mysql 四约束 三范式 六索引
1.MySQL 约束
1.约束的作用 分类
表列的primary key主键,unique唯一键,not null非空 等修饰符常常被称作约束(constraint)
约束是数据库用来 提高数据质量 和 保证数据完整性 的一套机制
约束作用在表列上,是表定义(DDL语句)的一部分
约束分类
非空约束 (not null)
唯一性约束 (unique)
主键约束 (primary key)
外键约束 (foreign key)
2.查看约束 (索引) 三种方式 desc show create show index
desc table_name表名;
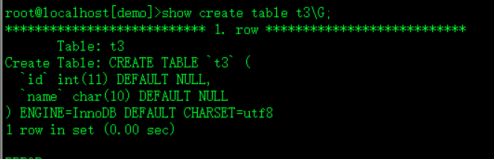
show create table table_name\G
show index from table_name;看不了非空约束

3.约束的定义方式 列表 和追究定义 primary key主键 案例
创建表时建立约束 (事中)建表之前就已经规划好了
create table t (id int primary key,name char(10));列级定义
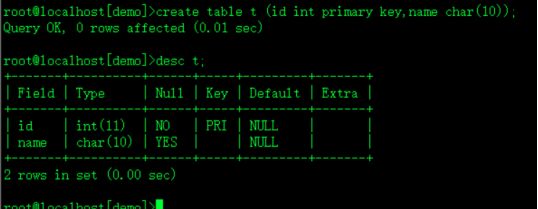
create table t (id int,name char(10),primary key(id));表级定义

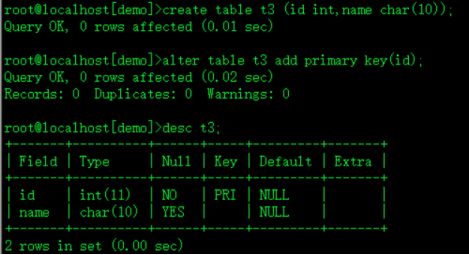
修改表时追加约束(事后)建表之后根据需要追加
alter table t add primary key(id);追加定义
create table kwz(id int,name varchar(10),sex char(10),phone char(10), primary key(id,name));
desc kwz;

4.非空约束 null 使用modify来追加定义 列级 和追加定义 案例
非空约束用于确保 其所在列的值 不能为空值null
只有 列级定义 和 追加定义
语法
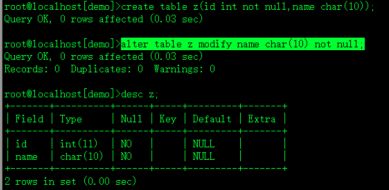
create table z(id int not null,name char(10));列级定义
alter table z modify name char(10) not null;追加定义
加 非空 约束null
create table z(id int not null,name char(10));
alter table z modify name char(10) not null;
desc z;
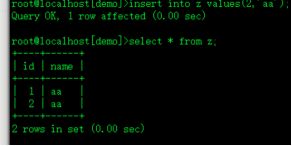
insert into z values(1,'aa');
insert into z values(2,'aa');
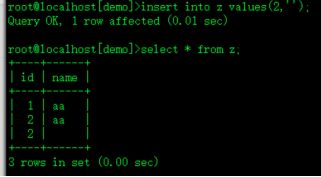
insert into z values(2,'');

5.MySQL唯一性约束 unique 案例
表列中不允许有重复值,但是可以有空值
语法
create table t1 (id int unique,name char(10)); 列级定义
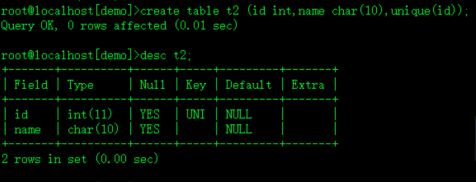
create table t2 (id int,name char(10),unique(id));表级定义

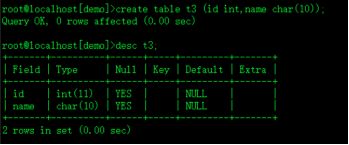
create table t3 (id int,name char(10));追加定义
alter table t3 modify id int unique;

允许有空值 不允许重复
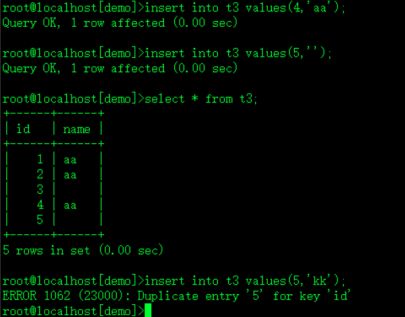
insert into t3 values(4,'aa');
insert into t3 values(5,'');允许有空值
insert into t3 values(5,'kk');不允许重复
select * from t3;
6.MySQL主键primary key约束 一个表只有 一个主键约束列
表列中不允许有重复值,也不可以有空值
一个表中只能有一个主键约束列,但可以有多个非空+唯一约束的列
语法
create table t (id int primary key,name char(10));列级定义
create table t (id int,name char(10),primary key(id));表级定义
修改表时追加约束(事后)建表之后根据需要追加
alter table t add primary key(id);追加定义
7.MySQL外键 foreign key约束 也叫参考约束或一致性约束 表级定义
外键 约束引用 主键构成 完整性约束
外键 允许有空值

不允许存在对应主键约束的列所有数值以外的其它值
创建外键约束时,MySQL自动创建非唯一性索引
语法 (此例使用2个表,也可以是同一个表)
表级定义
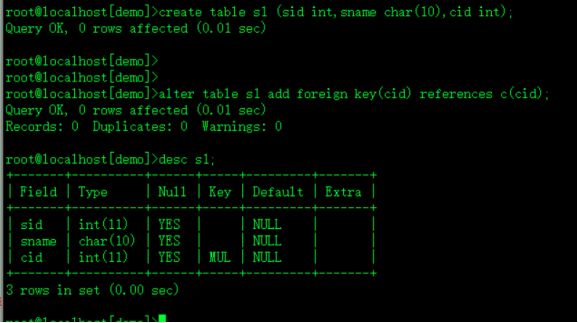
create table c (cid int primary key,cname char(10)); 先建立外键要引用的 主表
create table s (sid int,sname char(10),cid int,foreign key(cid) references c(cid)); 再建立包含外键的 从表 表定义

create table s1 (sid int,sname char(10),cid int);追加定义
alter table s1 add foreign key(cid) references c(cid);
]
测试
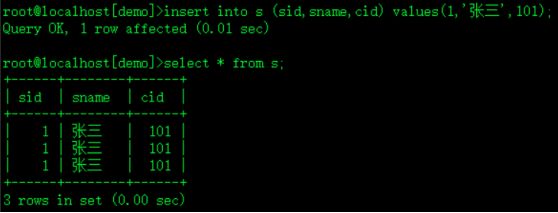
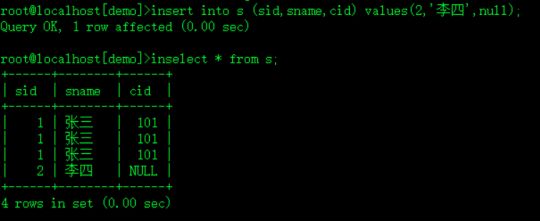
insert into s (sid,sname,cid) values(1,'张三',101);
报错,因为c表中cid不存在100的值,当前c表中没有任何记录
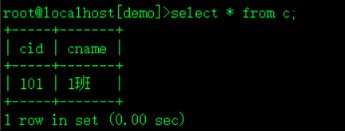
insert into c (cid,cname) values(101,'1班'); c表中插入cid为101的值
insert into s (sid,sname,cid) values(1,'张三',101);再次插入成功
insert into s (sid,sname,cid) values(2,'李四',null); 插入成功,外键列可有空值
删除s表cid列中的外键约束
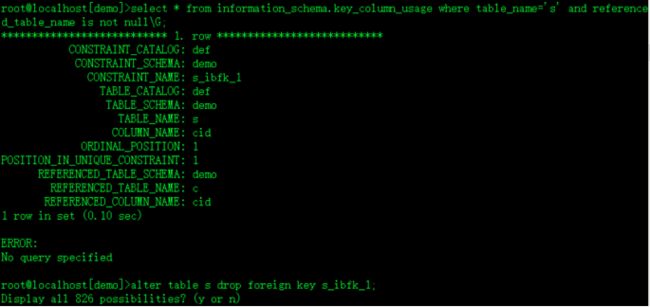
select * from information_schema.key_column_usage where table_name='s' and referenced_table_name is not null\G;先要找出s表cid上外键约束的名称
alter table s drop foreign key s_ibfk_1;然后再删除s表cid上的外键约束
2.数据库三范式(3NF) 与设计基本原则
关系型数据库的特点
基本组成单位为二维表
各二维表之间存在一定的关系
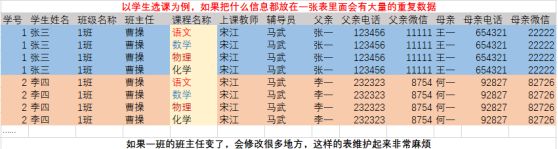
数据为什么不能都放在一张表里面?
1.数据库范式
提出范式的概念,级别越高重复数据越少
第一范式:
表无重复列
数据库 表的每一列 都是不可分割的 基本数据项
没有 性质相同的重复列
如果出现重复的属性,就可能需要定义一个新的实体
新的实体由重复的属性构成,新实体与原实体之间为一对多关系
不符合第一范式表设计示例:

第二范式:即有主键
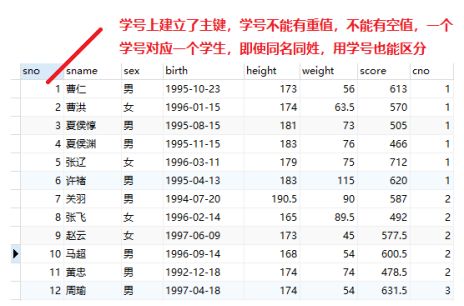
在符合第一范式的基础之上,每个表都有一个能区分每条记录的主键(主键 非空 + 唯一 + 索引),而且非主键列都完全依赖于主键
第三范式:要求一个表中 不要包含在其它表中 已有的非主关键字信息。
在符合第二范式的基础之上,表中的列不能包括其他独立事物(表)的非主键信息。
以学生表和班级表为例,学生 和 班级 是2个相对独立的概念,应该分别建立学生表和班级表。
学生表的学生用主键学号区分,没有多余的重复记录
班级表的班级用主键班号区分,没有多余的重复记录
学生对班级存在依赖关系,学生要属于一个班级,如果按照如下设计,会有重复:
班级表:班号、班名
学生表:学号、姓名、班号、班名(已经存在于班级表中,不是主键,再放到学生表中数据就有重复了)
把学生表中的班名去掉,保留能唯一区分班级的班号,学生表对于班级表来说就符合第三范式了

2.数据库表设计原则
设计原则
第一范式必须满足表无重复列
符合第二范式 每个表都有主键
尽量满足第三范式根据业务需求,数据库服务器架构、性能要求灵活掌握
设计方式
根据需求,提取业务中相对独立的业务要素
如:学生、班级、课程、家长、教职员工、学院、系、岗位、教学楼,教室、设备、厂商、IP地址、课程表、考试、成绩表、字典表(性别、职称、岗位……)等等
为每个业务要素 建立单独的表 并建立主键,确保无重复记录 (符合一二范式)
根据需求,理清业务要素 及其所建的 表列间的三种关系:
一对一
一对多
多对多
并根据情况建立表间的 主外键约束关系
一对一
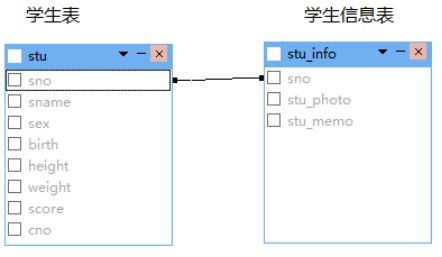
设计人员先建立学生表,存储学号、姓名、性别、生日、身高、体重、高考分、班号的信息,后来学校要求还要存储学生的照片和备注说明等信息。
设计人员可以在原来学生表中添加照片和备注说明2列内容,也可以为每个学生单独建立一张学生信息表用来存储学生照片和备注信息;
如果这样设计,学生表的学号列和后建的学生信息表的学号列之间就是一对一的关系,即学生表的一条行记录对应学生信息表的一条行记录。
有时一张列比较多的表,可以根据列拆分成几张小表,每个小表都有一样的主键,每个小表之间就是一对一的关系
一对多
当前学生表的班号和班级表的班号就是一对多的关系,
一个班级可以包括多名学生、一个学生只能属于一个班级。
一个城市只能属于一个国家,国家和城市就是一对多的关系;
教室只能属于一个教学楼,教学楼和教室就是一对多的关系,
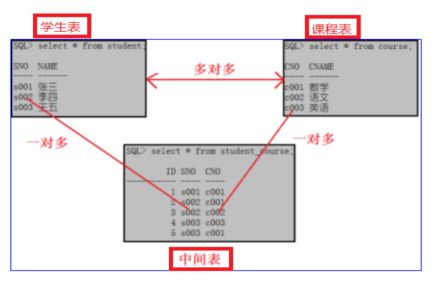
多对多
学生和课程之间就是多对多的关系,一个学生可以选择多门课程,一个课程也可以有多名学生来学。
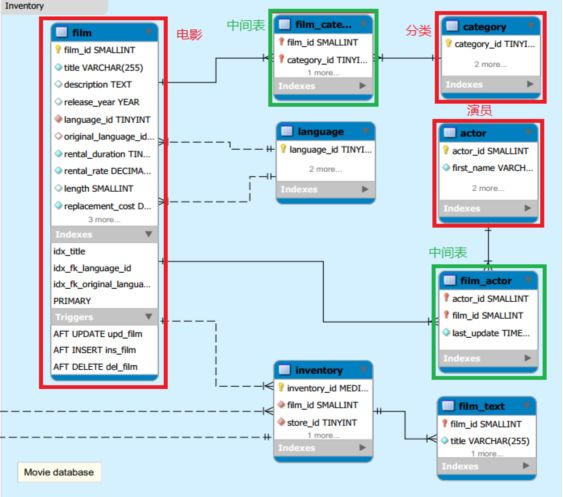
演员和电影可是多对多的关系,一名演员可以参演多部电影,一部电影可以有多名演员来参演。
设计时,已学生和课程为例,分别建立学生表和课程表,确保学生表无重复,课程表无重复,然后建立关系表,分别包含学生编号和课程编号,这样可以将多对多的关系利用中间表,变成两个一对多的关系。
如下图:
如何确定表间的三种关系
主要根据业务需求来定,业务需求决定表间关系。
一般来说班级和学生是一对多的关系,但是如果实际情况是一个学生可以自由选择加入多个班听课,也可以把班级表和学生表设计成多对多的关系。这样可以满足需求,不会出现表中没有位置存储数据的问题。
一对多 变成 多对多
假如业务需求变更,一个学生可以属于多个班,需要将一个学生对应的多个班号存入数据库表,数据库表需要进行调整,通常会引起程序的级联调整。
假如业务需求变更,一个学生可以属于多个班,需要将一个学生对应的多个班号存入数据库表,数据库表需要进行调整,通常会引起程序的级联调整。
通常有2种办法:
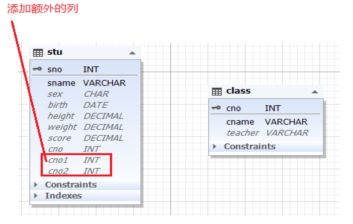
方法1(不符合第一范式,程序和数据调整工作量小):
在学生表添加额外班号列,cno1,cno2.......。比如规定一个学生最多可属于3个班,加3列就可以了。但是如果没有限制,如极端情况,一个学生可以有100个班,加列的方式就有局限性了。需要采用中间表的形式。
方法2:
给学生表和课程表建立一个中间表(比如:rel_class_stu),该表分别包括学号(sno)和班号(cno)
这样的设计是正规的多对多的设计方式,灵活度比方法一要大,
方法一的加列的方式往往用于因需求调整而采取的一种临时补救措施。
原来一个学生只能属于一个班,现在学校规定调整为一个学生最多可以属于5个班,就在学生表中再增加4列班号。
此时,如果要采用方法2建立中间表的方式,可能需要对现有数据进行迁移会有更多额外的工作要做。
3.索引
1索引 优缺点 快速定位
索引是一种只能让select语句 提高效率的一种数据结构 索引和表不是一种结构
优点:
某些情况下使SELECT语句提高效率,合适的索引可优化MySQL服务器的查询性能
缺点:
表行数据的变化(insert增, update改, delete删),建立在表列上的索引也会自动维护,
一定程度上会使DML操作变慢;索引会占用磁盘额外的存储空间
索引快速定位数据的作用
字典的索引页、图书的目录页、Word文档的文档结构树、黄页、术语表
举例查字典索引能加快查询速度
我想查“王”字,按照拼音查,第9页,汉语拼音音节索引
“王”字汉语拼音wang,找到W,在W索引节点,找到wang,页号512,翻到512页
索引页的好处
每个字类比库表的行
索引页的坏处(代价)
数据库要耗费磁盘空间存索引
数据库维护索引要占用CPU资源
索引要占用额外磁盘存储空间
oracle数据库
scott库 T表 表段 所占用users表空间中的空间,图中黄色部分,T表100万行记录,记录越多占用的格子(类比“页”)就越多
索引和表是两种结构
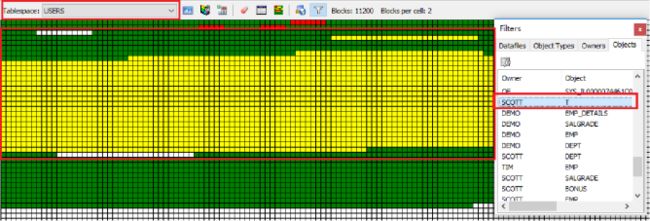
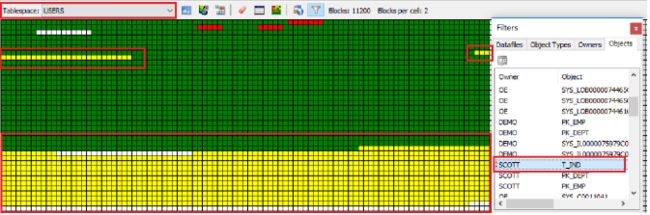
oracle数据库
scott库 T表 的表列id上创建的 索引 t_ind (段) 所占用users表空间中的空间,图中黄色部分
2.MySQL创建索引index 追加删除索引
索引和 表 是两种结构 建立索引指定表
create table t(id int,name varchar(20),index idx_name (name));建表时创建索引 idx

给表追加索引
alter table t add unique index idx_id(id);(MySQL专有) idx_id
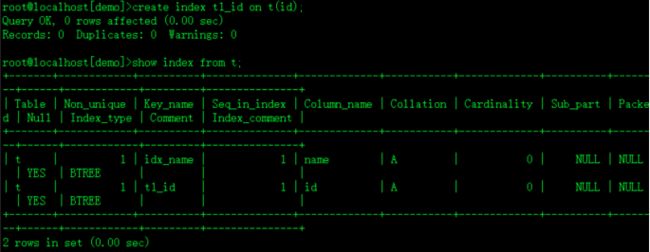
create index t1_id on t(id);(通用)t1_id
给表的多列上追加索引,以下2种方式均可
alter table t add col1 int,add col2 char(10),add col3 varchar(20);增加三列
show index from t;查看索引keyname comment
alter table t add index idx_id_name(col1,col2); 增加索引col1 和col2

