CTF-web Xman-2018 msic习题
xman misc
CRC碰撞 4字节小文件
下载下来的是一个压缩包,里面是很多小的压缩包,每个文件只有四字节,满足CRC爆破。

使用脚本,将碰撞出来的拼接在一起
# coding:utf-8
import zipfile
import string
import binascii
def CrackCrc(crc):
for i in dic:
for j in dic:
for p in dic:
for q in dic:
s = i + j + p + q
if crc == (binascii.crc32(s) & 0xffffffff):
f.write(s)
return
def CrackZip():
for I in range(54):
print I
file = 'chunk' + str(I) + '.zip'
f = zipfile.ZipFile(file, 'r')
GetCrc = f.getinfo('data.txt')
crc = GetCrc.CRC
# 以上3行为获取压缩包CRC32值的步骤
# print hex(crc)
CrackCrc(crc)
dic = string.ascii_letters + string.digits + '+/='
f = open('out.txt', 'w')
CrackZip()
f.close()得到字符串,base64。
解码需要本地的,网上的不好用,得到一个压缩文件,需要密码
使用ziperell爆破,得到密码。这个题目的密码比较简单,直接爆破就行
二维码
这是一张png图片,使用Stegsolve观察平面

发现二维码,但是颜色反了,使用ps反相就可以。
扫描二维码得到16进制数据串,转码hex-》ascii,得到的数据头识别出pyc文件,保存为a.pyc
使用python执行
python
import a //导入该文件
dir(a) //列出内容 发现flag函数
a.flag() //调用函数 显示FLAG
dexyoryed png
这是一个被破坏的png,使用010打开,修复文件头

点击Templates选项--Online Template Repository下载
点击Templates选项-NEW Templates打开模板,会出现下图所示命令行
按F5,即使用对应的模板查看
对于没有安装的,使用如下顺序,选择对应脚本安装就可以
我们发现了很多的错误数据
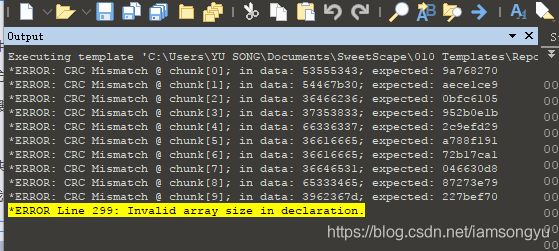
将所有错误数据拼接到一起,再解码就得到了flag。
MP4结合图像,并隐藏信息
这是一个视频文件,使用foremost xxx.xxx进行分解,得到一个奥利奥图像和视频。
视频简介中有信息

解码之后是一个网站
http://steghide.sourceforge.net/
那么我们查看分解出来的图像,是被加密的,应该就是这个算法的,解密需要密码,使用脚本破解
linux安装法子:
apt-get install steghide
windows安装:
打开https://sourceforge.net/projects/steghide/ 下载steghide-0.5.1-win32.zip,解压后就可以用。
//用AAPR(Advanced Archive Password Recovery)软件里的 english.dic作为这次破解需要的字典文件
//我们也可以使用别的
# -*- coding: utf8 -*-
#author:pcat
#http://pcat.cnblogs.com
from subprocess import *
def foo():
stegoFile='rose.jpg'
extractFile='hide.txt'
passFile='english.dic'
errors=['could not extract','steghide --help','Syntax error']
cmdFormat='steghide extract -sf "%s" -xf "%s" -p "%s"'
f=open(passFile,'r')
for line in f.readlines():
cmd=cmdFormat %(stegoFile,extractFile,line.strip())
p=Popen(cmd,shell=True,stdout=PIPE,stderr=STDOUT)
content=unicode(p.stdout.read(),'gbk')
for err in errors:
if err in content:
break
else:
print content,
print 'the passphrase is %s' %(line.strip())
f.close()
return
if __name__ == '__main__':
foo()
print 'ok'
pass得到密码为password,得到信息
foremost powpow.mp4 //分离视频
stepic -i output/png/00001069.png -d > thing //再次分离图片
steghide extract -sf thing.jpg -p password //提取信息
cat base64.txt //显示得到的文件
python3
>>> import base64 //解码
>>> base64.b85decode(b'W^7?+dsk&3VRB_4W^-?2X=QYIEFgDfAYpQ4AZBT9VQg%9AZBu9Wh@|fWgua4Wgup0ZeeU}c_3kTVQXa}eE')
b'flag{We are fsociety, we are finally free, we are finally awake!}'蓝牙流量包
首先我们可以判断这个流量包是蓝牙文件传输用的包,所以猜测flag应该在传输的文件里。


