nginx总结
一 安装与配置
nginx定位:
web服务器,负载均衡器(反向代理服务器),缓存服务器,电子邮件服务器
安装
nginx编译第三方模块
eg: nginx编译ngx_http_upstream_consistent_hash模块:
查看当前版本的nginx的编译配置:
/usr/local/nginx/sbin/nginx -V
---------
下载ngx_http_upstream_consistent_hash
https://github.com/replay/ngx_http_consistent_hash
unzip解压
---------
进入nginx安装包目录,重新configure
./configure --prefix=....(之前的编译配置) --add-module=PATH(第三方模块的位置)
---------
pkill -9 nginx or kill -9 nginx.pid
make clean
make && make install
二 nginx启动与停止
启动:
- service nginx configtest 测试ngxin配置文件有没有语法错误
- ./nginx
- 按照某个特定的ngxin.conf启动:
例如在myopenresty下新建conf和logs文件夹,在conf下新建nginx.conf,则启动nginx:
nginx -p myopenresty
启动后myopenresty多了其他文件:
myopenresty/
├── client_body_temp
├── conf
│ └── nginx.conf
├── fastcgi_temp
├── logs
│ ├── access.log
│ ├── error.log
│ └── nginx.pid
├── proxy_temp
├── scgi_temp
└── uwsgi_temp
重启:
- ./nginx -s restart/reload
- service nginx restart
- kill -HUP pid
kill -HUP `cat /usr/local/nginx/logs/nginx.pid`
- kill -SIGHUP pid
不重启,重读配置文件:
- nginx -s reopen
- kill -USR1 'cat /usr/local/nginx/logs/nginx.pid' 重读日志(分割日志时用)
kill -USR2 'cat /usr/local/nginx/logs/nginx.pid' 平滑的升级
立刻停止:
./nginx -s stop
killall nginx
kill -9 masterpid
pkill -9 nginx
处理完当前任务后退出:./nginx -s quit
杀掉某个worker
kill -SIGTERM pid 但是这样master会立马再启一个worker
三 ngxin的配置
1 http配置
- timeout参数设置
client_header_timeout:
语法 client_header_timeout time
默认值 60s
上下文 http server
说明 指定等待client发送一个请求头的超时时间(例如:GET / HTTP/1.1).仅当在一次read中,没有收到请求头,才会算成超时。如果在超时时间内,client没发送任何东西,nginx返回HTTP状态码408(“Request timed out”)
client_body_timeout
语法 client_body_timeout time
默认值 60s
上下文 http server location
说明 该指令设置请求体(request body)的读超时时间。仅当在一次readstep中,没有得到请求体,就会设为超时。超时后,nginx返回HTTP状态码408(“Request timed out”)
keepalive_timeout
语法 keepalive_timeout timeout [ header_timeout ]
默认值 75s
上下文 http server location
说明 第一个参数指定了与client的keep-alive连接超时时间。服务器将会在这个时间后关闭连接。可选的第二个参数指定了在响应头Keep-Alive:timeout=time中的time值。这个头能够让一些浏览器主动关闭连接,这样服务器就不必要去关闭连接了。没有这个参数,nginx不会发送Keep-Alive响应头(尽管并不是由这个头来决定连接是否“keep-alive”)两个参数的值可并不相同
注意不同浏览器怎么处理“keep-alive”头
MSIE和Opera忽略掉"Keep-Alive: timeout=" header.
MSIE保持连接大约60-65秒,然后发送TCP RST
Opera永久保持长连接
Mozilla keeps the connection alive for N plus about 1-10 seconds.
Konqueror保持长连接N秒
proxy_connect_timeout
说明 该指令设置与upstream server的连接超时时间,有必要记住,这个超时不能超过75秒。
这个不是等待后端返回页面的时间,那是由proxy_read_timeout声明的。如果你的upstream服务器起来了,但是hanging住了(例如,没有足够的线程处理请求,所以把你的请求放到请求池里稍后处理),那么这个声明是没有用的,由于与upstream服务器的连接已经建立了。
proxy_read_timeout
语法 proxy_read_timeout time
默认值 60s
上下文 http server location
说明 该指令设置与代理服务器的读超时时间。它决定了nginx会等待多长时间来获得请求的响应。这个时间不是获得整个response的时间,而是两次reading操作的时间。
proxy_send_timeout
语法 proxy_send_timeout time
默认值 60s
上下文 http server location
说明 这个指定设置了发送请求给upstream服务器的超时时间。超时设置不是为了整个发送期间,而是在两次write操作期间。如果超时后,upstream没有收到新的数据,nginx会关闭连接
proxy_upstream_fail_timeout
语法 server address [fail_timeout=30s]
默认值 10s
上下文 upstream
说明 Upstream模块下 server指令的参数,设置了某一个upstream后端失败了指定次数(max_fails)后,该后端不可操作 的时间,默认为10秒
线上配置:
client_header_timeout 20s;
client_body_timeout 20s;
keepalive_timeout 120;
- buffer参数设置
client_header_buffer_size
large_client_header_buffers
client_body_buffer_size
client_max_body_size
- 访问控制
1 limit_conn 限制并发连接数
limit_conn_zone $binary_remote_addr zone=conn_zone:1m;
eg1:
server{
...
location / {
limit_conn conn_one 1; //用一个ip同一时间内只允许有一个连接
}
}
eg2 :
limit_conn_zone $binary_remote_addr zone=perip:10m;
server {
location / {
limit_conn perip 1;
limit_conn_status 503; #超出连接数就返回给客户端的状态码,可以自定义
limit_conn_log_level error; #超过限制则记录一条日志
limit_rate 50; #每秒钟返回50字节,这样容易触发限制条件(即响应很慢,第一个请求还没结束,然后又建立新连接,则会触发限制条件,返回503)
root html;
fastcgi_pass 127.0.0.1:9000;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
index phpinfo.php index.html;
}
}
2 limit_req 限制请求速率
limit_req_zone: 定义共享内存,以及key关键字和限制速率,生效在http段内
limit_req zone=name [burst=number] [nodelay]; 生效在location或server中的指令
limit_req_log_level info|notice|warn|error| :发生限速时打印的日志级别
limit_req_status code; 返回给客户端的状态码
配置范例:
http{
limit_req_zone $binary_remote_addr zone=req_zone:1m rate=1r/s;
#对于某个ip,限制其每秒只能发起一个请求
server{
...
location / {
# limit_req zone=req_zone;
limit_req zone=req_zone burst=3 nodelay; //多接收3个请求,作为延迟响应,其他的一律返回503,服务器繁忙:503 Service Temporarily Unavailable
}
}
}
ab压测: ab -n 50 -c 10 http://test.com/1.html
查看error日志,可以看到对应的错误信息
注意:
1 连接数和请求数不是一个概念,连接指的是TCP连接,请求指的是HTTP请求,HTTP请求是在TCP连接建立的基础之上发起的,一个连接中可以有很多个请求。可以把连接理解为桥,请求理解为桥上过的车辆,limit_conn 限制了桥的数量,limit_req限制了桥上车的数量。
2 如果同时配置了limit_conn和limit_req,并且同时满足限制条件,则limit_req优先生效,limit_conn没有机会执行。
3 两者都生效于preaccess阶段。
2 server配置
指令1:server_name
server_name优先级配置问题
nginx会按照读取server的优先级顺序来进行虚拟主机的寻找和匹配
例如
server1.conf
server {
server_name server1 zhangbao1;
...
}
server2.conf
server {
server_name server2 zhangbao1;
...
}
当访问zhangbao.com时,会匹配中server1,因为按照字母顺序server1优先被nginx读取。
如果是基于ip的虚拟主机配置,每一个server里都没有配置该ip,那么nginx就会默认匹配到它最先读取的那个server配置里去
3 location配置
匹配规则:(优先级依次降低)
location = /uri:精确匹配,优先级最高
location ^~ /uri:前缀匹配,最大匹配原则,同时会禁止正则匹配
location ~ pattern:区分大小写的正则匹配 (正则与正则之间的优先级是按照位置顺序来的)
location ~* pattern:不区分大小写的正则匹配
location /uri: 不带任何修饰符的前缀匹配
location / :根匹配
优先级排序:匹配越精确,优先级越高
nginx在匹配location的步骤是:
先遍历所有的前缀匹配,找出最长的那个,记住它
if 最长的是带有 location ^~ /uri的
return (该匹配结果)
else 最长的是普通的 location /uri的
for (按照先后出现的次序查找 ~ ~*)
if (找到了) {return }
end
end
最后找不到~ 和 ~* ,则return 之前记住的那个最长的前缀匹配
server {
server_name location.test.com;
location ~ /Test/$ {
return 200 'first regular expressions match!\n';
}
location ~* /Test1/(\w+)$ {
return 200 'longest regular expressions match!\n';
}
location ^~ /Test1/ {
return 200 'stop regular expressions match!\n';
}
location /Test1/Test2 {
return 200 'longest prefix string match!\n';
}
location /Test1 {
return 200 'prefix string match!\n';
}
location = /Test1 {
return 200 'exact match!\n';
}
}
依次访问:
[root@zhangbao geek]# curl -x 127.0.0.1:80 location.test.com/Test1
exact match!
[root@zhangbao geek]# curl -x 127.0.0.1:80 location.test.com/Test1/
stop regular expressions match!
[root@zhangbao geek]# curl -x 127.0.0.1:80 location.test.com/Test1/Test2
longest regular expressions match!
[root@zhangbao geek]# curl -x 127.0.0.1:80 location.test.com/Test1/Test2/
longest prefix string match!
[root@zhangbao geek]# curl -x 127.0.0.1:80 location.test.com/test1/Test2
longest regular expressions match!
