Scrapy爬虫笔记(scrapy、scrapy-redis、scrapyd部署scrapy)
Scrapy爬虫笔记
- 写在最前面
- scrapy安装
- 创建项目与运行爬虫
- 生成爬虫
- scrapy框架目录结构
- settings.py常用设置
- CrawlSpider
- Scrapy Shell
- Request 对象和 Response 对象
- JsonItemExporter、JsonLinesItemExporter
- Request.FormRequest 实现POST表单提交
- 下载文件和图片的Pipeline(Files Pipeline、Images Pipeline)
- 进阶完善
- 下载器中间件 Downloader Middlewares
- 随机请求头中间件(事例)
- ip代理池中间件
- selenium
- Scrapy-redis
- scrapyd部署scrapy项目
- 写在最后
写在最前面
- 官方文档
- 中文
- 英文
- 框架图(不管初学还是老手这个图不要忘记)
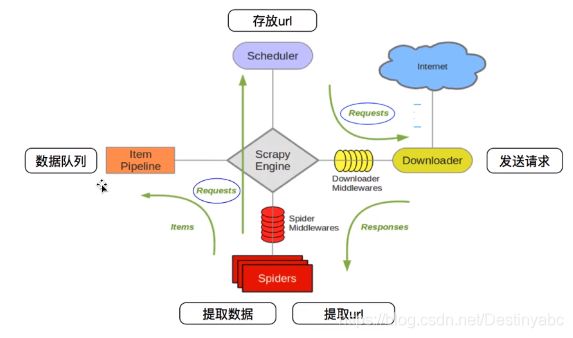
scrapy安装
pip install scrapy
- windows
-
- 报错:*No moudule named ‘win32api’ *
pip install pypiwin32 - windows
-
sudo apt-get install python-dev python-pip libxml2-dev libxstl1-dev zlibiq-dev libffi-dev libssl-devpip install scrapy
pip install pypiwin32
创建项目与运行爬虫
scrapy startproject 项目名称 # 创建
scrapy crawl 爬虫名 # 运行一个爬虫
# 自定义脚本运行爬虫
# 项目目录下 start.py
from scrapy import cmdline
cmdline.execute("scrapy crawl spiderName".split()) # 需要将命令分割才能执行
生成爬虫
# 项目目录下的命令
# 生成普通爬虫
scrapy genspider 爬虫名 欲爬取网站的域名
# 使用模板生成爬虫
scrapy genspider -t crawl 爬虫名 欲爬取网站的域名
scrapy框架目录结构
- demo
项目目录- demo
子目录(与项目目录同名)- spiders
存放爬虫的文件夹- yourSpider.py
编写的爬虫 - 。。。
- yourSpider.py
- items.py
数据模型 - middlewares.py
中间件 - pipelines.py
处理数据、保存数据 - settings.py
配置文件
- spiders
- scrapy.cfg
项目配置文件
- demo
settings.py常用设置
# 无需记忆
ROBOTSTXT_OBEY = False # 设置不遵循robots爬虫协议
# 请求头设置 User-Agent 与 Referer为常用请求头设置
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/79.0.3945.130 Safari/537.36',
'Referer': 'https://www.xxxx.com',
}
ITEM_PIPELINES = {
"demo..pipelines.Mypipeline": 300 # 开启pipeline,并设置优先级,数值越小优先级越高
}
CrawlSpider
scrapy genspider -t crawl demo domain.com # 生成
LinkExtractors 链接提取器 :
- allow 满足条件的url爬取
- follow 跟进(True/False)
- callback 回调处理
Rules 规则类:
省略 . . .
注:spider通过start_request发起请求,可重写(比如加cookies等请求头)
Scrapy Shell
# 项目目录下
scrapy shell url # 可以读取项目配置信息
Request 对象和 Response 对象
- request 对象
| 参数名 | 介绍 |
|---|---|
| url | 请求的url地址 |
| callback | 请求后执行的回调函数(response) |
| method | 请求方法 |
| headers | 请求头 |
| meta | 常用。用于在不同的请求之间传递数据 |
| encoding | 编码(默认utf-8) |
| dot_filter | 表示不由调度器过滤,在执行多次重复的请求时常用(如:登录验证) = False |
| errback | 发生错误时的回调函数 |
- response 对象
| 参数名 | 介绍 |
|---|---|
| url | 本次请求的url |
| meta | 从其他请求传来的meta |
| encoding | 返回当前字符串编和解码格式 |
| text | 将返回来的数据作为unicode字符串返回 |
| body | 将返回来的数据作为 bytes 字符串返回 |
| xpath | xpath选择器 |
| css | css选择器 |
JsonItemExporter、JsonLinesItemExporter
from scrapy.exports import JsonItemExporter # JsonLinesItemExporter
class DemoPipeline(Object):
def __init__(self):
self.fp = open("test.json", "wb")
# ex: self.exporter = JsonLinesItemExporter(self.fp, ensure_ascii=False, encoding='utf-8')
self.exporter = JsonItemExporter(self.fp, ensure_ascii=False, encoding='utf-8')
self.exporter.start_exporting()
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self,spider):
self.exporter.finish_exporting()
self.fp.close()
Request.FormRequest 实现POST表单提交
...
# 重写 start_requests
def start_requests(self):
url = ''
data = {...}
yield scrapy.FormRequest(url, formdata=data, callback=self.parse_page)
# url: 请求url
# formdata: 表单数据
# callback: 回调函数
...
scrapy.FormRequest.form_response(response, formdata=data) # 自动从response中寻找表单(注意多表单情况)
下载文件和图片的Pipeline(Files Pipeline、Images Pipeline)
scrapy 内置下载文件的方法
- 优势:去重,方便指定文件路径,可以将下载的图片转换成通用格式(png、jpg)
可以方便的生成缩略图,可以方便的检测图片的宽高,确保他们满足大小限制,异步下载,效率高
# 普通方式
from urllib import request
...
request.urlretrieve(url,path)
...
| 步骤 | Files Pipeline Images Pipeline |
|---|---|
| 1.定义Item | file_urls,files #=#=#=# image_urls,images |
| 2.spider中使用 | from demo.items import DemoItem; yield DemoItem([args]) |
| 3.配置settings.py | FILES_STORE #=#=#=# IMAGES_STORE |
| 4.启动Pipeline | ITEM_PIPELINES中设置scrapy.pipelines.Images.ImagesPipeline:1 |
进阶完善
重写ImagesPipeline
from scrapy.pipelines.images import ImagesPipeline
class MyPipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None):
path = super(MyPipeline,self).file_path(request, response, info)
category = request.item.get('category')
images_store = settings.IMAGES_STORE
category_path ...
image_name = path.replace('full/',"")
return os.path.join(category_path,image_name)
# 方法重写,为了传递item(传值)
def get_media_requests(self, item, info):
request_objs = super(MyPipeline,self).get_media_requests(item, info)
for request_obj in request_objs:
request_obj.item = item
return request_objs
下载器中间件 Downloader Middlewares
写在middlewares.py中
- process_request(self,request,spider)
- 参数:request spider
- 返回值
- 返回None:scrapy将继续处理该request,执行其他中间件中的相应的方法,直到合适的下载器处理函数被调用
- 返回response对象
- 返回request对象:不再使用之间的request对象去下载数据,而是根据现在返回的request对象返回数据
- 异常:则会调用process_exception方法
- process_response(self, request, response, spider)
- 参数:request response spider
- 返回值:
- 返回response对象
- 返回request对象:下载器键被切断,返回的request会重新被下载器调度下载
- 异常:调用request的errback方法,如果没有指定这个方法会抛出一个异常
随机请求头中间件(事例)
settings.py中设置
DOWNLOADER_MIDDLEWARES={‘相对路径’: 543} # 权值
import random
class UserAgentDownloadMiddleware(Object):
USER_AGENTS={..,..,..,..}
def process_request(self,request,spider):
user_agent = random.choice(self.USER_AGENTS)
request.headers['User-Agent'] = user_agent
ip代理池中间件
import random
class IPProxyDownloadMiddleware(Object):
PROXIES = [..,..,..,..,..,'ip:port']
def process_request(self,request,spider):
proxy = random.choice(self,PROXIES)
request.meta['proxy'] = proxy # 注意
独享代理(用密码的)
import base64
...
proxy = 'xxx.xxx.xxx.xx:xxx'
user = '1465465415:asdfasdf'
request.meta['proxy'] = proxy
b64_user = base64.b64encode(user.encode('utf-8'))
request.header['Proxy-Authorization'] = 'Basic' + b64_user.decode('utf-8')
...
selenium
此处省略
Scrapy-redis
pip install scrapy-redis
框架图(同scrapy框架图要熟记):
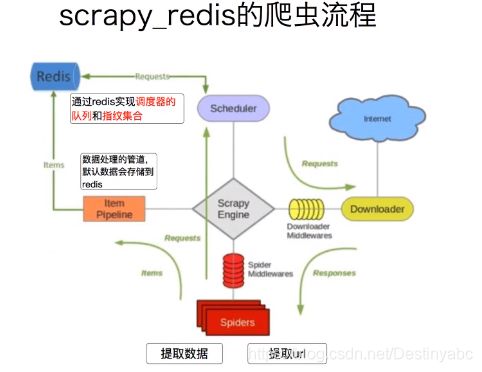
settings.py
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.scheduler"
SCHEDULER_PERSIST = True # 持久化
# pipeline
...
{
'scrapy_redis.pipelines.RedisPipeline':400 # 开启pipeline。权值而已
}
# REDIS_URL = 'redis://127.0.0.1:6379'
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
REDIS_PARAMS = {
'password':'yourpassword'
}
scrapyd部署scrapy项目
pip install scrapyd
pip install scrapyd-client # 客户端工具
windows端的额外工作:
scrapyd-deploy.bat@echo off "path\to\python.exe" "path\to\Scripts\scrapyd-deploy" %1 %2 %3 %4 %5 %6 %7 %8 %9
- scrapy.cfg的配置
[deploy:app] # :app 别名 项目别名
url = http://127.0.0.1:6800/ # scrapyd服务端url
project = tgod # 真正的项目名
- 启动scrapyd服务端 scrapyd配置文件
- 项目目录下运行 scrapyd-deploy app -p tgod
- 到此部署成功
命令(建议直接手册,别处都不是标准):scrapyd手册
注意:
- scrapyd web页面:http://127.0.0.1:6800
- 启动爬虫的curl中 … -d spider=demo # demo 是你要启动的爬虫name,对应你的单个爬虫
- Ubuntu用户用ufw设置防火墙允许网段或ip
写在最后
欢迎留言私信讨论;
文章有知识性错误请立马联系博主,博主将非常感谢;
无需经过允许即可随意使用转载,知识本来就是被广泛用来学习的。
非常感谢您能看到此处,本文为博主学习笔记,如有不同见解,请不吝赐教;