或者
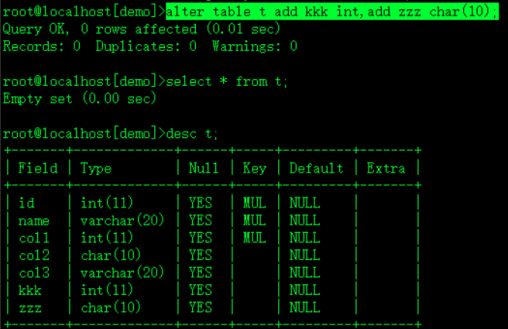
alter table t add kkk int,add zzz char(10);t表增加两列 kkk zzz
create index kwz on t(kkk,zzz);kwz为索引 kkk和zzz为增加的列
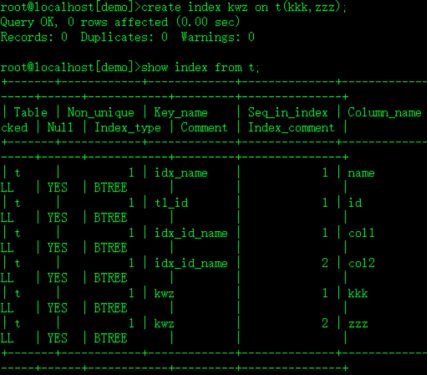
删除 索引
drop index idx_id_name on t;删除索引
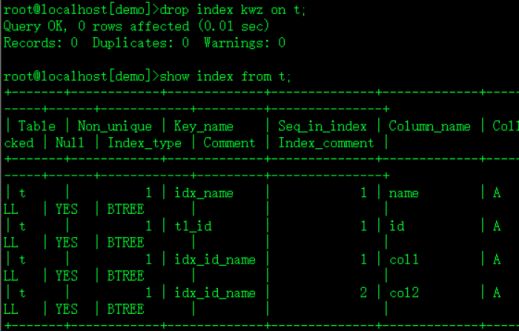
drop index kwz on t;删除kwz索引
show index from t;
3.MySQL查看 索引 两种方式
查看表列上的索引索引,以下2种方式均可
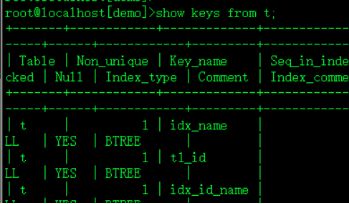
show index from t;
show keys from t; mysql中索引也被称为keys
使用show create table语句查看t表列上的索引:
show create table t\G

4.MySQL 删除索引 两种方式 drop 和 alter
使用alter table命令删除索引(MySQL专有)
格式:
alter table 表名 drop index 索引名
alter table t drop index kwz;
删除索引

使用drop index命令删除索引(通用):
格式:
drop index 索引名 on 表名
drop index idx_name on t;
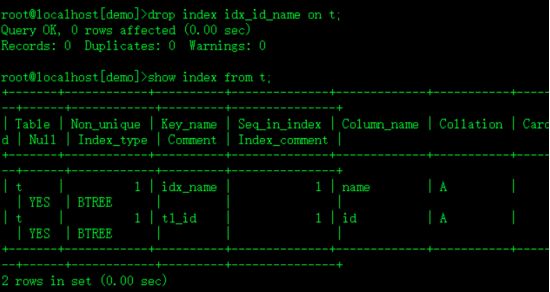
drop index idx_id_name on t;删除t表的 idx_id_name的索引
5.索引 加快 查询效果案例 创建表 插入参数 设置索引 查看 删除索引
use testdb ;使用数据库
create table t(id int,name varchar(20));创建测试表t (id name)
创建存储过程proc1,传入参数(插入的行数)
\d $$
create procedure proc1 ( cnt int )
begin
declare i int default 1;
start transaction;
while i <= cnt do
insert into t values(i,concat( 'a', i ));
set i := i + 1;
end while;
commit;
end$$
\d ;

ls -lh /var/lib/mysql/testdb/t.*观察/var/lib/mysql/test下“t.ibd”文件的大小
call proc1(1000000); 调用存储过程:插入t表一百万条测试数据
ll -h /var/lib/mysql/testdb/t.*观察/var/lib/mysql/test下“t.ibd”文件的大小


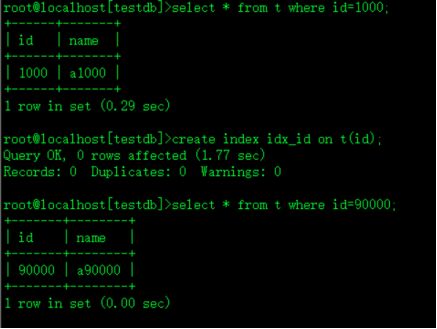
select * from t where id=1000;测试无索引时从百万记录找1行所需时间
create index idx_id on t(id);给t表id列创建一个索引idx_id
ll -h /var/lib/mysql/test/t.*观察/var/lib/mysql/test下“t.ibd”文件的大小


select * from t where id=1000;测试有索引时从百万记录找1行所需时间
create index idx_id on t(id);测试有索引时从百万记录找所有行所需时间
删除索引
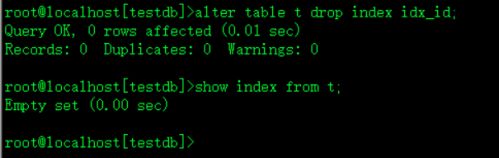
alter table t drop index idx_id;
show index from t;
返回的结果输出给pager“cat>/dev/null”不显示输出仅看执行时间,方便测试
pager cat>/dev/null;
select * from t where id>0; 当返回行数太多时,索引没用
create index idx_id on t(id);创建索引再次查看
select * from t where id >=100000;
select * from t where id =100000;
nopager;