变换了几个location的位置依然是这个结果。
分析:
location.test.com/Test1/Test2匹配的是
eg1:
```php
location ~ \.(gif|jpg|png|js|css)$ {
echo "规则D";
}
location /img {
echo "规则Y";
}
eg2:
location ~ \.(gif|jpg|png|js|css)$ {
echo "规则D";
}
location ~* \.png {
echo "规则E";
}
访问 http://localhost/img/a.png 会匹配上规则D和规则E,但是规则D出现在规则E的前面,因此优先选中规则D。
注意: ~ xxx 之间有空格
xxx$和{ 之间有空格
error_page
测试场景: 请求--->10.99.2.15--->10.99.1.51
10.99.2.15上的配置如下:
location /test2/ {
root /usr/local/openresty/nginx/html;
proxy_pass http://zhouzhongtao2/;
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
#proxy_next_upstream http_500 http_502 http_503 http_504 http_403 http_404;
proxy_next_upstream off;
error_page 500 /SystemMaintenance.html;
}
错误页并没有生效, 浏览器上直接显示: 500 Internal Server Error
修改如下:将error_page指令配置到后端的10.99.1.51上,配置如下:
server {
listen 1998;
root /usr/local/openresty/nginx/html;
default_type text/html;
location / {
content_by_lua_block {
ngx.say(ngx.worker.pid())
ngx.say(1998)
}
}
location /health_check {
return 500;
}
error_page 500 /SystemMaintenance.html;
access_log /usr/local/openresty/nginx/logs/test.balancer.com_access.log main;
}
发现还是没有生效,错误页面还是没有显示出来,反而变成了 pid 1998
然后将配置改成如下:
server {
listen 1998;
root /usr/local/openresty/nginx/html;
default_type text/html;
location /health_check {
return 500;
}
error_page 500 /SystemMaintenance.html;
access_log /usr/local/openresty/nginx/logs/test.balancer.com_access.log main;
}
去掉了, 结果显示出来了。
结论: 1 error_page需要配置在真正处理请求的nginx上,上例中就应该配置在后端的10.99.1.51上
2 error_page /50.html 本质是nginx遇到500错误,又在内部发起了一次请求,uri为/50.html, 刚才因为location / {} 里面已经有了lua处理,去掉该段走默认的localtion /就行。
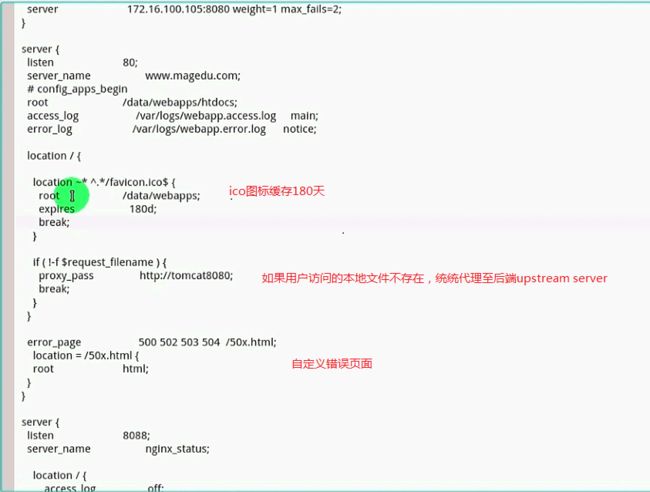
expires相关
在访问量比较大的网站中,利用客户端来缓存网站上不经常变更的图片,是给服务器减压的一个很方便且实用的做法
比如,网站的 logo, 企业上传的各种资格证书的图片,甚至有些商品的效果大图,只是不是经常变更的,大都可以让其存在客户端,提高访问速度,减小服务器的压力
对nginx 来说,实现的方法很简单,只要在location段中,使用 expires 就可以了
格式:
expires 30s; //表示把数据缓存30秒
expires 30m;//表示把数据缓存30分
expires 10h;//表示把数据缓存10小时
expires 1d;//表示把数据缓存1天
配置范例:
我想把网站上的图片都让客户端来缓存3天,在nginx 中配置如下
location ~* \.(gif|jpg|jpeg|png) {
root /var/mywww/html/public/
expires 3d;
}
上面表示,网站上所有的用正则匹配(不区分大小写) 所有以gif,jpg,png,jpeg结尾的文件,把它们放入客户端的缓存,3天不失效
注意和proxy_cache区别开,一个是在客户端缓存,一个是在浏览器端缓存
buffer:
1 限制header大小
client_header_buffer_size
large_client_header_buffers
这个buffer的大小通过配置项client_header_buffer_size来设置,如果用户的请求头太大,这个buffer装不下,那nginx就会重新分配一个新的更大的buffer来装请求头,这个大buffer可以通过large_client_header_buffers来设置,这个large_buffer这一组buffer,比如配置4 8k,就是表示有四个8k大小的buffer可以用。注意,为了保存请求行或请求头的完整性,一个完整的请求行或请求头,需要放在一个连续的内存里面,所以,一个完整的请求行或请求头,只会保存在一个buffer里面。这样,如果请求行大于一个buffer的大小,就会返回414错误,如果一个请求头大小大于一个buffer大小,就会返回400错误。在了解了这些参数的值,以及nginx实际的做法之后,在应用场景,我们就需要根据实际的需求来调整这些参数,来优化我们的程序了。
2 针对POST请求上传的body大小限制:
client_max_body_size 500m; 单次请求最大不能超过500m
client_body_buffer_size 128k 对请求的缓冲区大小,缓存区满了,向后端转发
client_body_temp_path /tmp/nginx/upload/client_tmp 1 2; 如果配置了,则缓冲区满了,会写到临时文件中
详解: P49
return
语法:
return code [text]
return code URL;
return URL;
context: server,location ,if
例子:
nginx自定义
444 关闭连接,nginx立刻关闭连接,不像客户端返回任何信息
http 1.0标准
301: http1.0永久重定向,浏览器会记录到自己的缓存中,直接访问重定向之后的地址
302: 临时重定向,禁止被缓存
http1.1标准
303: 临时重定向,允许改变方法,禁止被缓存
307: 临时重定向,不允许改变方法,禁止被缓存
308: 永久重定向,不允许改变方法
(4) ssl
参考:https://blog.csdn.net/duyusean/article/details/79348613
nginx 内置变量
1 与http相关
响应:
body_bytes_sent : 响应中body包体的长度
bytes_sent : 全部http响应的长度
status : http返回码
sent_trailer_name : 把响应结尾内容里值返回
sent_http_name : 响应中某个具体头部的值
sent_http_content_type:
sent_http_content_length:
sent_http_location
sent_http_last_modified:
sent_http_connection
sent_http_keep_alive
sent_http_cache_control
sent_http_link
2 与tcp相关
binary_remote_addr :客户端地址的整型格式,对于IPV4是4字节,对于IPV6是16字节
connection : 递增的连接序号
connection_requests: 当前连接上执行过的请求数,对keepalived有意义
remote_addr:客户端地址
remote_port : 客户端端口
proxy_protocol_addr : 若使用了proxy_protocol协议则返回协议中的地址,否则则返回空
proxy_protocol_port : 若使用了proxy_protocol协议则返回协议中的端口,否则则返回空
server_addr : 服务器端地址
server_port :服务器段ip
server_protocol : 服务器端协议,例如HTTP/1.1
request_time : 请求处理到现在的耗时,单位为秒,精确到毫秒
server_name : 匹配上请求的server_name值
https : 如果开启了TLS/SSL,则返回on,否则则为空
request_completion: 若请求处理完则返回OK,否则返回空
request_id:以16进制输出的请求标识id,该id共有16字节,是随机生成的
requet_filename:待访问文件的完整路径
document_root: 由URI和root/alias规则生成的文件夹路径
realpath_root : 将document_root中的软链接等换成真实路径
limit_rate: 返回客户端响应时的速度上限,单位为每秒字节数,可以通过set指令修改对请求产生效果
3 系统变量
time_local : 以本地时间标准输出的当前时间,例如14/Nov/2018:15:55:37 +0800
time_iso8601 :使用ISO8601标准输出的当前时间,例如2018-11-14T15:55:37+08:00
nginx_version :Nginx版本号
pid : 所属worker进程的进程id
pipe : 使用了管道则返回p,否则返回.
hostname : 所在服务器的主机名,与hostname命令输出一致
msec :1970年1月1号到现在的时间,单位为秒,小数点后精确到毫秒
参考:https://www.jb51.net/article/77593.htm
Nginx 内建变量最常见的用途就是获取关于请求或响应的各种信息。例如由 ngx_http_core 模块提供的内建变量 $uri,可以用来获取当前请求的 URI(经过解码,并且不含请求参数),而 $request_uri 则用来获取请求最原始的 URI (未经解码,并且包含请求参数)。
- $server_addr :当前nginx服务器的地址
- $document_root 被访问文件的根目录
当http段和server段和location段同时定义了root 时,$document_root以location为准,再以server为准,最后以http为准。
- $fastcgi_script_name 变量等同于请求 URI
eg: www.test.com/2.php 则$fastcgi_script_name=/2.php
- $upstream_cache_status :reponse对应的上游服务器的缓存状态,MISS|BYPASS|EXPIRED|STALE|UPDATING|REVEAL_IDATED|HIT
注意:配置了upstream模块并开启了cache功能后才有该变量,因为该变量是upstream模块的内嵌变量。
- $scheme 表示URL中是http还是https,例$scheme://www.baidu.com 等于:http(s)://www.baidu.com
例:http://localhost:88/test1/test2/test.php?k=v
$host:localhost
$server_port:88
$request_uri:/test1/test2/test.php?k=v
$document_uri:/test1/test2/test.php
$document_root:D:\nginx/html
$request_filename:D:\nginx/html/test1/test2/test.php
$args #请求中的参数值
$query_string #同 $args
$arg_NAME #GET请求中NAME的值
$is_args #如果请求中有参数,值为"?",否则为空字符串
$uri #请求中的当前URI(不带请求参数,参数位于$args),可以不同于浏览器传递的$request_uri的值,它可以通过内部重定向,或者使用index指令进行修改,$uri不包含主机名,如"/foo/bar.html"。
$document_uri #同 $uri
$document_root #当前请求的文档根目录或别名
$host #优先级:HTTP请求行的主机名>"HOST"请求头字段>符合请求的服务器名
$hostname #主机名
$https #如果开启了SSL安全模式,值为"on",否则为空字符串。
$binary_remote_addr #客户端地址的二进制形式,固定长度为4个字节
$body_bytes_sent #传输给客户端的字节数,响应头不计算在内;这个变量和Apache的mod_log_config模块中的"%B"参数保持兼容
$bytes_sent #传输给客户端的字节数
$connection #TCP连接的序列号
$connection_requests #TCP连接当前的请求数量
$content_length #"Content-Length" 请求头字段
$content_type #"Content-Type" 请求头字段
$cookie_name #cookie名称
$limit_rate #用于设置响应的速度限制
$msec #当前的Unix时间戳
$nginx_version #nginx版本
$pid #工作进程的PID
$pipe #如果请求来自管道通信,值为"p",否则为"."
$proxy_protocol_addr #获取代理访问服务器的客户端地址,如果是直接访问,该值为空字符串
$realpath_root #当前请求的文档根目录或别名的真实路径,会将所有符号连接转换为真实路径
$remote_addr #客户端地址
$remote_port #客户端端口
$remote_user #用于HTTP基础认证服务的用户名
$request #代表客户端的请求地址
$request_body #客户端的请求主体:此变量可在location中使用,将请求主体通过proxy_pass,fastcgi_pass,uwsgi_pass和scgi_pass传递给下一级的代理服务器
$request_body_file #将客户端请求主体保存在临时文件中。文件处理结束后,此文件需删除。如果需要之一开启此功能,需要设置client_body_in_file_only。如果将次文件传递给后端的代理服务器,需要禁用request body,即设置proxy_pass_request_body off,fastcgi_pass_request_body off,uwsgi_pass_request_body off,or scgi_pass_request_body off
$request_completion #如果请求成功,值为"OK",如果请求未完成或者请求不是一个范围请求的最后一部分,则为空
$request_filename #当前连接请求的文件路径,由root或alias指令与URI请求生成
$request_length #请求的长度 (包括请求的地址,http请求头和请求主体)
$request_method #HTTP请求方法,通常为"GET"或"POST"
$request_time #处理客户端请求使用的时间; 从读取客户端的第一个字节开始计时
$request_uri #这个变量等于包含一些客户端请求参数的原始URI,它无法修改,请查看$uri更改或重写URI,不包含主机名,例如:"/cnphp/test.php?arg=freemouse"
$scheme #请求使用的Web协议,"http" 或 "https"
$server_addr #服务器端地址,需要注意的是:为了避免访问linux系统内核,应将ip地址提前设置在配置文件中
$server_name #服务器名
$server_port #服务器端口
$server_protocol #服务器的HTTP版本,通常为 "HTTP/1.0" 或 "HTTP/1.1"
$status #HTTP响应代码
$time_iso8601 #服务器时间的ISO 8610格式
$time_local #服务器时间(LOG Format 格式)
$cookie_NAME #客户端请求Header头中的cookie变量,前缀"$cookie_"加上cookie名称的变量,该变量的值即为cookie名称的值
$http_NAME #匹配任意请求头字段;变量名中的后半部分NAME可以替换成任意请求头字段,如在配置文件中需要获取http请求头:"Accept-Language",$http_accept_language即可
$http_cookie
$http_post
$http_referer
$http_user_agent
$http_x_forwarded_for
$sent_http_NAME #可以设置任意http响应头字段;变量名中的后半部分NAME可以替换成任意响应头字段,如需要设置响应头Content-length,$sent_http_content_length即可
$sent_http_cache_control
$sent_http_connection
$sent_http_content_type
$sent_http_keep_alive
$sent_http_last_modified
$sent_http_location
$sent_http_transfer_encoding
测试代码:
nginx location配置:
location ~ /TestVar {
default_type text/plain;
echo $remote_addr;
echo $request_uri;
echo $document_uri;
echo $uri;
echo $query_string;
echo $args;
echo $is_args;
echo $http_x_forwarded_for;
}
浏览器访问:
http://test.com/TestVar?a=1&b=2
输出结果:
10.10.20.133
/TestVar?a=1&b=2
/TestVar
/TestVar
a=1&b=2
a=1&b=2
?