用wireshark打开以后,直接按照包大小,对数据包排个序,我们可以看到这部分数据包是一个png图片拼接起来的,这是第一个流量包的信息,包含png头,前边多了一块的文件名,后面的包就是纯数据了,将所有数据拼接在一起保存为png即可。
记住:保存的时候是复制hex流,然后在notepad+里转码为ascii在保存。
![]()
合并几个文件用命令
cat a.txt b.txt > c.txt
或者
cat a.txt b.txt >> c.txt
区别就是第一个创建文件或者截断文件.第二个是追加到文件末尾(文件不存在创建了).
得到flag
你不知道的文件个密码大集合
首先我们下载附件~
我们直接拖进Kali Linux里面去看看,然后发现文件变成LZO文件了

我们用binwalk看看,果然是个LZO文件,Google一查知道这是个压缩文件
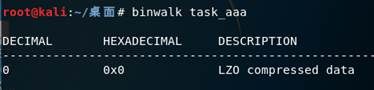
然后我们把文件名给改下,改成.lzo吧
然后这时候我们需要解压这个文件夹,我们可能需要安装解压命令lzop
apt-get install lzop
然后lzop -dv task_aaa.lzo解压压缩包
![]()
这时候我们就可能不知道从何处下手了,回到之前的压缩文件看看?
我们用010 Editor看看

我们看到了一个Base32编码
我们解码试试看
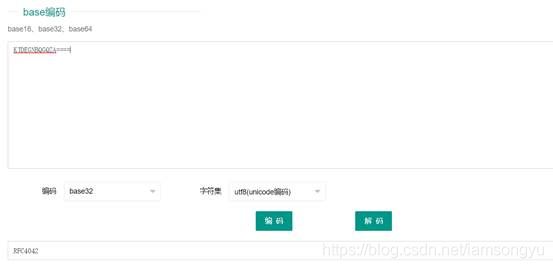
我们可以看到解出来的是RFC4042,这是一种文件的格式,我们Google找一下就知道,这里涉及到一个utf9编码,所以我们开始写个脚本解码
#coding utf-8
import utf9
utf9_file = open('task_aaa','rb')
utf9_data = utf9_file.read()
decoded_data = utf9.utf9decode(utf9_data)
print(decoded_data)
decoded_file = open('decoded','w')
decoded_file.write(decoded_data)
decoded_file.close()然后解出来了一个decode文件
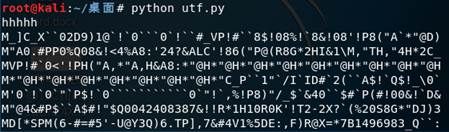
跑出来了一大坨的玩意,这个东西你可以参考官方文档:https://www.sec.gov/Archives/edgar/data/1304421/000117184318002029/0001171843-18-002029.txt
看了官方文档以后你就知道,我们需要改文件头和文件尾
我们直接在文件头加上begin 777 key.jpg
文件尾加上end即可
然后其实你对编码有了解的人就知道,这是一个uuencode编码,这个用网上的在线解码工具也可以,我就直接用Linux里面的uuencode工具解码
安装命令如下:
apt-get install sharutils
uudecode -o flag.txt decoded我们用010Editor看看,我们可以很清楚的看到,FFD8FFE0开头,很明显是个jpg图片,我们只需要把文件名改成,jpg文件即可~
flag如下:
