python爬虫:带你游览微博博主的前世今生
文章目录
- 一、前言
- 二、项目目标
- 三、环境配置
- 四、数据提取分析
- 4.1 用户微博主页分析
- 4.2 微博详情页分析
- 五、代码编写
- 5.1 创建scrapy项目和爬虫
- 5.2 修改setting.py
- 5.3 设置items.py
- 5.4 编写one_people.py
- 5.5 编写pipelines.py
- 5.6 编写midelewares.py
- 六、 结果展示
- 6.1 评论数据展示
- 6.2 微博数据展示
- 七、 项目总结
一、前言
因为疫情的缘故,最近在家老被疫情微博消息轰炸,还每次都忍不住点进去看,关心国内又增长了多少人出院了多少人,国外,尤其是韩国日本伊朗等又激增了多少人,然后看下面大家的评论,看的我胆战心惊的。疫情不分国界,希望大家都能顺顺利利挺过这次全球灾难。
当然,被困在家也要找点事情做,目前在研究爬虫,因为上面提到的微博的事,刚好就把目标放到微博上来了。
接下来我们就一起来爬取微博数据吧!
二、项目目标
- 任给一个用户的微博主页链接能够爬取他所有的微博以及点赞数等相关信息。
- 对任意一条微博,可以爬取到他所有的回复,以及回复的点赞数,被回复数。
- 将以上两者结合起来,实现对任意一个用户,爬取他的微博信息,所有微博以及每条微博的所有评论信息。
- 额外拓展(尚未完成): 对每条微博的评论内容再做一次提取,提取评论者id,然后进入评论者主页进行重复爬取,直至完成对整个微博所有用户所有信息的爬取。
三、环境配置
- 语言:python 3.8.1
- 开发工具:vscode
- 浏览器:Chrome
- 抓包工具:mimtweb
- 爬虫框架:scrapy 1.8.0
四、数据提取分析
4.1 用户微博主页分析
从电脑进入到微博网站,注意,这里进的是 w.weibo.cn 这个网址,这个是移动端的网址,界面看起来简单很多,少很多干扰因素。
进入到用户微博主页,为了防止你们说我打广告,我进是团团的主页⬇️⬇️
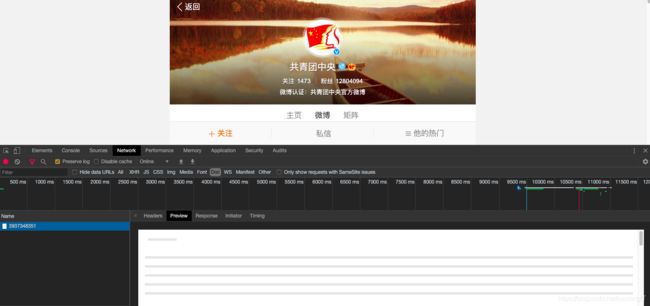
经过chrome的自带工具,我们可以看到这个html页面文件里面什么数据也没有,所以我们判断这个页面的数据是异步加载请求的。我们捕捉这个请求。

对请求进行一一分析之后,找到了这个请求微博用户信息的接口,它返回的是标准的json格式数据。里面除了用户信息还有一些其它的数据,我们暂时不知道有什么用,先留着。
接下来我们需要对接口进行优化,这样做是为了提高爬虫效率同时避免因为一些不必要的参数导致请求失败。
我们来看优化前后的请求对比⬇️

对比优化之后的请求⬇️

经过一番折腾,发现对于这个请求而言,url链接里面的containerid是不必要的,可以删去,同时请求头里面很多参数也是不必要的。cookie里面唯一需要保留的就是这个SUB值,如果失去了它,会请求失败。
优化之后我们可以利用用户id来拼凑出请求它主页信息的接口url。

这是主页的url,u/ 后面那一部分就是用户的id。用这个id拼凑出接口,去掉后面那个containerid值。
![]()
现在微博用户信息的接口找到并优化好之后,就需要开始寻找请求这个微博用户的每一条微博的接口。

寻找到了请求微博的接口,但是这部分出现了一个有意思的东西!来观察一下这个新找到的接口。
![]()
惊讶的发现,这个接口居然和刚才那个接口惊人的相似!经过分析之后,发现这两个接口之间只有一个地方不同!那就是url后面的containerid值。当尝试把这个containerid值删去之后,请求回来的结果果然又变成了之前请求微博用户信息的结果。
然后先将微博往下翻,让他继续请求新的微博信息,得到这样一个url

与第一次请求微博相比,它又只多了一个参数since_id,并且containerid不变,这样的话,我们可以把它理解成起始量,也就是,从哪开始获取新的微博信息。
接下来的任务是寻找到 containerid 和 since_id的值是从哪获得的。
山重水复疑无路,踏破铁鞋无觅处。柳暗花明又一村,得来全不费功夫。(狗头)containerid 值就存放在刚开始请求用户信息的地方。

看到这一部分内容,再联想到container这个单词,便可大致理解它为一个容器,所以这个id就是专门存储微博的容器id。
然后联想到since_id的作用,它是用来标明这一次请求微博从哪里开始,那么我们应该能在上一次请求微博返回的信息中找到它,不出我的所料⬇️⬇️