最后一个http_x_forwarded_for没有值。



四 nginx模块
官方提供了5个类型的模块:核心模块、配置模块、事件模块、http模块、mail模块。
配置模块主要负责解析nginx.conf文件,是其他模块的基础,该类模块中只有一个ngx_conf_module模块;
核心模块主要负责定义除配置模块之外的其他模块,该类模块中有6个核心模块。
ngx_mail_module负责定义mail模块;
ngx_http_module负责定义http模块;
ngx_events_module负责定义事件模块;
ngx_core_module则是nginx启动加载的第一个模块,它主要用来保存全局配置项。
ngx_openssl_module只有当加载了之后,nginx才支持https请求
ngx_errlog_module
事件模块即负责事件的注册、分发处理、销毁等,该类模块中主要有这几个模块:
ngx_event_core_module负责加载其他事件模块,是其他事件模块的基础
ngx_epoll_module,该模块则是我们后面需要重点分析的模块,它负责事件的注册、集成、处理等
其他的模块比如ngx_kqueue_module这些我们后面基本不会涉及,就不解释了,毕竟是另外一种I/O多路复用机制,大致的思想是一样的
http模块和mail模块也无需太多解释,等到后面再介绍。

core模块
1 static模块
配置root和alias
root:
浏览器访问:http://test.com/download1/zhangbao/1.html
(1) 前缀匹配
location /download1/ {
root /usr/local/mywork/test/html;
}
或者:
location /download1/ {
root /usr/local/mywork/test/html/;
}
或者:
location /download1 {
root /usr/local/mywork/test/html;
}
或者:
location /download1 {
root /usr/local/mywork/test/html/;
}
(2) 正则匹配
location ~ ... 重复上述四种情况,
以上八种情况:
curl -x 10.99.2.15:80 static.test.com/download1/zhangbao/1.html
==> /usr/local/mywork/test/html/download1/1.html
curl -x 10.99.2.15:80 static.test.com/download1/1.html
==> /usr/local/mywork/test/html/download1/zhangbao/1.html
总结: root不论哪种匹配方式,不论root最后加没加/,访问的都是root_path+uri
alias:
浏览器访问:http://test.com/download2/zhangbao/1.html
(1) 前缀匹配:
location /download2/ {
alias /usr/local/mywork/test/html;
}
location /download2/ {
alias /usr/local/mywork/test/html/;
}
location /download2 {
alias /usr/local/mywork/test/html;
}
location /download2 {
alias /usr/local/mywork/test/html/;
}
===> 以上四种情况:
/usr/local/mywork/test/htmlzhangbao/1.html
/usr/local/mywork/test/html/zhangbao/1.html
/usr/local/mywork/test/html/zhangbao/1.html
/usr/local/mywork/test/html//zhangbao/1.html
(2) 正则匹配:
location ~ /download2/ {
alias /usr/local/mywork/test/html;
}
location ~ /download2/ {
alias /usr/local/mywork/test/html/;
}
location ~ /download2 {
alias /usr/local/mywork/test/html;
}
location ~ /download2 {
alias /usr/local/mywork/test/html/;
}
===> 以上四种情况:
1和3:
403错误:日志显示 directory index of "/usr/local/mywork/test/html" is forbidden,request: "GET /download/zhangba/1.html/ HTTP/1.1"
2和4:
301无限重定向:浏览器地址栏目是:http://test.com/download/web/1.html/index.html/index.html/index.html/index.html/index.html/index.html/index.html/index.html/index.html/index.html/index.html/index.html/index.html/index.html/index.html/index.html/index.html/index.html/
解释:
1和3: 当配置的server或者location没有指定首页时,找不到文件,会报403错误。
2和4static模块实现了root/alias功能时,发现访问目标是目录,但URL末尾未加/时,会返回301重定向。
absolute_redirect,port_in_redirect,server_name_in_redirect 可以控制
总结:
看来对于alias来说,用不带修饰符的前缀匹配方式比较合适,而且处理逻辑和proxy_pass的一样,将匹配中的部分去掉后再拼接
而alias不适合用正则匹配,可能有意想不到的错误。
2 autoindex模块
展示目录结构
server {
server_name autoindex.test.com;
location / {
alias /usr/local/mywork/test/;
autoindex on;
autoindex_exact_size off;
autoindex_format html;
autoindex_localtime on;
}
}
http模块
1 ngx_http_proxy_module
-
作用:实现反向代理及缓存功能
-
反向代理指令proxy_*介绍
配置范例:
location / {
proxy_pass http://github.com;
proxy_redirect off;
proxy_set_header HOST $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
1 proxy_redirect :
语法:proxy_redirect [ default|off|redirect replacement ]
默认值:proxy_redirect default
使用字段:http, server, location
如果需要修改从被代理服务器传来的应答头中的"Location"和"Refresh"字段,可以用这个指令设置。
假设被代理服务器返回Location字段为: http://localhost:8000/two/some/uri/
这个指令:
proxy_redirect http://localhost:8000/two/ http://frontend/one/;
将Location字段重写为http://frontend/one/some/uri/。
参考连接:https://blog.csdn.net/u010391029/article/details/50395680
2 proxy_set_header :
上下文: http、server、location
默认: proxy_set_header Host $proxy_host;
proxy_set_header Connection close;
注意:
(1)http段,server段,location段同时配置了proxy_set_header时,只有location中会生效,例如:
http{
proxy_set_header xxx1 A
proxy_set_header xxx2 B
location / {
proxy_set_header xxx3 C
}
}
A和B都不会生效,除非去除C!
(2) 若value的值为空(‘ ’),则整个header都不会向上游发送
3 proxy_method
Syntax: proxy_method method;
Default: —
Context: http, server, location
4 proxy_http_version
Syntax: proxy_http_version 1.0 | 1.1;
Default: proxy_http_version 1.0;
Context: http, server, location
5 proxy_pass_request_headers
Syntax: proxy_pass_request_headers on | off;
Default: proxy_pass_request_headers on;
Context: http, server, location
6 proxy_pass_request_body 和 proxy_set_body
生成发往上游的包体
Syntax: proxy_pass_request_body on | off;
Default: proxy_pass_request_body on;
Context: http, server, location
Syntax: proxy_set_body value;
Default: —
Context: http, server, location
7 缓存指令proxy_cache
ngxin缓存功能只需要proxy_cache_path和proxy_cache两个指令就可开启。但是大型的网站中,nginx的缓存功能用的不多,而是用更加专业的缓存varnish和memache
开启与关闭:
Syntax: proxy_cache zone | off;
Default:
proxy_cache off;
Context: http, server, location
缓存路径:
proxy_cache_path /data/nginx/cache levels=1:2 keys_zone=mycache:10m max-size=10g inactive=60m;
则缓存文件可能形式为:/data/nginx/cache/c/29/b7f54b2df7773722d382f4809d65029c
配置范例:
location /{
proxy_cache mycache;
proxy_cache_valid 200 1d; //设置缓存有效时间
proxy_cache_valid 302 1h;
proxy_cache_valid any 10m;
proxy_cache_use_stale error timeout http_500 http_502 http_503 http_504; //在上述情况下使用它不新鲜的缓存,没有总比陈旧强
proxy_cache_method GET 只对GET方法缓存
proxy_cache_min_uses 10; 至少被访问10,才被缓存
proxy_cache_bypass string; 设置在何种情况下ngxin不从缓存中取数据,一般私有数据不能用公共缓存 $cookie_nocache $arg_nocache $http_authorization
proxy_pass http://10.99.2.15;
proxy_set_header X-Real-Ip $remote_addr
}
踩过的坑:
浏览器:http://test.proxy.com/test/science/getinfo?a=1&b=2
(1)
location ~ /test/(.*) {
proxy_pass http://10.99.1.51;
upstream接收到的请求:/test/science/getinfo?a=1&b=2
(2)
location ~ /test/(.*) {
proxy_pass http://10.99.1.51/;
upstream test_up{
server 10.99.1.51;
}
location ~ /test {
proxy_pass http://test_up/;
nginx启动报错:
nginx: [emerg] "proxy_pass" cannot have URI part in location given by regular expression, or inside named location, or inside "if" statement, or inside "limit_except" block in /usr/local/mywork/gateway/orange/conf/vhosts/test.balancer.com.conf:24
(3)
location ~ /test/(.*) {
set $new_url $1$is_args$args;
proxy_pass http://10.99.1.51/$new_url;
upstream接收到的请求:/science/getinfo?a=1&b=2
(4)
location ~ /test/(.*) {
set $new_url $1$is_args$args;
proxy_pass http://10.99.1.51/$new_url/;
upstream接收到的请求:/science/getinfo?a=1&b=2/
(5)
location ~ /test/(.*) {
set $new_url $1$is_args$args;
proxy_pass http://10.99.1.51/$request_uri;
upstream接收到的请求://test/science/getinfo?a=1&b=2
注意这里有两条/,$request_uri中本身包含了一个
(6)
location ~ /test/(.*) {
set $new_url $1$is_args$args;
proxy_pass http://10.99.1.51/$request_uri;
upstream接收到的请求:/test/science/getinfo?a=1&b=2
现在改成不带任何修饰符的前缀匹配:
浏览器:http://test.proxy.com/test/science/getinfo?a=1&b=2
(1)
location /test/ {
proxy_pass http://10.99.1.51;
upstream接收到的请求:/test/science/getinfo?a=1&b=2
(2)
location /test/ {
proxy_pass http://10.99.1.51/;
upstream接收到的请求:/science/getinfo?a=1&b=2
(3)
upstream test_up{
server 10.99.1.51;
}
location /test/ {
proxy_pass http://test_up;
upstream接收到的请求:/test/science/getinfo?a=1&b=2
(4)
upstream test_up{
server 10.99.1.51;
}
location /test/ {
proxy_pass http://test_up/;
upstream接收到的请求:/science/getinfo?a=1&b=2
(5)
upstream test_up{
server 10.99.1.51;
}
location /test {
proxy_pass http://test_up/;
upstream接收到的请求://science/getinfo?a=1&b=2
(6)
