Python进行图片t-SNE降维可视化
Python进行图片t-SNE降维可视化
- 数据集
- IPython代码
- 参考文献
数据集
https://www.kaggle.com/c/plant-seedlings-classification
下载后解压,把train.zip放在根目录下解压
IPython代码
%matplotlib inline
import os
import cv2
import matplotlib
import numpy as np
from glob import glob
import matplotlib.cm as cm
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from matplotlib.offsetbox import OffsetImage, AnnotationBbox
BASE_DATA_FOLDER = "./"
TRAIN_DATA_FOLDER = os.path.join(BASE_DATA_FOLDER, "train")
def create_mask_for_plant(image):
image_hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
sensitivity = 35
lower_hsv = np.array([60 - sensitivity, 100, 50])
upper_hsv = np.array([60 + sensitivity, 255, 255])
mask = cv2.inRange(image_hsv, lower_hsv, upper_hsv)
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (11,11))
mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel)
return mask
def segment_plant(image):
mask = create_mask_for_plant(image)
output = cv2.bitwise_and(image, image, mask = mask)
return output
def visualize_scatter(data_2d, label_ids, figsize=(20,20)):
plt.figure(figsize=figsize)
plt.grid()
nb_classes = len(np.unique(label_ids))
for label_id in np.unique(label_ids):
plt.scatter(data_2d[np.where(label_ids == label_id), 0],
data_2d[np.where(label_ids == label_id), 1],
marker='o',
color= plt.cm.Set1(label_id / float(nb_classes)),
linewidth='1',
alpha=0.8,
label=id_to_label_dict[label_id])
plt.legend(loc='best')
images = []
labels = []
for class_folder_name in os.listdir(TRAIN_DATA_FOLDER):
class_folder_path = os.path.join(TRAIN_DATA_FOLDER, class_folder_name)
for image_path in glob(os.path.join(class_folder_path, "*.png")):
image = cv2.imread(image_path, cv2.IMREAD_COLOR)
image = cv2.resize(image, (150, 150))
image = segment_plant(image)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = cv2.resize(image, (45,45))
image = image.flatten()
images.append(image)
labels.append(class_folder_name)
images = np.array(images)
labels = np.array(labels)
指定图片格式为.png
等待运行完毕
label_to_id_dict = {v:i for i,v in enumerate(np.unique(labels))}
id_to_label_dict = {v: k for k, v in label_to_id_dict.items()}
label_ids = np.array([label_to_id_dict[x] for x in labels])
id_to_label_dict
{0: 'Black-grass',
1: 'Charlock',
2: 'Cleavers',
3: 'Common Chickweed',
4: 'Common wheat',
5: 'Fat Hen',
6: 'Loose Silky-bent',
7: 'Maize',
8: 'Scentless Mayweed',
9: 'Shepherds Purse',
10: 'Small-flowered Cranesbill',
11: 'Sugar beet'}
images_scaled = StandardScaler().fit_transform(images)
images_scaled.shape
(4750, 2025)
label_ids.shape
(2435,)
plt.imshow(np.reshape(images[734], (45,45)), cmap="gray")
pca = PCA(n_components=180)
pca_result = pca.fit_transform(images_scaled)
pca_result.shape
(4750, 180)
tsne = TSNE(n_components=2, perplexity=40.0)
tsne_result = tsne.fit_transform(pca_result)
tsne_result_scaled = StandardScaler().fit_transform(tsne_result)
visualize_scatter(tsne_result_scaled, label_ids)
等待运行完毕
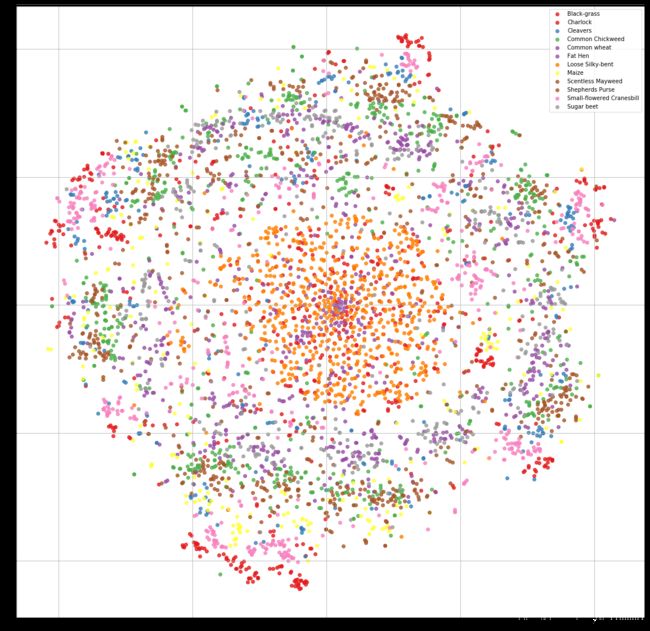
其他图请自行查阅参考文献:
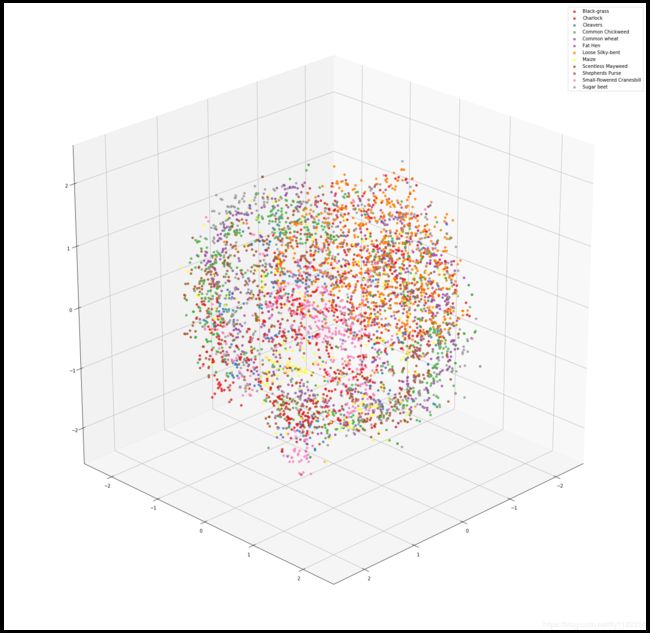
3D图,gif动图看原文献
参考文献
- https://www.kaggle.com/gaborvecsei/plants-t-sne/data
- 从SNE到t-SNE再到LargeVis https://bindog.github.io/blog/2016/06/04/from-sne-to-tsne-to-largevis/