HashMap源码分析(基于JDK1.8)
看到网上对HashMap源码分析的文章很多,大部分概念都是对的,但是没有让人理解哈希表的本质,今天画了一些时间认真的看了一遍HashMap的源码,所以想写下这篇文章总结一下。
先来一张HashMap的底层数据结构图:
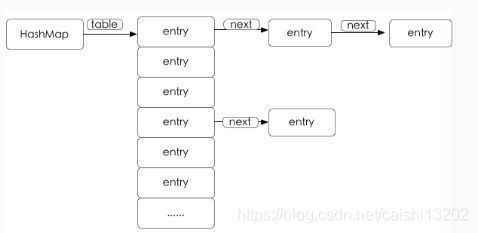
这张图大家是很熟悉的,HashMap底层就是一个Node
//用来存key-value对象
transient Node[] table;
//其中Node是HashMap的一个静态内部类
static class Node implements Map.Entry {
final int hash;
final K key;
V value;
Node next;
...
} HashMap中有几个比较关键的常量需要我们了解一下:
//默认的初始化大小,也就是Node[]的默认长度
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//集合允许存放的元素最大个数
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认装载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//当单条链表的长度大于等8并且容量大于64时,就会将链表转换成红黑树
static final int TREEIFY_THRESHOLD = 8;
//当单条链表的长度小于等于6时,就会将红黑树转换成链表
static final int UNTREEIFY_THRESHOLD = 6;
//当单条链表的长度大于等8并且容量大于64时,就会将链表转换成红黑树
static final int MIN_TREEIFY_CAPACITY = 64;
//hash表的元素个数
transient int size;
//当size大于等于这个数时会进行rehash
int threshold;
//负载因子,如果没有传入则使用默认值 0.75f
final float loadFactor;
//记录hash表的修改次数
transient int modCount;
一、HashMap的构造函数
HashMap提供了无参构造函数和几个重载的有参构造函数,里面做的事情都没啥区别,就是给loadFactor和threshold赋初始值
源码:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
/**
* tableSizeFor方法用来将输入的值转换成2的整数倍,假如你输入的初始大小为7,则会
* 帮你自动转换成8,因为HashMap中table的长度永远是2的整数倍
*/
this.threshold = tableSizeFor(initialCapacity);
}这里的threshold 并不是最终的用来判断是否需要resize的值,而是table的长度,此时的table也是null,在向HashMap中放入第一个key-value时,会初始化table,并重新计算threshold。
二:HashMap的put过程
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
总结起来就是以下几步:
- 判断table是否为空,如果为空则进行resize,rezise时会重新设置threshold的值;
- 判断hash值对应的位置是否有元素,如果没有则直接放在对应的位置;
- 如果已经有元素了则进行判断:
- 如果第一个元素的key等于要加入的key,则直接e标记为第一个元素
- 如果第一个元素是一个红黑树,则调用红黑树的put方法
- 对链表进行遍历,如果key匹配,则将e标记成这个元素,否则将新插入的元素放在链表的末尾,注意不是表头:
- 判断链表的长度是否大于等于TREEIFY_THRESHOLD,如果是,则将链表转换成红黑树
- 如果e不等于空,则将e对应的value更新,并将oldvalue返回
- 记录hashMap的操作次数,判断size如果大于负载因子,则进行resize。
基本上看懂了put的过程,get的过程就很简单了,自己去看一下原码就明白了。
再额外说一下为什么HashMap中table的长度要设置成2的整数倍,因为我们是通过key的hash值来确定key对应的数组位置的,那么如果对应了,我们肯定想到了取模,例如:table的长度是16,则对16取模就可以了,也就是hashcode % 16,但是取模效率是很低的,其实对于2的整数倍对任何数取模可以直接用&操作,上面的例子就可以改为 hashcode & (16 - 1)。总结成公式就是hashcode % length = hashcode & (length - 1),这里的&操作效率可比%高得多。
PS:负载因子默认是0.75,所以Map中的元素个数不会达到初始化的容量就会进行resize,我们在初始化HashMap,给定容量大小时一定要考虑这一点。