upstream test_up{
server 10.99.1.51;
}
location /test {
proxy_pass http://test_up;
upstream接收到的请求:/test/science/getinfo?a=1&b=2
(7) 浏览器访问:http://test.proxy.com/zhangbao/test/science/getinfo?a=1&b=2
结果是这些location都匹配不中,因为前缀都匹配不上
(8) 浏览器访问:http://test.proxy.com/zhangbao/test/science/getinfo?a=1&b=2
upstream test_up{
server 10.99.1.51;
}
location ~ /test {
proxy_pass http://test_up;
upstream接收到的请求:/zhangbao/test/science/getinfo?a=1&b=2
这里就不是前缀匹配了,只要uri里有/test字段就可以匹配中
现在将后端upstream name 写成变量的形式:
浏览器:http://test.proxy.com/test/science/getinfo?a=1&b=2
配置如下:
location /test/ {
set $ups zhouzhongtao2;
proxy_pass http://$ups;
或者:
location ~ /test/ {
set $ups zhouzhongtao2;
proxy_pass http://$ups;
upstream接收到的请求: /test/science/getinfo?a=1&b=2
location /test/ {
set $ups zhouzhongtao2;
proxy_pass http://$ups/;
location ~ /test/ {
set $ups zhouzhongtao2;
proxy_pass http://$ups/;
upstream接收到的请求:/
总结:
对于 ~ 匹配:
只要语法不错误,而且匹配中了,直接往后端扔给全部的uri
对于不带修饰符的前缀匹配:
如果写成proxy_pass http://upstream_name
加根:转发给后端时掐掉匹配中的部分
不加根:转发给后端的时候带上匹配中的部分。
对于将upstream写成变量形式的,不管是~匹配黑市不带修饰符的前缀匹配
不加根:全量uri转发到后端
加根: 访问的是根,即uri = /
2 ngx_http_access_module
- 生效阶段: NGX_HTTP_ACCESS_PHASE
- 配置语法
1 allow/deny
Syntax: allow address | CIDR | unix: | all;
Default: —
Context: http, server, location, limit_except
其中address:某个ip
CIDR:某个ip段
unix:基于socket的限制
all: 以上所有的
在location、server、http不同地方配置访问控制,生效的范围不一样
3 auth basic authenication
- 加密协议: RFC2617: HTTP BASIC Authentication
- 生效阶段 access阶段
- 执行流程:
1 用户请求 ---> Nginx
2 Nginx返回401 Unauthorized,并在header头中加上WWW-Authenication:Basic
3 改错误浏览器不会显示,而是弹出输入框,输入用户名和密码。
4 浏览器将用户密码以明文的方式发送给Nginx,如果是https,则会加密。
- 相关指令
auth_basic string|off :定义第二步中的header头
auth_basic_user_file file; 定义存储用户名和密码的文件
生成改file的方法:
1) 安装Apache的http-tools
2) htpasswd -c file -b user pass
4 ngx_http_upstream_module
- 作用:定义服务器组
调用服务器组的方法:proxy_pass fastcgi_pass uwsgi_pass
- nginx支持的调度算法(六种):
轮询(默认)
ip_hash
url_hash
hash:包括普通hash和c hash
least_conn
fair:智能选择,选择响应耗时短的自动分配
- 指令集:
每个指令对应一个模块处理
Directives
upstream
server
zone
state
hash
ip_hash
keepalive
ntlm
least_conn :调度方法,指明最少连接
least_time
queue
sticky
sticky_cookie_insert //和sticky指令二选一使用
指令1: proxy_pass
注意:后面要指定协议(http://不能掉)
配置范例:
upstream upservers {
server 10.99.2.15 weight=5;
server 10.99.2.122 weight=2;
server admin.xesv5.com weight=2;
server backend2.example.com:8080;
server unix:/tmp/backend3;
server backup1.example.com:8080 down;
server backup2.example.com:8080 backup;
}
server {
location / {
proxy_pass http://upservers; //加上http:
}
}
配置upstream遇到的坑:
场景:做分流测试,配置从10.99.2.15上转发流量到10.99.1.49
10.99.2.15配置如下:
upstream zxn {
server 10.99.1.49:80;
}
server{
listen 80;
server_name test.divide.com;
root /usr/local/src/klq;
location ~ /test/ {
proxy_set_header Host $host;
proxy_pass http://zxn;
}
location ~ \.php$ {
proxy_set_header Host $host;
proxy_pass http://zxn;
}
}
10.99.1.49配置如下:
server{
listen 80;
server_name test.divide.com;
access_log logs/test.divide.com.log main;
error_log logs/test.divide.com.error.log error;
location /test1.html {
root /usr/local/src/klq/;
}
location ~ \.php$ {
root /usr/local/src/zhangbao;
fastcgi_pass 127.0.0.1:9000;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
}
浏览器访问:test.divide.com/test/testdivide.php
echo ($__SERVER);
array(35) {
["HTTP_X_FORWARDED_FOR"]=>string(13) "123.125.71.45"
["HTTP_HOST"]=>string(15) "test.divide.com"
["SERVER_NAME"]=>string(15) "test.divide.com"
["SERVER_ADDR"]=>string(10) "10.99.1.49"
["REMOTE_ADDR"]=>string(10) "10.99.2.15"
["DOCUMENT_ROOT"]=>string(23) "/usr/local/src/zhangbao"
["DOCUMENT_URI"]=>string(20) "/test/testdivide.php"
["REQUEST_URI"]=>string(20) "/test/testdivide.php"
["SCRIPT_NAME"]=>string(20) "/test/testdivide.php"
["SCRIPT_FILENAME"]=>string(43) "/usr/local/src/zhangbao/test/testdivide.php"
["PHP_SELF"]=>string(20) "/test/testdivide.php"
}
结论: 1 在代理的nginx服务器中指定proxy_pass时,需要proxy_set_header $Host host;否则就算请求打到了后端upstream server, 也匹配不中对应的server
2 nginx在转发的时候,自动加上了 HTTP_X_FORWARDED_FOR字段,用于表示客户端ip
3 通过REMOTE_ADDR拿到的只是前一级代理的ip,并不能拿到真实的ip地址
指令2 proxy_next_upstream
1 配置该指令后,网关在转发的时候如果发现后端A机器返回错误,则重新内部发起一次请求,将请求打到B机器,因此看到的日志是: 网关1条,后端2条,浏览器一条,对于用户来说是无感知的。
但是网关的1条中,upstream_status会显示: upstream_status:500,200
指令3 hash和ip_hash
upstream iphashtest {
ip_hash;
#hash user_$arg_username [consistent];
server 127.0.0.1:8011 weight=2 max_conns=2 max_fails=2 fail_timeout=5;
server 127.0.0.1:8012 weight=1;
}
其中配置了ip_hash或者是 hash,则后面的weight指令失效.
说明:
ip_hash:
ip_hash的弊端就是在SNAT模式的大量Client,这些client都是统一个ip地址,最终都会被分配到同一个server。
sticky:
解决了ip_hash的弊端,实现一种基于cookie、route或者learn的session绑定,比基于ip的session更加精细。(具体如何配置参看官方文档)
keepalive: 指定与后端服务器使用持久连接模式,并持久多长时间。
通常,当upstream server为非http服务器时,例如memcache缓存服务器,可以开启该功能。让指令工作一段时间还保持连接的状态。但当后面是httpd server时,并不建议开启,会影响并发性能。
health_check:指明对某个upstream进行健康检查,定期对上游服务器发送检测http请求。在使用healt_check时,建议关闭该location的log功能,避免不必要的日志。
interval = time 指明发送探测间隔
failes = number 指明失败数
pass = number 指明通过数
uri = uri 指明请求的资源,默认为主页面==>'/'
match = name 指明服务器返回的状态信息,默认为2XX或3XX,也可以自定义match
eg:
http {
server {
...
location / {
proxy_pass http://backend;
health_check match=welcome;
}
}
match welcome {
status 200;
header Content-Type = text/html;
body ~ "Welcome to nginx!";
}
}
建议:关闭访问日志。 ngxin会阶段性的向upstream server发送访问探测,这些访问日志没有必要。
5 ngx_http_headers_module模块
基本语法:
add_header
add_trailer
expires
指令1 add_header
自定义返回给用户的response
Syntax: add_header name value [always];
Default: —
Context: http, server, location, if in location
配置范例:
eg1:
server {
listen 80;
server_name localhost;
add_header X-via $server_addr; 在response中显示处理该请求的服务器ip
add_header X-Cache $upstream_cache_status;//显示是否缓存命中了,MIIS或者HIT
location / {
proxy_pass http://upservers; //加上http:
}
}
eg2:
add_header Cache-Control private;
add_header X-First 1;
注意: 和proxy_set_header的区别,proxy_set_header是ngxin做反向代理转发请求的时候设置请求头的,而add_header是设置响应头的。
4 ngx_http_fastcgi_module
使用的是fast-cgi协议,用作处理/.php动态文件
proxy_pass:上游服务器是httpd,使用的协议是http协议
fascgi_pass:上游服务器不是httpd,使用的协议是fastcgi协议
指令集:
Directives
fastcgi_bind
fastcgi_buffer_size
fastcgi_buffering
fastcgi_buffers
fastcgi_busy_buffers_size
fastcgi_cache
fastcgi_cache_background_update
fastcgi_cache_bypass
fastcgi_cache_key
fastcgi_cache_lock
fastcgi_cache_lock_age
fastcgi_cache_lock_timeout
fastcgi_cache_max_range_offset
fastcgi_cache_methods
fastcgi_cache_min_uses
fastcgi_cache_path
fastcgi_cache_purge
fastcgi_cache_revalidate
fastcgi_cache_use_stale
fastcgi_cache_valid
fastcgi_catch_stderr
fastcgi_connect_timeout
fastcgi_force_ranges
fastcgi_hide_header
fastcgi_ignore_client_abort
fastcgi_ignore_headers
fastcgi_index :指定主页面
fastcgi_intercept_errors
fastcgi_keep_conn
fastcgi_limit_rate
fastcgi_max_temp_file_size
fastcgi_next_upstream
fastcgi_next_upstream_timeout
fastcgi_next_upstream_tries
fastcgi_no_cache
fastcgi_param
fastcgi_pass
fastcgi_pass_header
fastcgi_pass_request_body
fastcgi_pass_request_headers
fastcgi_read_timeout
fastcgi_request_buffering
fastcgi_send_lowat
fastcgi_send_timeout
fastcgi_split_path_info
fastcgi_store :缓存到磁盘上
fastcgi_store_access
fastcgi_temp_file_write_size
fastcgi_temp_path
使用范例
http
{
...
fastcgi_cache_path /data/nginx/cache keys_zone=zhangbao_cache_zone:10m;
map $request_method $purge_method {
PURGE 1;
default 0;
}
server {
...
location ~ \.php$ {
fastcgi_pass backend;
fastcgi_cache zhangbao_cache_zone;
fastcgi_cache mycache;
fastcgi_cache 200 1d;
fastcgi_cache 302 1h;
fastcgi_cache any 10m;
fastcgi_cache_use_stale error timeout http_500 http_502 http_503 http_504;
fastcgi_cache_key $uri;
fastcgi_cache_purge $purge_method;
}
}
}
6 ngx_http_rewrite_module模块
指令
break
if
return
rewrite
rewrite_log
set
用途:域名规划,向前兼容,可以将老的url全部重定向到新的url。避免了用户流量的损失,同时降低了修改的成本。
语法:rewrite regex replacement flag
结束位:跳转完需要写上结束位
last -当前匹配结束之后,终止匹配,服务端会建立一个新的请求,新请求的url则是rewrite后的,那么将重新去找能匹配的location,注意虽然是建立了一个新的请求,但是新请求并不是浏览器发出的,而是nginx内部建立的,查看日志发现nginx只收到了一次请求。
break -当前匹配结束之后即终止匹配,不会建立新的请求,也不会再去重新匹配location,而是根据rewrite后的地址去寻找对应的资源返回给客户端。
redirect -返回临时重定向的 HTTP 状态 302,浏览器会发送两次请求给nginx,url分别是rewrite前和rewrite后的。
permanent -返回永久重定向的 HTTP 状态 301 ,浏览器会记住重定向之后的url,下次在访问老url时,自动跳转到新的地址去,不再发送请求给nginx,因此就算nginx挂了都可以访问(只要能正常解析)。
eg1:rewrite ^/images/(.*\.jpg)$ /imgs/$1
解释:^前缀匹配,&后缀匹配,&1匹配前面$括号中的内容,\转义符,将所有images/XXX.jpg的全部定向到/imgs/XXX.jpg下.
eg2: rewrite ^/shop/(.*\.html)$ /tuangou/$1 break;
eg3: rewrite ^/shop/(.*\.php)$ http://www.baidu.com/$1 redirect
典型示例:
1 location{
if ($http_user_agent ~ MSIE) {
rewrite ^.*$ /ie.html;
rewrire ^(.*)$ /msie/$1;
break; #(不break会循环重定向)
}
原始的url为:test.com/2..php匹配到了'/',重写之后,
相当于把url重写成了 test.com/ie.html,去访问了ie.html 与之前的2.php没有任何关系了
}
2 if (!-e $document_root$fastcgi_script_name) {
rewrite ^.*$ /404.html break;
}
3 糟糕的配置
rewrite ^/(.*)$ http://example.com/$1 permanent;
好一点的配置
rewrite ^ http://example.com/$request_uri
更好的配置
return 301 http://example.com/$request_uri
反复对比下这几个配置。 第一个 rewrite 捕获不包含第一个斜杠的完整 URI。 使用内置的变
量 $request_uri,我们可以有效的完全避免任何捕获和匹配。
4 location ~ ^/break {
rewrite ^/break /test/ break;
}
location ~ ^/last {
rewrite ^/last /test/ break;
}
location /test/ {
default_type application/json;
return 200 '{"status:success"}';
}
5 经典实例分析:
(1)
server {
server_name rewrite.test.com;
rewrite_log on;
root html/;
location /first {
rewrite /first(.*) /second$1 last;
return 200 "this is first!";
}
location /second {
rewrite /second(.*) /third$1 break;
return 200 "this is second!";
}
location /third {
return 200 "this is third!";
}
}
访问: curl rewrite.test.com/first/1.txt -x 127.0.0.1:80
==> 404
curl rewrite.test.com/second/1.txt -x 127.0.0.1:80
==> 404
日志:2019/01/23 18:59:28 [error] 19871#0: *30 open() "/usr/local/openresty/nginx/html/third/1.txt" failed (2: No such file or directory), client: 127.0.0.1, server: rewrite.test.com, request: "GET http://rewrite.test.com/first/1.txt HTTP/1.1", host: "rewrite.test.com"
分析: /first 首先会rewrite到 /second , /second rewrite到 /third,但是由于break的作用,rewrite模块停止工作,所有的该模块的指令都失效,则nginx会找/third对应的资源/third/1.txt,没有找到则报404错误
(2) 改为如下:
server {
server_name rewrite.test.com;
rewrite_log on;
root html/;
location /first {
rewrite /first(.*) /second$1 last;
return 200 "this is first!";
}
location /second {
rewrite /second(.*) /third$1 break;
echo "2222";
return 200 "this is second!";
}
location /third {
echo "3333";
return 200 "this is third!";
}
}
访问: curl rewrite.test.com/first/1.txt -x 127.0.0.1:80
==> 2222
curl rewrite.test.com/second/1.txt -x 127.0.0.1:80
==> 2222
分析:echo指令不是rewrite模块的,可以得到执行。
(3) 继续改:
upstream zhangbao{
server 10.99.2.15:80;
}
server {
server_name rewrite.test.com;
rewrite_log on;
root html/;
location /first {
rewrite /first(.*) /second$1 last;
return 200 "this is first!";
}
location /second {
rewrite /second(.*) /third$1 break;
proxy_pass http://zhangbao;
proxy_set_header Host rewrite.test2.com;
return 200 "this is second!";
}
location /third {
echo "3333";
return 200 "this is third!";
}
}
server {
server_name rewrite.test2.com;
location / {
return 200 "this is rewrite2";
}
}
访问: curl rewrite.test.com/first/1.txt -x 127.0.0.1:80
==> this is rewrite2
curl rewrite.test.com/second/1.txt -x 127.0.0.1:80
==> this is rewrite2
(4)继续改:
upstream zhangbao{
server 10.99.2.15:80;
}
server {
server_name rewrite.test.com;
rewrite_log on;
root html/;
location /first {
rewrite /first(.*) /second$1 last;
return 200 "this is first!";
}
location /second {
rewrite /second(.*) /third$1 break;
proxy_pass http://zhangbao;
proxy_set_header Host rewrite.test2.com;
echo "2222";
return 200 "this is second!";
}
location /third {
echo "3333";
return 200 "this is third!";
}
}
server {
server_name rewrite.test2.com;
location / {
return 200 "this is rewrite2";
}
}
此时的结果为:2222
可见echo模块在upstream模块之前,先echo执行了,upstream模块没有机会执行,自然也就不会proxy_pass了
参考连接:https://www.cnblogs.com/tongxiaoda/p/7451998.html
补充说明:
1 if 之后有空格
2 不要掉了break,不然会一直重定向。如果是IE浏览器访问,重定向到/ie.html, 则url变成xxx.com/ie.html,继续匹配location/,又进入第二个if判断,又被重定到/ie.html
3 当rewrite的正则表达时候中有“{}”时,需要将正则表达式用“”包起来,否则报错。
Nginx使用源于perl兼容正则表达式(PCRE)库,基本语法如下:
- ^:必须以 ^ 后的实体开头
- $:必须以$前的实体结尾
- .:匹配任意字符
- []:匹配指定字符集内的任意字符,[C],[A-Z]
- {n}:重复n次
- {n,}:重复n次或更多次
- [^]:匹配不包括在指定字符集内的任意字符
- |:匹配|之前或之后的实体
- ():分组,组成一组用于匹配的实体,通常与|,$等配合使用
7 ngx_stream_split_clients_module模块
用途:创建适用于AB测试的变量
http://www.ttlsa.com/nginx/nginx-ngx_http_split_clients_module/
8 ngx_http_gzip_module模块
1 配置参数:
gzip配置的常用参数
gzip on|off; #是否开启gzip
gzip_buffers 32 4K| 16 8K #缓冲(压缩在内存中缓冲几块? 每块多大?)
gzip_comp_level [1-9] #推荐6 压缩级别(级别越高,压的越小,越浪费CPU计算资源)
gzip_disable #正则匹配UA 什么样的Uri不进行gzip
gzip_min_length 200 # 开始压缩的最小长度(再小就不要压缩了,意义不在)
gzip_http_version 1.0|1.1 # 开始压缩的http协议版本(可以不设置,目前几乎全是1.1协议)
gzip_proxied # 设置请求者代理服务器,该如何缓存内容
gzip_types text/plain application/xml # 对哪些类型的文件用压缩 如txt,xml,html ,css
gzip_vary on|off # 是否传输gzip压缩标志
9 ngx_http_memcached_module
server {
location / {
set $memcached_key "$uri?$args";
memcached_pass host:11211;
error_page 404 502 504 = @fallback;
}
location @fallback {
proxy_pass http://backend;
}
}
eg:
server{
listen 80;
server_name memcached.com;
access_log logs/test.com.access.log main;
root html/test;
location / {
set $memcached_key $uri;
memcached_pass 127.0.0.1:11211;
error_page 404 callback.php;
}
...
}
这里写/callback.php 和写callback.php都行
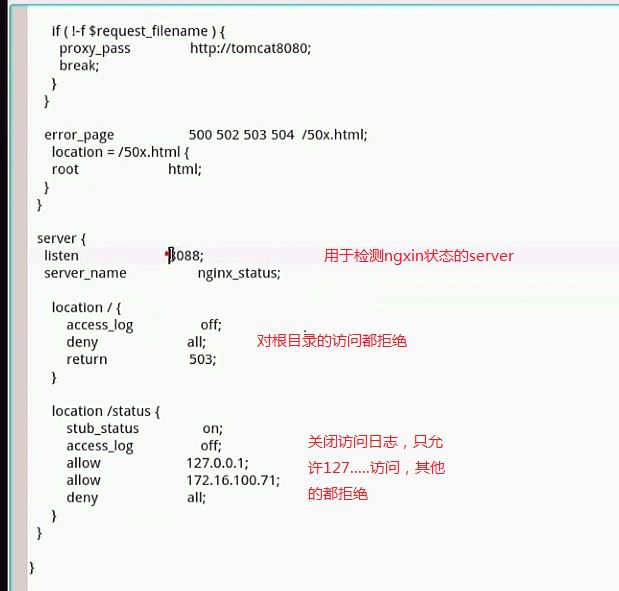
10 ngx_http_stub_status_module
location /basic_status {
stub_status on;
access_log off;
}
浏览器结果显示:
Active connections: 2
server accepts handled requests
4 4 9
Reading: 0 Writing: 1 Waiting: 1
11 ngx_http_stub_status_module
location /basic_status {
stub_status on;
access_log off;
}
浏览器结果显示:
Active connections: 2
server accepts handled requests
4 4 9
Reading: 0 Writing: 1 Waiting: 1
12 ngx_http_secure_link_module
生成安全的下载地址给用户,用户只有拿到正确的密钥和过期时间才能下载相应的资源,对服务器的资源起到了很好的保护作用。
用法实例:
可以参考官网实例
server{
listen 80;
server_name test.securelink.com;
root /usr/local/mywork/test;
location ~ \.(jpg|png|gif)$ {
secure_link $arg_md5,$arg_expires;
secure_link_md5 "$secure_link_expires$uri secret";
if ($secure_link = "") {
return 403;
}
if ($secure_link = "0") {
return 410;
}
}
}
命令行得到密钥:
[root@zhangbao1 vhosts]# echo -n '2147483647/img/kb.jpg192.168.0.101 secret' | openssl md5 -binary | openssl base64 | tr +/ -_ | tr -d =
MwseFtfFdnGK0R2KfBeiyA
拼接密钥和过期时间的链接地址:
http://test.securelink.com/img/kb.jpg?md5=MwseFtfFdnGK0R2KfBeiyA&expires=2147483647
则在浏览器上输入这个网址才能下载资源
也可以用脚本实现:
生产密钥和过期时间脚本:
#!/bin/sh
servername="test.securelink.com"
download_file="/img/kb.jpg"
time_num=$(date -d "2018-10-18 00:00:00" +%s)
secure_num="zhangbao"
res=$(echo -n '${time_num}${download_file} ${secure_num}' | openssl md5 -binary | openssl base64 | tr +/ -_ | tr -d =)
echo "http://${servername}${download_file}?md5=${res}&expires=${time_num}"
执行脚本之后输出:
http://test.securelink.com/img/kb.jpg?md5=oNz7HBPflrCWeEASTeZhIw&expires=1539792000
13 ngx_geoip_module模块
模块用于定位ip地址
参考连接:https://www.centos.bz/2018/04/nginx-使用-geoip-模块区分用户地区/
使用方法:
1 linux上安装Geoip库:
附件地址:链接: https://pan.baidu.com/s/1dFl1zZN 密码: x37s
./configure
make
make install
2 重新编译nginx
我装的是openresty,直接在第一次安装时的编译参数后面加上geoip_module
./configure --prefix=/usr/local/openresty --add-module=/usr/local/src/openresty-1.13.6.1/bundle/ngx_cache_purge-2.3 --add-module=/usr/local/src/openresty-1.13.6.1/bundle/nginx_upstream_check_module-0.3.0 --add-module=/usr/local/src/openresty-1.13.6.1/bundle/ngx_http_consistent_hash-master --with-http_secure_link_module --with-http_geoip_module
3 配置
geoip_country /usr/local/share/GeoIP/GeoIP.dat;
geoip_city /usr/local/share/GeoIP/GeoLiteCity.dat;
4 使用该模块定义的变量
$geoip_country_code; – 两个字母的国家代码,如:”RU”, “US”。
$geoip_country_code3; – 三个字母的国家代码,如:”RUS”, “USA”。
$geoip_country_name; – 国家的完整名称,如:”Russian Federation”, “United States”。
$geoip_region – 地区的名称(类似于省,地区,州,行政区,联邦土地等),如:”30”。 30代码就是广州的意思
$geoip_city – 城市名称,如”Guangzhou”, “ShangHai”(如果可用)。
$geoip_postal_code – 邮政编码。
$geoip_city_continent_code。
$geoip_latitude – 所在维度。
$geoip_longitude – 所在经度。
14 ngx_map_module
指令:
map
map_hash_bucket_size
map_hash_max_size
15 ngx_http_geo_module
ngx_http_geo_module模块可以用来创建变量,其值依赖于客户端IP地址。
参考连接:http://www.ttlsa.com/nginx/using-nginx-geo-method/
16 ngx_ssl_module模块
使用方法:
一、生成CA证书
mkdir ssl_key
cd ssl_key/
openssl genrsa -idea -out zhangbao.key 1024 生成key
openssl req -new -key zhangbao.key -out zhangbao.csr 生成csr文件
openssl x509 -req -days 3650 -in zhangbao.csr -signkey zhangbao.key -out zhangbao.crt 生成crt证书文件
openssl x509 -noout -text -in /usr/local/mywork/ssl_key/zhangbao.crt 查看生成的证书文件信息
二 、配置nginx
filter模块
1 sub_filter模块
用途:将返回给用户的用户的body中的内容替换掉
location / {
sub_filter 'Nginx.ORg' '$host/nginx'; #不区分大小写的替换
sub_fillter 'nginx.CoM' '$host/nginx';
sub_filter_once on; # 只替换一次
sub_filter_last_modified on; #是否返回last_modified的header头
sub_filter_last_modified off;
}
2 addition 模块
用途: 在返回当前请求之前或者之后,通过发送子请求的方式,追加额外的响应内容
http://www.ttlsa.com/linux/nginx-modules-ngx_http_addition_module/
location / {
add_before_body /before_action
add_after_body /after_action
addition_type *;
}
location /before_action {
return 'this is a before txt';
}
location /after_action {
return 'this is a after txt';
}
访问 test.com/a.txt
结果:
this is a before txt
a
this is a after txt
第三方模块
1 与upstream和health_check相关
- nginx_upsync_module + nginx_upstream_check_module(用的最多)
微博的开源项目
参考:
https://blog.csdn.net/yueguanghaidao/article/details/52801043
https://mp.weixin.qq.com/s?__biz=MzAwMDU1MTE1OQ==&mid=404151075&idx=1&sn=5f3b8c007981a2d048766f808f8c8c98&scene=2&srcid=0223XScbJrOv7noogVX6T60Q&from=timeline&isappinstalled=0#wechat_redirect
https://github.com/weibocom/nginx-upsync-module
另外每个 work 进程各自拉取、更新各自的路由表,采用这种方式的原因:一是基于 Nginx 的进程模型,彼此间数据独立、互不干扰;二是若采用共享内存,需要提前预分配,灵活性可能受限制,而且还需要读写锁,对性能可能存在潜在的影响;三是若采用共享内存,进程间协调去拉取配置,会增加它的复杂性,拉取的稳定性也会受到影响。基于这些原因,便采用了各自拉取的方式。
- lua-resty-upstream-healthcheck
参考:https://blog.csdn.net/liutong123987/article/details/79239214
典型配置
http {
#---------------------
# test health check
#---------------------
lua_package_path "/usr/local/openresty/lualib/resty/?.lua;/usr/local/openresty/lualib/resty/upstream/?.lua;;";
upstream tomcat {
server 127.0.0.1:48080;
server 127.0.0.1:58080;
}
lua_shared_dict healthcheck 1m;
lua_socket_log_errors off;
init_worker_by_lua_block {
local hc = require "resty.upstream.healthcheck"
local ok, err = hc.spawn_checker {
shm = "healthcheck",
upstream = "tomcat",
type = "http",
http_req = "GET /health.txt HTTP/1.0\r\nHost: tomcat\r\n\r\n",
interval = 2000,
timeout = 5000,
fall = 3,
rise = 2,
valid_statuses = {200, 302},
concurrency = 1,
}
if not ok then
ngx.log(ngx.ERR, "=======> failed to spawn health checker: ", err)
return
end
}
server {
listen 38080;
server_name localhost;
access_log logs/access-38080.log main;
error_log logs/error-38080.log debug;
location / {
proxy_pass http://tomcat;
}
location /server/status {
access_log off;
default_type text/plain;
content_by_lua_block {
local hc = require "resty.upstream.healthcheck"
ngx.say("Nginx Worker PID: ", ngx.worker.pid())
ngx.print(hc.status_page())
}
}
}
}
总结:
nginx对后端real server做健康检查有三种方法:
方法1:ngx_http_proxy_module+ngx_http_upstream_module
nginx自带的模块
方法2:nginx_upstream_check_module模块
淘宝tengine自带的模块,nginx需要手动添加
方法3:lua-resty-upstream-healthcheck模块
方法4:ngx_http_healthcheck_module模块
早期的nginx提供的健康检查模块,目前已不用
2 ngx_set_misc
如果你想对 URI 参数值中的 %XX 这样的编码序列进行解码,可以使用第三方 ngx_set_misc 模块提供的 set_unescape_uri 配置指令:
配置示例:
location /test {
set_unescape_uri $name $arg_name;
set_unescape_uri $class $arg_class;
echo "name: $name";
echo "class: $class";
}
效果:
$ curl 'http://localhost:8080/test?name=hello%20world&class=9'
name: hello world
class: 9
3 realip模块
几点说明
1 CDN能够记录用户端的ip,它向后端转发的时候带上两个header头:X-Forwarded-For和X-Real-IP
2 nginx通过读取这两个头能够拿到真实ip,然后将真实ip用binary_remote_addr和remote_addr变量替换掉,其值为真实ip,这样做连接限制limit_conn才有意义,这也是为什么limit_req要出现在realip模块之后
编译: --with-http_realip_module
五 nginx安全与优化
5.1 nginx常见的错误码
400 (Bad Request)
405 (Not Allowed)
408 (Request Timeout) 读取请求头或者读取请求体超时
413 (Request Entity Too Large)
414 (Request URI Too Large)
494 (Request Headers Too Large)
499 (Client Closed Request)
500 (Internal Server Error)
501 (Not Implemented)
解释说明:
413 Request Entity Too Large
request body太大,可以修改client_max_body_size参数修改
414 nginx会将整个请求头都放在一个buffer里面,这个buffer的大小通过配置项client_header_buffer_size来设置,如果用户的请求头太大,这个buffer装不下,那nginx就会重新分配一个新的更大的buffer来装请求头,这个大buffer可以通过large_client_header_buffers来设置,这个large_buffer这一组buffer,比如配置4 8k,就是表示有四个8k大小的buffer可以用。注意,为了保存请求行或请求头的完整性,一个完整的请求行或请求头,需要放在一个连续的内存里面,所以,一个完整的请求行或请求头,只会保存在一个buffer里面。这样,如果请求行大于一个buffer的大小,就会返回414错误,如果一个请求头大小大于一个buffer大小,就会返回400错误。在了解了这些参数的值,以及nginx实际的做法之后,在应用场景,我们就需要根据实际的需求来调整这些参数,来优化我们的程序了。
502 bad gateway
参考:https://www.cnblogs.com/irockcode/p/8336313.html
可能出问题的地方:
nginx自身
后端服务器
挂了
php
mysql
504 Gateway Time-out
nginx进行转发到后端服务器,后端服务器响应时间太长(逻辑运算,取数据库等),超过了nginx的保持连接的keepalive等待时间。
5.2 nginx 并发数
参考:http://blog.51cto.com/liuqunying/1420556
参考: https://blog.csdn.net/sinat_36255444/article/details/53832516
nginx作为http服务器的时候:
max_clients = worker_processes * worker_connections
nginx作为反向代理服务器的时候:
max_clients = worker_processes * worker_connections/4
5.3 nginx安全措施
常见的恶意行为和攻击手段
1 爬虫
爬虫行为和恶意抓取、盗用
常用手段:
1 基础的防盗链功能:目的是不让恶意用户能轻易的爬去网站数据
2 secure_link_module对数据安全性提高加密验证和失效性,如核心的重要数据
3 access_module模块对后台、部分用户服务的数据提供IP防控
2 暴力破解密码
后台密码撞库: 通过猜测密码字典不断对后台系统登录性尝试,获取后台登录密码
方法一:提高后台密码的复杂度
方法二:access_module对IP的限制
方法三:nginx+lua的预警机制
3 利用文件上传漏洞
http://www.xesv5.com/upload/1.jpg/1.php
危险:nginx会把1.jpg当成是php文件进行处理。
location ^~ /upload {
root /opt/upload;
if($request_filename ~* (.*).\php){
return 403;
}
}
以php结尾的上传文件返回403;
4 sql注入
利用未过滤/未审核用户输入的攻击方法,让应用运行本应该运行的sql代码
例如:
用户名:' or 1=1#
密码:xxx(随便输入)
则后台的sql代码可能是:
select * from users where username = " or 1=1# and password='xxxxxx';
login success!
下载开源项目:https://github.com/loveshell/ngx_lua_waf 配置nginx+lua的防火墙
5 利用nginx配置漏洞:
参考连接:https://paper.seebug.org/335/
典型的引起漏洞的配置:
CRLF漏洞:
location / {
return 302 https://$host$uri;
}
目录穿越漏洞:
location /files {
alias /home/;
}
HTTP_Header漏洞:
server {
...
add_header Content-Security-Policy "default-src 'self'";
add_header X-Frame-Options DENY;
location = /test1 {
rewrite ^(.*)$ /xss.html break;
}
location = /test2 {
add_header X-Content-Type-Options nosniff;
rewrite ^(.*)$ /xss.html break;
}
}
检测漏洞工具:gixy
5.4 nginx调优
1 Linux参数优化
- ulimit -a 默认是1024,如果nginx运行在这个环境下,那么当流量大时就会出现(24: Too many open files) 错误。而nginx的处理能力远不止1024,因此这个参数必须调整
- 内核参数优化
内核参数的优化,主要是在Linux系统中针对Nginx应用而进行的系统内核参数优化。
下面给出一个优化实例以供参考。
net.ipv4.tcp_max_tw_buckets = 6000
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_syncookies = 1
net.core.somaxconn = 262144
net.core.netdev_max_backlog = 262144
net.ipv4.tcp_max_orphans = 262144
net.ipv4.tcp_max_syn_backlog = 262144
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_fin_timeout = 1
net.ipv4.tcp_keepalive_time = 30
将上面的内核参数值加入/etc/sysctl.conf文件中,然后执行如下命令使之生效:/sbin/stsctl -p
net.ipv4.tcp_max_tw_buckets选项用来设定timewait的数量,默认是180 000,这里设为6000。
net.ipv4.ip_local_port_range选项用来设定允许系统打开的端口范围。
net.ipv4.tcp_tw_recycle选项用于设置启用timewait快速回收。
net.ipv4.tcp_tw_reuse选项用于设置开启重用,允许将TIME-WAIT sockets重新用于新的TCP连接。
net.ipv4.tcp_syncookies选项用于设置开启SYN Cookies,当出现SYN等待队列溢出时,启用cookies进行处理。
net.core.somaxconn选项的默认值是128, 这个参数用于调节系统同时发起的tcp连接数,在高并发的请求中,默认的值可能会导致链接超时或者重传,因此,需要结合并发请求数来调节此值。
net.core.netdev_max_backlog选项表示当每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许发送到队列的数据包的最大数目。
net.ipv4.tcp_max_orphans选项用于设定系统中最多有多少个TCP套接字不被关联到任何一个用户文件句柄上。如果超过这个数字,孤立连接将立即被复位并打印出警告信息。这个限制只是为了防止简单的DoS攻击。不能过分依靠这个限制甚至人为减小这个值,更多的情况下应该增加这个值。
net.ipv4.tcp_max_syn_backlog选项用于记录那些尚未收到客户端确认信息的连接请求的最大值。对于有128MB内存的系统而言,此参数的默认值是1024,对小内存的系统则是128。
net.ipv4.tcp_synack_retries参数的值决定了内核放弃连接之前发送SYN+ACK包的数量。
net.ipv4.tcp_syn_retries选项表示在内核放弃建立连接之前发送SYN包的数量。
net.ipv4.tcp_fin_timeout选项决定了套接字保持在FIN-WAIT-2状态的时间。默认值是60秒。正确设置这个值非常重要,有时即使一个负载很小的Web服务器,也会出现大量的死套接字而产生内存溢出的风险。
net.ipv4.tcp_syn_retries选项表示在内核放弃建立连接之前发送SYN包的数量。
如果发送端要求关闭套接字,net.ipv4.tcp_fin_timeout选项决定了套接字保持在FIN-WAIT-2状态的时间。接收端可以出错并永远不关闭连接,甚至意外宕机。
net.ipv4.tcp_fin_timeout的默认值是60秒。需要注意的是,即使一个负载很小的Web服务器,也会出现因为大量的死套接字而产生内存溢出的风险。FIN-WAIT-2的危险性比FIN-WAIT-1要小,因为它最多只能消耗1.5KB的内存,但是其生存期长些。
net.ipv4.tcp_keepalive_time选项表示当keepalive启用的时候,TCP发送keepalive消息的频度。默认值是2(单位是小时)。
2 nginx配置优化
1 长连接keepalive
参考连接: https://blog.csdn.net/dream_flying_bj/article/details/54709549
六 nginx的内部机制
6.1 事务处理模型—异步模型epoll
apache使用的是select模型
了解I/O网络模型中的阻塞,非阻塞,多路IO,异步,事件驱动的区别
6.2 nginx模块和工作原理
nginx = 内核+模块
内核
完成的工作很简单,就是将通过查找配置文件将客户端的请映射到某个对应的location block上(即匹配url),每个location块配置不同的指令去启动不同的模块去完成相应的工作。
模块
按重要性分:
-
核心模块:HTTP模块,EVENT模块,MAIL模块
-
基础模块:HTTP Access模块,HTTP FastCGI模块,HTTP Proxy模块
-
第三方模块:HTTP Upstream, Request Hash, Notice,HTTP Access Key,缓存模块,其他用户自己开发的模块
按功能分:
-
Handler模块:此类模块直接处理请求,并进行输出内容和修改header信息等操作,handler模块一 般只能有一个。
-
Filter模块:此类模块主要对其他处理器模块输出的内容进行修改操作,最后由Nginx输出
-
Proxies模块:就是Nginx HTTP Upstream之类的模块,这些模块主要与后端的服务比如fastcgi等操作交互,实现服务代理和负载均衡的功能。
Nginx模块处理常规的一次HTTP请求的过程。
ngxin内部模块运行原理
处理web请求的过程
6.3 nginx reload流程
1 向master进程发送HUP信号 (相当于reload命令)
2 master进程校验配置文件语法是否正确 (因此不必每次-t检测一次)
3 master进程打开新的监听端口 (新的配置中可能涉及到新的端口)
4 master进程用新配置启动新的worker子进程
5 master进程向老worker子进程发送QUIT信号 (要求老的worker进程处理完当前请求就关闭,哪怕是配置了keepalive)
6 老woker进程关闭监听句柄,处理完当前连接后结束进程
nginx每次reload时会有很多worker进程,就是因为新建了worker,而老的worker还没有关闭
nginx的配置: worker shutdown timeout 可以设置超时时间,强制关闭老worker
6.4 nginx处理请求的11个请求
| 名称 | 生效的模块 |
|---|---|
| POST_READ | realip |
| SERVER_REWRITE | rewrite |
| FIND_CONFIG | |
| REWRITE | rewrite |
| POST_REWRITE | |
| PREACCESS | limit_conn , limit_req |
| ACCESS | auth_basic,access,auth_request |
| POST_ACCESS | |
| PRECONTENT | try_files |
| CONTENT | index,autoindex,concat |
| LOG | access_log |
几点说明
1 ngx_module_name[] 数组中出现的先后顺序决定了模块执行顺序,先出现的一般后执行。、
例如 limit_conn 在 limit_req前出现,但是实际请求流程中,先判断limit_req逻辑,后判断limit_conn,当limit_req返回时,有可能limit_conn都没有机会得到执行。
2 auto_index没有展示文件的目录结构,因为还配置了index,index提前生效,后面的auto_index没有机会执行
3 某个阶段中模块可能会跳跃执行,比如access阶段,access模块执行完毕可能直接跳到try_files,不会执行auth_basic和auth_request
七 nginx源码分析
笔记记录
1 《深入理解nginx》
日志相关:
ngx_log_error():1-p124
数据类型转换:
ngx_int_t = ngx_atoi(ngx_str_t.data, ngx_str_t.len) 将字符串转化为整形 1-P133
重要的数据结构
(一) 基础数据结构
K-V数据结构:
ngx_keyval_t{
ngx_str_t key;
ngx_str_t value;
}
(二) 高级数据结构
struct ngx_module_t {
/* 当前模块在这一类模块中的位置 */
ngx_uint_t ctx_index
/* 当前模块在所有模块中的位置 */
ngx_uint_t index
/* 模块的上下文结构体,如果是HTTP模块,这ctx指向ngx_http_module_t结构体*/
void *ctx
/* 模块支持的配置指令 */
ngx_command_t *commands
}
struct ngx_http_module_t {
preconfiguration
postconfiguration
create_main_conf
init_main_conf
create_srv_conf
create_loc_conf
merge_srv_conf
merge_loc_conf
}
struct ngx_command_t {
ngx_str_t name; //指令名称
ngx_uint_t type; // 指令能出现的位置
char *(*set)(ngx_conf_t *cf, ngx_command_t *cmd, void *conf) //调用set方法处理配置项的参数
}
struct ngx_http_conf_ctx_t {
void **main_conf;
void **srv_conf;
void **loc_conf;
}
struct ngx_cycle_s {
//保存存储所有模块的配置项的结构体指针
//之所以是4级指针,是因为conf_ctx首先是一个数组
//然后存储的元素是指针,该指针又指向另外一个指针数组
void ****conf_ctx;
//内存池
ngx_pool_t *pool;
/* 在还没有执行ngx_init_cycle之前(即没有解析配置项)
* 若此时需要输出日志,就暂时用log,它会直接将信息输出到屏幕
* 当解析了配置项之后,会根据nginx.conf配置文件中的配置构建出要求的日志文件并将log重新赋值
*/
ngx_log_t *log;
ngx_log_t new_log;
/* files保存所有ngx_connection_t的指针组成的数组 */
ngx_connection_t **files;
/* 可用的连接池 */
ngx_connection_t *free_connections;
/* 空闲连接的个数 */
ngx_uint_t free_connection_n;
/* 双向链表, 存储的元素类型是ngx_connection_t, 代表可重复使用的连接队列 */
ngx_queue_t reusable_connections_queue;
/* 动态数组, 存储类型为ngx_listening_t成员, 存储着监听的端口等信息
ngx_array_t listening;
/* 动态数组, 保存nginx所有需要操作的目录, 如果系统中不存在这个目录, 则需要创建
* 若创建不成功, nginx启动会失败(比如没有权限什么的,所以master进程最好属于root)
*/
ngx_array_t pathes;
/* 单链表, 存储类型为ngx_open_file_t结构体
* 它表示nginx已经打开的所有文件
* 由感兴趣的模块向其中添加文件路径名
* 然后在ngx_init_cycle函数中打开
*/
ngx_list_t open_files;
/* 单链表, 存储类型为ngx_shm_zone_t结构体
* 每个元素表示一块共享内存
*/
ngx_list_t shared_memory;
/* 所有连接对象的总数 */
ngx_uint_t connection_n;
/* files数组里元素的总数
ngx_uint_t files_n;
/* 指向所有连接对象 */
ngx_connection_t *connections;
/* 指向所有读事件 */
ngx_event_t *read_events;
/* 指向所有写事件 */
ngx_event_t *write_events;
/* 在调用ngx_init_cycle之前,需要一个ngx_cycle_t临时变量来存储一些变量
* 调用ngx_init_cycle会将该临时变量传入
* old_cycle就负责保存这个临时变量
ngx_cycle_t *old_cycle;
//配置文件相对安装目录的相对路径名
ngx_str_t conf_file;
//需要特殊处理的在命令行携带的参数
ngx_str_t conf_param;
//配置文件所在目录的路径
ngx_str_t conf_prefix;
//安装目录的路径
ngx_str_t prefix;