6.MySQL索引基本原理 查询四步骤
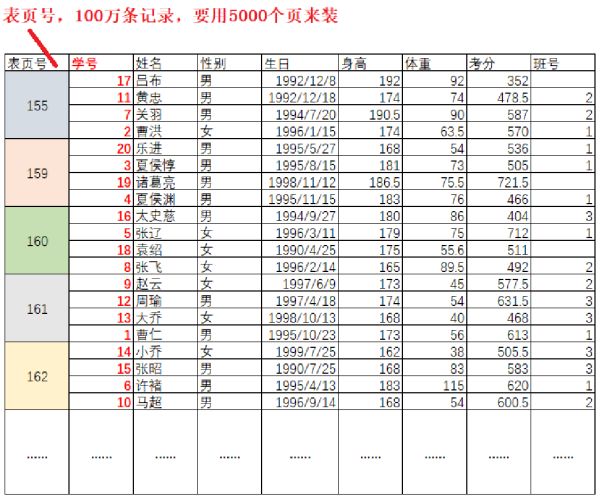
1.)stu有1百万个学生,1百万行记录,假如分别存放在5000个页中(页page是最小的逻辑存储单元,默认一个页16k大小,系统会给每个页分配一个唯一编号)
2.)如果查询select * from stu where sno=13不使用索引,就是没有主键,外键和 会翻遍所有5000个页,看看页中有没有行记录的sno号值等于13的,
3.)有就符合where条件,将该行记录保留在查询结果集中。
如果每个页挨个都要翻一遍,行记录很多的时候,查询就会很慢
如果在stu表的sno列上创建索引
alter table stu add index idx_sno(sno);
首先会提取stu表中所有记录sno的值,在内存中按照从小到大的顺序排序
排序后的结果形成了很多索引页(page),这个过程由mysql按照算法自动完成,不用过于深究其中的详细过程

索引页之间存在一定的关联关系,一般为树形结构;
分为根节点、分支节点、和叶子节点
根节点页中存放分段sno的起始值,以及值所对应的分支索引页号
分支索引页中存放分段sno的起始值,以及值所对应的叶子索引页号
叶子索引页中存放排序后的sno值,该值所对应的表页号, 下一个叶子索引页的页号

sno建立索引后
select * from stu where sno=13
查询过程如下
第一步 索引页存在关联关系,先找索引页号20的根节点,13在>=11和<17的范围内,需要查找25号索引页
第二步 读取25号索引页,13在>=11和<14范围内,得到了26号叶子索引页
第三步 读取26号叶子索引页,找到了13这个值,以及该值所对应表页的页号161,因为是select * 所有列,目前只得到了sno的值,还要得到sname,sex,height等,因此需要再读一次编号为161的表页,里面存放了sno之外的值
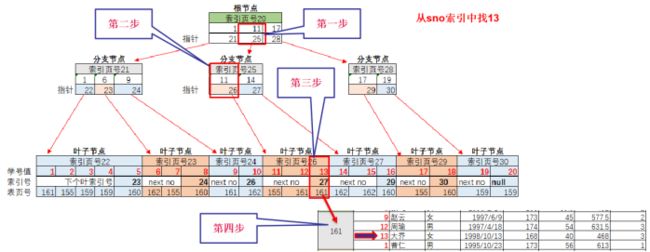
第四步 读取161号表页,获得sname,sex,height等值

以上4步,只读取了3个索引页1个表页,共4个页,比读取所有表页(5000个页),按照sno=13挨个翻一遍效率要高,这也是有些情况下索引可以加速查询的原因
查四个块从小到大的顺序排序
第一步找 根节点
第二步找 分支节点
第三步找 叶子节点
第四步 通过叶子节点来 找 表行数据的内容
7.MySQL索引 使用条件 和 弊端
1.大表(记录数多),仅从中找出少量行(总行数的3%-%5)
例如:
100万个学生中,学号是主键没有重值,仅找1个学生,在学号列上加索引并按照学号来查找会很快找到
例如:
100万s个学生中,学号1到100万,要找学号大于1的学生,这样99%以上的结果都会返回,此时索引没有作用,不能起到加速查询的作用
2.在经常作为查询条件(where)的列上添加索引,返回记录少,就可能用上索引,起到加速查询的作用
3.索引和表的区别是索引页之间存在关联关系,但是会占用额外的磁盘空间,有可能出现索引占的磁盘空间比表还大的情况
例如:
在表上根据常用查询条件,使用多个列建立了索引
4.索引会自动维护,常规的DML操作会导致索引的变化,这会增加服务器的负担,导致DML操作变慢,尤其是一个表有多个索引的情况下
8.索引的分类方式 六种
分类1:按照索引和索引对应其他表列数据是否在一个数据页中
* 聚集索引 clustered index索引的数据 在一个表里(表行数据)
* 非聚集索引 non-clustered index 索引页与表页分离,索引占用额外磁盘空间
分类2:按照索引列是否为主键
* 主键索引 创建表会自动创建主键索引(MySQL主键索引为聚集索引)
* 非主键索引
create table k(id int primary key,name varchar(20));创建id为主键索引
show index from k;

create index k_idx on k(name);创建非主键索引
show index from k;

