去探索,比如链式爬虫,能够递归爬取数据,可以配置递归的层级等。同时它的选择器lxml库,筛选查询非常方便快速,相较于正则表达式学习成本更低,更易理解,能让新手快速入门。