//文件锁名称
ngx_str_t lock_file;
//主机名(通过gethostname系统调用获取)
ngx_str_t hostname;
};
ngx_core_conf_t : core模块存储配置项的结构体
ngx_command_t
struct ngx_command_s {
ngx_str_t name;
ngx_uint_t type;
char *(*set)(ngx_conf_t *cf, ngx_command_t *cmd, void *conf);
ngx_uint_t conf;
ngx_uint_t offset;
void *post;
};
ngx_process_t:用来记录每个worker子进程的基本信息,Nginx使用一个全局数组保存所有产生的子进程,这就是近程池ngx_processes,这个数组是静态分配的,不能动态增长,Nginx只支持1024个子进程(也就是worker进程),这远大于目前主流计算机CPU核心数量,足够用了。
typedef struct {
//进程的id号
ngx_pid_t pid;
//通过waitpid系统调用获取到的进程状态
int status;
//通过socketpair系统调用产生的用于进程间通信的一对socket,用于相互通信。
ngx_socket_t channel[2];
//子进程的工作循环
ngx_spawn_proc_pt proc;
//proc的第二个参数,可能需要传入一些数据
void *data;
//进程名称
char *name;
//一些标识位
//为1时代表需要重新生成子进程
unsigned respawn : 1;
//为1代表需要生成子进程
unsigned just_spawn : 1;
//为1代表需要进行父、子进程分离
unsigned detached : 1;
//为1代表进程正在退出
unsigned exiting : 1;
//为1代表进程已经退出了
unsigned exited : 1;
} ngx_process_t;
ngx_connection_t:nginx的连接池
ngx_http_request_t:nginx的每个http请求
ngx_buf_t *header_in; //未经解析的header头
ngx_http_headers_in_t header_in; //解析过的header头
ngx_http_header_in_t
typedef struct {
ngx_list_t headers; //用链表存储每一个header
}
重要的底层函数:
ngx_http_conf_get_module_loc_conf(cf, ngx_http_core_module);
ngx_http_discard_request_body®;
丢弃请求中的包体
字符串相关
1 字符串比较:ngx_strcmp()与ngx_strcasecmp() 后者不区分大小写
2 比较字符串前n个字符: ngx_strncmp()与ngx_strncasecmp()
示例见<深入理解nginx> P97
输入输出相关:
1 日志
2 标准输出
(三) nginx处理http request的流程
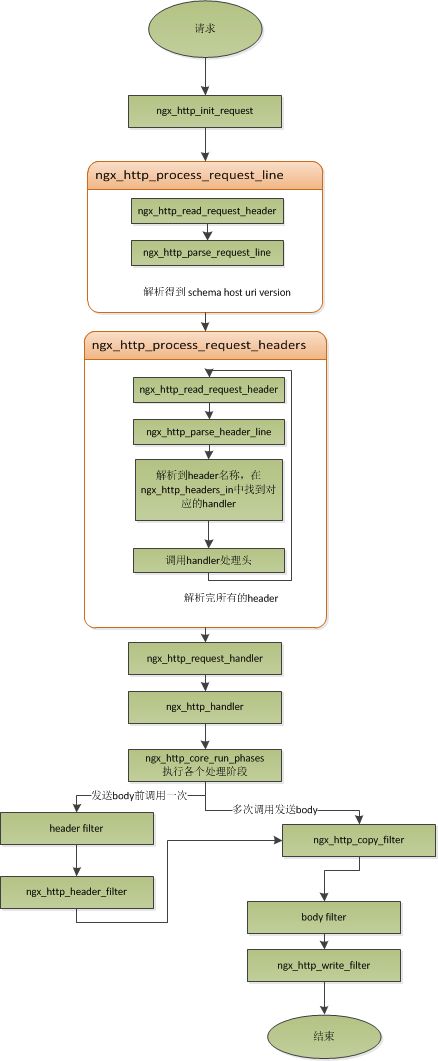
三个重要的handler函数:
行handler: ngx_http_process_request_line
ngx_http_read_request_header: 读取行
ngx_http_parse_request_line: 解析行
头handler:ngx_http_process_request_headers
ngx_http_read_request_header: 读取头
ngx_http_parse_header_line:解析头
先不读body,读取到两个换行符时,开始处理请求:
处理请求handler: ngx_http_process_request
ngx_http_handler
读事件:read_event_handler
写事件:write_event_handler = ngx_http_core_run_phases
八 nginx排错记录
一 error.log日志
1 http响应头不标准
错误现象:用户请求aisouti.xueersi.com,请求打到了10.10.88.54网关机器上,发现响应很慢。
access_log: status是009
{ "@timestamp": "2018-09-03T17:48:44+08:00", "hostname": "gw-88-54", "server_name": "aisouti.xueersi.com", "http_x_forwarded_for": "-", "xes-app": "-", "remote_addr": "10.10.81.140", "remote_user": "-", "body_bytes_sent": 120, "request_time": 0.487, "upstream_response_time": "0.487", "status": 009, "upstream_status": "200", "connection_requests": 1, "request": "POST / HTTP/1.1", "request_method": "POST", "request_body": "--------------------------68f7da265de91e51\x0D\x0AContent-Disposition: form-data; name=\x22param\x22\x0D\x0A\x0D\x0A\x0D\x0A--PP**ASR**LIB_a\x0D\x0A\x22sid\x22:\x221\x22,\x22idx\x22:\x222\x22,\x22imageLength\x22:\x220\x22,\x22URL\x22:\x22http://hwt.xesimg.com/question_orc_search/1535968123.jpg\x22\x0D\x0A--PP**ASR**LIB_b\x0D\x0A\x0D\x0A--PP**ASR**LIB_c\x0D\x0A\x0D\x0A--------------------------68f7da265de91e51--\x0D\x0A", "http_referrer": "-", "http_cookie": "-", "http_x_request_id": "-", "http_x_app_id": "2001146", "http_user_agent": "-"}
error_log:
018/09/04 16:56:27 [error] 17631#0: *4984188907 upstream sent no valid HTTP/1.0 header while reading response header from upstream, client: 10.10.9.191, server: aisouti.xueersi.com, request: "GET / HTTP/1.1", upstream: "http://10.10.18.21:18128/", host: "aisouti.xueersi.com"
原因:后端的服务没有返回有效的http头部信息
2 no live upstreams while connecting to upstream
灰度环境的laoshi.xueeri.com的upstream配置如下:
upstream laoshi.xueersi.com {
server 10.10.6.44:80;
}
错误信息:
2018/12/17 20:38:40 [error] 1313#0: *59938066 no live upstreams while connecting to upstream, client: 61.148.212.141, server: laoshi.xueersi.com, request: "POST /Users/testConfig HTTP/1.1", upstream: "http://laoshi.xueersi.com/Users/testConfig", host: "laoshi.xueersi.com"
排查过程:
将server 10.10.6.44 改为:
server 10.10.6.44 max_fails=5;
发现报错少了不少,但是还是有,然后就改成了10,最后还是有,最终改成这样:
server 10.10.6.44 max_failes=0; 表示让nginx对后端节点不做健康检查。
参考连接: http://blog.51cto.com/xiaosu/1689992
3 upstream prematurely closed connection while reading response header from upstream
场景:A--->B--->C,A:client,B 网关,C: server
其中B的配置:
http{
keepalive_timeout 20 5;
upstream {
server ....;
keepalived 100;
}
server {
location {
proxy_pass ...;
proxy_http_version 1.1;
}
}
}
C的配置:
http{
keepalive_timeout 60;
}
分析:
1 网关B即和下游A建立连接,也和上游C建立连接,而keepalive_timeout参数只是对下游client产生作用,当超过60sA没有给B发送数据时,B会主动断开连接。同理B有60s没有发送数据给C时,C会主动断开连接。上游服务断开连接时,会发送FIN包给下游,经过4次挥手断开连接。
2 对于B,当60s超时时间到时,C发送FIN包给B,B正好此时要发送新的请求给C,而正好选中了这条即将关闭的连接通道,则会出问题,上游已经断开了连接,而下游还在发送请求,则会出现upstream prematurely closed connection while reading response header from upstream错误。
解决方案:
1 在后端服务压力不大的情况下,可以保持长连接不释放,即配置so_keepalive参数,例:so_keepalive=30s参数,这个值一定要小于上游的keepalive_timeout参数,即B每隔30s发一次探测心跳给C,确保C还或者,而C永远不会触发60s收不到数据的条件,则B和C的连接一直存在。
so_keepalive on: 开启TCP探活,并且使用系统内核参数
so_keepalive 30s;开启TCP探活,用自定义时间30s,用系统内核的间隔时间参数
系统参数查看:
[root@bj-sjhl-gw-api-online-33-139 ops]# cat /proc/sys/net/ipv4/tcp_keepalive_time
300
[root@bj-sjhl-gw-api-online-33-139 ops]# cat /proc/sys/net/ipv4/tcp_keepalive_intvl
75
[root@bj-sjhl-gw-api-online-33-139 ops]# cat /proc/sys/net/ipv4/tcp_keepalive_probes
9
含义:
300s没有发送数据会主动发送一次探测,
每隔75s探测一次
探测9次还是失败则认为连接不可用,断开
显然,系统内核参数是不满足的要求的,需要nginx配置so_keepalive参数
2 升级B的nginx到1.15+,配置upstream XXX {keepalive_timeout 30s}
问题的根本原因在于:断开连接的操作是有C主动发起的,而不是B,C在断开的时候B并不能第一时间感知到,因此需要让B主动断开连接,配置如下:
upstream XXX{
server ...;
keepalive_timeout 30s;
}
这个值只要小于C在http段配置的keepalive_timeout 60s即可以,则30s内没有数据来往时,B这边会主动断开连接,然后B如果发起新的请求,就会新建连接。
但是该指令只支持nginx1.15+
3 备选方案:
将upstream { keepalived 100}值调小点。
发生该问题的原因是:B和C之间空闲连接数太多,会经常有断开的连接的场景,只要将keepalived的值调小点,让连接通道更加繁忙,则不会触发断开的操作。
keepalived参数: 指定每个worker进程针对这个upstream保持多少个长连接,比如keepalived 100,有16个worker,则总共对这个upstream最多1600个长连接,这个值在后端服务器压力不大的情况下可以调小。调小的危害是:超过这个总数之后,再来的请求都只能是短连接,可能会影响系统性能。
参考连接:
https://www.cnblogs.com/succour/p/6305574.html
http://www.cnblogs.com/kabi/p/7123354.html
二 状态码
将客户端--> 网关 --> 后端web服务器分别编号为1 2 3
Nginx 504 Gateway Time-out
3机器上的nginx.conf配置:
fastcgi_connect_timeout 300s;
fastcgi_send_timeout 300s;
fastcgi_read_timeout 300s;
fastcgi_buffer_size 128k;
fastcgi_buffers 8 128k;#8 128
fastcgi_busy_buffers_size 256k;
fastcgi_temp_file_write_size 256k;
fastcgi_intercept_errors on;
3机器上的php-fpm.conf
max_children
request_terminate_timeout
三
Error:
test_ngx_array_t.c: In function ‘main’:
test_ngx_array_t.c:78: error: ‘ngx_http_request_t’ undeclared (first use in this function)
test_ngx_array_t.c:78: error: (Each undeclared identifier is reported only once
解决方法:
#include "ngx_http.h"
九 [TO UNDERSTAND]
1 squid反向代理