分类3:按照创建索引的列数
* 单列索引
create index idx_sname on w(id);
* 多列索引(复合索引)
create index idx_cno_sex on stu(cno,sex);
分类4:按照索引值是否可以重复
* 唯一性索引
create unique index idx_t on t(id);即为mysql中的 唯一约束
* 非唯一索引
create index idx_t on t(id);
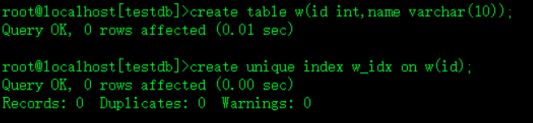
create table w(id int,name varchar(10));创建唯一索引
create unique index w_idx on w(id);
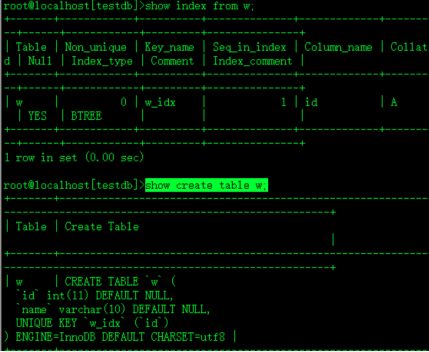
show index from w;
show create table w;
即为name可以空值 但id不可重复
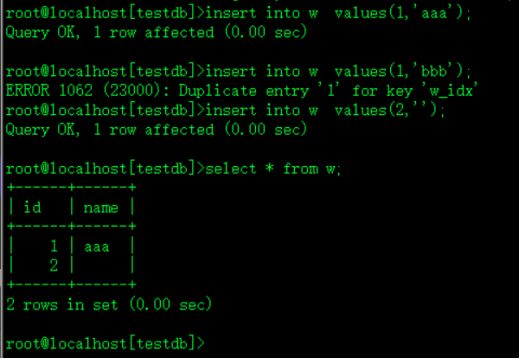
insert into w values(1,'bbb');上面指定unique 即id唯一不可重复
insert into w values(1,'aaa');插入重复id会报错
insert into w values(2,'');
select * from w;
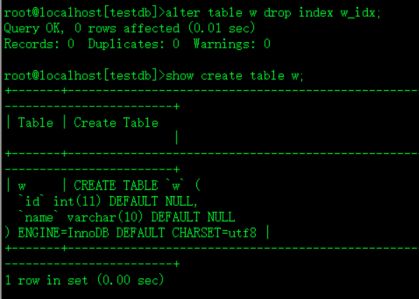
删除唯一索引
alter table w drop index w_idx;删除w表的w_id的索引
show create table w;查看表
分类5:按照放入索引的列值
* 稠密索引(所有索引列的值都放入索引) MySQL
* 稀疏索引(部分索引列的值都放入索引) DB2可选
分类6:按照形成索引的算法
* B+树索引(MySQL的innodb引擎形成索引的算法为B+树算法)
* B-树索引(Oracle默认堆表索引)
* hash索引(MySQL的memory引擎形成索引的算法为bash算法,范围查询用不上索引,只能等值查找)
注意:
1.主键约束会自动创建索引,主键索引是聚集索引,索引中不能有重复值;
2.外键约束MySQL也会自动创建索引,外键约束的索引是非聚集索引,默认是非唯一索引(因为外键列可以有重复值)
3.唯一性约束MySQL也会自动创建索引,唯一性约束的索引是唯一性索引
4.一个表只能有一个主键约束
因为主键索引是聚集索引,索引值和对应表行数据存放在一起而且按照索引值的顺序存放;同一时刻只能有一种排序方式,
但是可以给主键列之外的列添加多个非空+唯一性约束(效果等同于主键约束)
1.MySQL 约束
1.约束的作用 分类
表列的primary key主键,unique唯一键,not null非空 等修饰符常常被称作约束(constraint)
约束是数据库用来 提高数据质量 和 保证数据完整性 的一套机制
约束作用在表列上,是表定义(DDL语句)的一部分
约束分类
非空约束 (not null)
唯一性约束 (unique)
主键约束 (primary key)
外键约束 (foreign key)
2.查看约束 (索引) 三种方式 desc show create show index
desc table_name表名;
show create table table_name\G
show index from table_name;看不了非空约束
3.约束的定义方式 列表 和追究定义 primary key主键 案例
创建表时建立约束 (事中)建表之前就已经规划好了
create table t (id int primary key,name char(10));列级定义
create table t (id int,name char(10),primary key(id));表级定义
修改表时追加约束(事后)建表之后根据需要追加
alter table t add primary key(id);追加定义
create table kwz(id int,name varchar(10),sex char(10),phone char(10), primary key(id,name));
desc kwz;
4.非空约束 null 使用modify来追加定义 列级 和追加定义 案例
非空约束用于确保 其所在列的值 不能为空值null
只有 列级定义 和 追加定义
语法
create table z(id int not null,name char(10));列级定义
alter table z modify name char(10) not null;追加定义
加 非空 约束null
create table z(id int not null,name char(10));
alter table z modify name char(10) not null;
desc z;
insert into z values(1,'aa');
insert into z values(2,'aa');
insert into z values(2,'');
5.MySQL唯一性约束 unique 案例
表列中不允许有重复值,但是可以有空值
语法
create table t1 (id int unique,name char(10)); 列级定义
create table t2 (id int,name char(10),unique(id));表级定义
create table t3 (id int,name char(10));追加定义
alter table t3 modify id int unique;
允许有空值 不允许重复
insert into t3 values(4,'aa');
insert into t3 values(5,'');允许有空值
insert into t3 values(5,'kk');不允许重复
select * from t3;
6.MySQL主键primary key约束 一个表只有 一个主键约束列
表列中不允许有重复值,也不可以有空值
一个表中只能有一个主键约束列,但可以有多个非空+唯一约束的列
语法
create table t (id int primary key,name char(10));列级定义
create table t (id int,name char(10),primary key(id));表级定义
修改表时追加约束(事后)建表之后根据需要追加
alter table t add primary key(id);追加定义
7.MySQL外键 foreign key约束 也叫参考约束或一致性约束 表级定义
外键 约束引用 主键构成 完整性约束
外键 允许有空值
不允许存在对应主键约束的列所有数值以外的其它值
创建外键约束时,MySQL自动创建非唯一性索引
语法 (此例使用2个表,也可以是同一个表)
表级定义
create table c (cid int primary key,cname char(10)); 先建立外键要引用的 主表
create table s (sid int,sname char(10),cid int,foreign key(cid) references c(cid)); 再建立包含外键的 从表 表定义
create table s1 (sid int,sname char(10),cid int);追加定义
alter table s1 add foreign key(cid) references c(cid);
]
测试
insert into s (sid,sname,cid) values(1,'张三',101);
报错,因为c表中cid不存在100的值,当前c表中没有任何记录
insert into c (cid,cname) values(101,'1班'); c表中插入cid为101的值
insert into s (sid,sname,cid) values(1,'张三',101);再次插入成功
insert into s (sid,sname,cid) values(2,'李四',null); 插入成功,外键列可有空值
删除s表cid列中的外键约束
select * from information_schema.key_column_usage where table_name='s' and referenced_table_name is not null\G;先要找出s表cid上外键约束的名称
alter table s drop foreign key s_ibfk_1;然后再删除s表cid上的外键约束
2.数据库三范式(3NF) 与设计基本原则
关系型数据库的特点
基本组成单位为二维表
各二维表之间存在一定的关系
数据为什么不能都放在一张表里面?
1.数据库范式
提出范式的概念,级别越高重复数据越少
第一范式:
表无重复列
数据库 表的每一列 都是不可分割的 基本数据项
没有 性质相同的重复列
如果出现重复的属性,就可能需要定义一个新的实体
新的实体由重复的属性构成,新实体与原实体之间为一对多关系
不符合第一范式表设计示例:
第二范式:即有主键
在符合第一范式的基础之上,每个表都有一个能区分每条记录的主键(主键 非空 + 唯一 + 索引),而且非主键列都完全依赖于主键
第三范式:要求一个表中 不要包含在其它表中 已有的非主关键字信息。
在符合第二范式的基础之上,表中的列不能包括其他独立事物(表)的非主键信息。
以学生表和班级表为例,学生 和 班级 是2个相对独立的概念,应该分别建立学生表和班级表。
学生表的学生用主键学号区分,没有多余的重复记录
班级表的班级用主键班号区分,没有多余的重复记录
学生对班级存在依赖关系,学生要属于一个班级,如果按照如下设计,会有重复:
班级表:班号、班名
学生表:学号、姓名、班号、班名(已经存在于班级表中,不是主键,再放到学生表中数据就有重复了)
把学生表中的班名去掉,保留能唯一区分班级的班号,学生表对于班级表来说就符合第三范式了
2.数据库表设计原则
设计原则
第一范式必须满足表无重复列
符合第二范式 每个表都有主键
尽量满足第三范式根据业务需求,数据库服务器架构、性能要求灵活掌握
设计方式
根据需求,提取业务中相对独立的业务要素
如:学生、班级、课程、家长、教职员工、学院、系、岗位、教学楼,教室、设备、厂商、IP地址、课程表、考试、成绩表、字典表(性别、职称、岗位……)等等
为每个业务要素 建立单独的表 并建立主键,确保无重复记录 (符合一二范式)
根据需求,理清业务要素 及其所建的 表列间的三种关系:
一对一
一对多
多对多
并根据情况建立表间的 主外键约束关系
一对一
设计人员先建立学生表,存储学号、姓名、性别、生日、身高、体重、高考分、班号的信息,后来学校要求还要存储学生的照片和备注说明等信息。
设计人员可以在原来学生表中添加照片和备注说明2列内容,也可以为每个学生单独建立一张学生信息表用来存储学生照片和备注信息;
如果这样设计,学生表的学号列和后建的学生信息表的学号列之间就是一对一的关系,即学生表的一条行记录对应学生信息表的一条行记录。
有时一张列比较多的表,可以根据列拆分成几张小表,每个小表都有一样的主键,每个小表之间就是一对一的关系
一对多
当前学生表的班号和班级表的班号就是一对多的关系,
一个班级可以包括多名学生、一个学生只能属于一个班级。
一个城市只能属于一个国家,国家和城市就是一对多的关系;
教室只能属于一个教学楼,教学楼和教室就是一对多的关系,
多对多
学生和课程之间就是多对多的关系,一个学生可以选择多门课程,一个课程也可以有多名学生来学。
演员和电影可是多对多的关系,一名演员可以参演多部电影,一部电影可以有多名演员来参演。
设计时,已学生和课程为例,分别建立学生表和课程表,确保学生表无重复,课程表无重复,然后建立关系表,分别包含学生编号和课程编号,这样可以将多对多的关系利用中间表,变成两个一对多的关系。
如下图:
如何确定表间的三种关系
主要根据业务需求来定,业务需求决定表间关系。
一般来说班级和学生是一对多的关系,但是如果实际情况是一个学生可以自由选择加入多个班听课,也可以把班级表和学生表设计成多对多的关系。这样可以满足需求,不会出现表中没有位置存储数据的问题。
一对多 变成 多对多
假如业务需求变更,一个学生可以属于多个班,需要将一个学生对应的多个班号存入数据库表,数据库表需要进行调整,通常会引起程序的级联调整。
假如业务需求变更,一个学生可以属于多个班,需要将一个学生对应的多个班号存入数据库表,数据库表需要进行调整,通常会引起程序的级联调整。
通常有2种办法:
方法1(不符合第一范式,程序和数据调整工作量小):
在学生表添加额外班号列,cno1,cno2.......。比如规定一个学生最多可属于3个班,加3列就可以了。但是如果没有限制,如极端情况,一个学生可以有100个班,加列的方式就有局限性了。需要采用中间表的形式。
方法2:
给学生表和课程表建立一个中间表(比如:rel_class_stu),该表分别包括学号(sno)和班号(cno)
这样的设计是正规的多对多的设计方式,灵活度比方法一要大,
方法一的加列的方式往往用于因需求调整而采取的一种临时补救措施。
原来一个学生只能属于一个班,现在学校规定调整为一个学生最多可以属于5个班,就在学生表中再增加4列班号。
此时,如果要采用方法2建立中间表的方式,可能需要对现有数据进行迁移会有更多额外的工作要做。
3.索引
1索引 优缺点 快速定位
索引是一种只能让select语句 提高效率的一种数据结构 索引和表不是一种结构
优点:
某些情况下使SELECT语句提高效率,合适的索引可优化MySQL服务器的查询性能
缺点:
表行数据的变化(insert增, update改, delete删),建立在表列上的索引也会自动维护,
一定程度上会使DML操作变慢;索引会占用磁盘额外的存储空间
索引快速定位数据的作用
字典的索引页、图书的目录页、Word文档的文档结构树、黄页、术语表
举例查字典索引能加快查询速度
我想查“王”字,按照拼音查,第9页,汉语拼音音节索引
“王”字汉语拼音wang,找到W,在W索引节点,找到wang,页号512,翻到512页
索引页的好处
每个字类比库表的行
索引页的坏处(代价)
数据库要耗费磁盘空间存索引
数据库维护索引要占用CPU资源
索引要占用额外磁盘存储空间
oracle数据库
scott库 T表 表段 所占用users表空间中的空间,图中黄色部分,T表100万行记录,记录越多占用的格子(类比“页”)就越多
索引和表是两种结构
oracle数据库
scott库 T表 的表列id上创建的 索引 t_ind (段) 所占用users表空间中的空间,图中黄色部分
2.MySQL创建索引index 追加删除索引
索引和 表 是两种结构 建立索引指定表
create table t(id int,name varchar(20),index idx_name (name));建表时创建索引 idx
给表追加索引
alter table t add unique index idx_id(id);(MySQL专有) idx_id
create index t1_id on t(id);(通用)t1_id
给表的多列上追加索引,以下2种方式均可
alter table t add col1 int,add col2 char(10),add col3 varchar(20);增加三列
show index from t;查看索引keyname comment
alter table t add index idx_id_name(col1,col2); 增加索引col1 和col2
或者
alter table t add kkk int,add zzz char(10);t表增加两列 kkk zzz
create index kwz on t(kkk,zzz);kwz为索引 kkk和zzz为增加的列
删除 索引
drop index idx_id_name on t;删除索引
drop index kwz on t;删除kwz索引
show index from t;
3.MySQL查看 索引 两种方式
查看表列上的索引索引,以下2种方式均可
show index from t;
show keys from t; mysql中索引也被称为keys
使用show create table语句查看t表列上的索引:
show create table t\G
4.MySQL 删除索引 两种方式 drop 和 alter
使用alter table命令删除索引(MySQL专有)
格式:
alter table 表名 drop index 索引名
alter table t drop index kwz;
删除索引
使用drop index命令删除索引(通用):
格式:
drop index 索引名 on 表名
drop index idx_name on t;
drop index idx_id_name on t;删除t表的 idx_id_name的索引
5.索引 加快 查询效果案例 创建表 插入参数 设置索引 查看 删除索引
use testdb ;使用数据库
create table t(id int,name varchar(20));创建测试表t (id name)
创建存储过程proc1,传入参数(插入的行数)
\d $$
create procedure proc1 ( cnt int )
begin
declare i int default 1;
start transaction;
while i <= cnt do
insert into t values(i,concat( 'a', i ));
set i := i + 1;
end while;
commit;
end$$
\d ;
ls -lh /var/lib/mysql/testdb/t.*观察/var/lib/mysql/test下“t.ibd”文件的大小
call proc1(1000000); 调用存储过程:插入t表一百万条测试数据
ll -h /var/lib/mysql/testdb/t.*观察/var/lib/mysql/test下“t.ibd”文件的大小
select * from t where id=1000;测试无索引时从百万记录找1行所需时间
create index idx_id on t(id);给t表id列创建一个索引idx_id
ll -h /var/lib/mysql/test/t.*观察/var/lib/mysql/test下“t.ibd”文件的大小
select * from t where id=1000;测试有索引时从百万记录找1行所需时间
create index idx_id on t(id);测试有索引时从百万记录找所有行所需时间
删除索引
alter table t drop index idx_id;
show index from t;
返回的结果输出给pager“cat>/dev/null”不显示输出仅看执行时间,方便测试
pager cat>/dev/null;
select * from t where id>0; 当返回行数太多时,索引没用
create index idx_id on t(id);创建索引再次查看
select * from t where id >=100000;
select * from t where id =100000;
nopager;
6.MySQL索引基本原理 查询四步骤
1.)stu有1百万个学生,1百万行记录,假如分别存放在5000个页中(页page是最小的逻辑存储单元,默认一个页16k大小,系统会给每个页分配一个唯一编号)
2.)如果查询select * from stu where sno=13不使用索引,就是没有主键,外键和 会翻遍所有5000个页,看看页中有没有行记录的sno号值等于13的,
3.)有就符合where条件,将该行记录保留在查询结果集中。
如果每个页挨个都要翻一遍,行记录很多的时候,查询就会很慢
如果在stu表的sno列上创建索引
alter table stu add index idx_sno(sno);
首先会提取stu表中所有记录sno的值,在内存中按照从小到大的顺序排序
排序后的结果形成了很多索引页(page),这个过程由mysql按照算法自动完成,不用过于深究其中的详细过程
索引页之间存在一定的关联关系,一般为树形结构;
分为根节点、分支节点、和叶子节点
根节点页中存放分段sno的起始值,以及值所对应的分支索引页号
分支索引页中存放分段sno的起始值,以及值所对应的叶子索引页号
叶子索引页中存放排序后的sno值,该值所对应的表页号, 下一个叶子索引页的页号
sno建立索引后
select * from stu where sno=13
查询过程如下
第一步 索引页存在关联关系,先找索引页号20的根节点,13在>=11和<17的范围内,需要查找25号索引页
第二步 读取25号索引页,13在>=11和<14范围内,得到了26号叶子索引页
第三步 读取26号叶子索引页,找到了13这个值,以及该值所对应表页的页号161,因为是select * 所有列,目前只得到了sno的值,还要得到sname,sex,height等,因此需要再读一次编号为161的表页,里面存放了sno之外的值
第四步 读取161号表页,获得sname,sex,height等值
以上4步,只读取了3个索引页1个表页,共4个页,比读取所有表页(5000个页),按照sno=13挨个翻一遍效率要高,这也是有些情况下索引可以加速查询的原因
查四个块从小到大的顺序排序
第一步找 根节点
第二步找 分支节点
第三步找 叶子节点
第四步 通过叶子节点来 找 表行数据的内容
7.MySQL索引 使用条件 和 弊端
1.大表(记录数多),仅从中找出少量行(总行数的3%-%5)
例如:
100万个学生中,学号是主键没有重值,仅找1个学生,在学号列上加索引并按照学号来查找会很快找到
例如:
100万s个学生中,学号1到100万,要找学号大于1的学生,这样99%以上的结果都会返回,此时索引没有作用,不能起到加速查询的作用
2.在经常作为查询条件(where)的列上添加索引,返回记录少,就可能用上索引,起到加速查询的作用
3.索引和表的区别是索引页之间存在关联关系,但是会占用额外的磁盘空间,有可能出现索引占的磁盘空间比表还大的情况
例如:
在表上根据常用查询条件,使用多个列建立了索引
4.索引会自动维护,常规的DML操作会导致索引的变化,这会增加服务器的负担,导致DML操作变慢,尤其是一个表有多个索引的情况下
8.索引的分类方式 六种
分类1:按照索引和索引对应其他表列数据是否在一个数据页中
* 聚集索引 clustered index索引的数据 在一个表里(表行数据)
* 非聚集索引 non-clustered index 索引页与表页分离,索引占用额外磁盘空间
分类2:按照索引列是否为主键
* 主键索引 创建表会自动创建主键索引(MySQL主键索引为聚集索引)
* 非主键索引
create table k(id int primary key,name varchar(20));创建id为主键索引
show index from k;
create index k_idx on k(name);创建非主键索引
show index from k;
分类3:按照创建索引的列数
* 单列索引
create index idx_sname on w(id);
* 多列索引(复合索引)
create index idx_cno_sex on stu(cno,sex);
分类4:按照索引值是否可以重复
* 唯一性索引
create unique index idx_t on t(id);即为mysql中的 唯一约束
* 非唯一索引
create index idx_t on t(id);
create table w(id int,name varchar(10));创建唯一索引
create unique index w_idx on w(id);
show index from w;
show create table w;
即为name可以空值 但id不可重复
insert into w values(1,'bbb');上面指定unique 即id唯一不可重复
insert into w values(1,'aaa');插入重复id会报错
insert into w values(2,'');
select * from w;
删除唯一索引
alter table w drop index w_idx;删除w表的w_id的索引
show create table w;查看表
分类5:按照放入索引的列值
* 稠密索引(所有索引列的值都放入索引) MySQL
* 稀疏索引(部分索引列的值都放入索引) DB2可选
分类6:按照形成索引的算法
* B+树索引(MySQL的innodb引擎形成索引的算法为B+树算法)
* B-树索引(Oracle默认堆表索引)
* hash索引(MySQL的memory引擎形成索引的算法为bash算法,范围查询用不上索引,只能等值查找)
注意:
1.主键约束会自动创建索引,主键索引是聚集索引,索引中不能有重复值;
2.外键约束MySQL也会自动创建索引,外键约束的索引是非聚集索引,默认是非唯一索引(因为外键列可以有重复值)
3.唯一性约束MySQL也会自动创建索引,唯一性约束的索引是唯一性索引
4.一个表只能有一个主键约束
因为主键索引是聚集索引,索引值和对应表行数据存放在一起而且按照索引值的顺序存放;同一时刻只能有一种排序方式,
但是可以给主键列之外的列添加多个非空+唯一性约束(效果等同于主键约束)