然后同样的,优化一下请求微博的接口参数,用户微博主页分析我们就算完成了,来小结一下请求步骤。
- 获取用户主页url,获得用户id。
- 利用用户id拼凑出请求微博用户信息的接口。
- 获取需要的用户信息,并获取微博的containerid值。
- 再利用上一个接口和containerid值拼凑出请求微博的第一个接口url。
- 获取微博信息之后,利用里面的since_id再拼凑出第二次请求微博的接口url。
- 重复第五步直到抓取完毕。
4.2 微博详情页分析
进入一个微博的详情页,简单分析了一下数据来源,发现在详情页里面的微博文本虽然没有直接放在html元素里面呈现出来,但其实并不是异步请求。而是放在了html文件里的js代码内部封装⬇️⬇️

我们可以通过正则从html文件中提取出微博的文本数据。
接下来再寻找评论部分的数据来源。
评论的接口网址是这个
![]()
这个接口中的id和mid数值一样且固定为这条微博的id,而这条微博的id可以从4.1中获取或者是微博详情页URL获取。
这样就可以拼凑出第一批评论接口url。
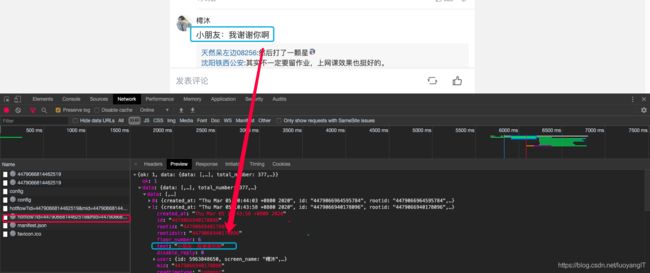
这就是第一批评论的数据来源接口了,为什么非要强调这是第一批呢?因为从第二批开始,接口就有所变化了。看一下对比。
![]()
⬇️⬇️⬇️
![]()
从这里看出来,从第二批评论开始,接口中就多了一个参数max_id,而经过抓包修改测试,这个参数无法去除,同时数值也需要准确,会不停变化。
那么这个max_id从哪来呢?
还记得4.1 的时候分析的那个数值since_id嘛?从前一个接口里面获取到下一个接口需要的参数。这里也是一样的道理!
来看一下通过获取第一批评论的接口获取到的数据下方:

果不其然这里有我们需要的max_id,这样我们就能很简单的拼凑出再下一批的接口url了。
等一下。你以为这样就算完了?
不!经过我的踩坑,这里还有一个很需要注意的地方,就是那个不起眼的max_id_type。
在上面的接口url中,它一直都等于0,但是事实上,它是会变成1的。并且暂时没有摸清具体什么时候变。
这个坑,如果踩过就很简单,因为max_id_type的值也是与max_id一同知道了的,但是如果没踩过,很容易误认为就永远为0。
优化一下请求的接口参数:
这里的cookie同样只需要SUB,值与4.1相同且不变,如果失去这个SUB会被重定向导致获取不到数据。
小结一下4.2:
- 从微博详情页html里面用正则提取出文本内容。
- 利用微博id拼凑出第一批评论请求接口。
- 从第一批接口中提取数据,同时利用获取的max_Id 和max_id_type拼凑下一个接口。
- 获取数据,拼凑下一个接口。
- 重复第四步。
五、代码编写
到了手底下见真章的时候了。开始吧。
5.1 创建scrapy项目和爬虫
不用使用-t crawl模板设置规则来爬去,直接创建一个普通的爬虫就可以
scrapy startproject weibo
cd weibo
scrapy genspider one_people
原谅我粗糙的取名水平。
5.2 修改setting.py
- robots协议
- 爬取延迟
- 默认请求头,关闭cookie
- 打开管道和下载中间件
首先把遵守robot协议设置为False,同时把爬取延时设置三秒以上
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
然后设置一下默认的请求头,并且有很重要的一点是:将cookies设置为禁用状态。
因为如果不禁用,那么scrapy框架会根据返回的set-cookie值自动生成cookie,最后导致网页被重定向。
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'host': 'm.weibo.cn',
'accept': 'application/json, text/plain, */*',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'SUB=_2A25zUZngDeRhGeBO6FQW9izFyjuIHXVQvSeorDV6PUNbktANLXPVkW1NShqrqT_gNAKqD3jr0wVYJ8UqOFgnZdeJ;'
}
然后就是把下载中间件和管道开起来。下载中间件用来随机更换请求头,有必要的话也用来更换ip, 管道用来存储数据。
DOWNLOADER_MIDDLEWARES = {
'weibo.middlewares.WeiboDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
# }
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'weibo.pipelines.WeiboPipeline': 300,
}
5.3 设置items.py
为三种爬取的数据聚合设置三个item
item的编写是确定我们要爬取的数据内容,然后可以封装在scrapy.Item类里面从爬虫部分输送到管道部分保存。
class CommentItem(scrapy.Item):
'''评论item'''
# 评论时间
comment_time = scrapy.Field()
# 评论文本
text = scrapy.Field()
# 评论人id
comment_people_id = scrapy.Field()
# 评论人name
comment_people_name = scrapy.Field()
# 评论点赞数
comment_likes = scrapy.Field()
# 评论回复总数
total_number = scrapy.Field()
class PeopleItem(scrapy.Item):
'''用户item'''
# 用户昵称
name = scrapy.Field()
# 用户id
user_id = scrapy.Field()
# 关注数
follow_count = scrapy.Field()
# 粉丝数
followers_count = scrapy.Field()
# 描述
description = scrapy.Field()
# 微博数
statuses_count = scrapy.Field()
# 是否认证
verified = scrapy.Field()
# 认证缘由
verified_reason = scrapy.Field()
class StatusesItem(scrapy.Item):
'''微博item'''
# 最后编辑于
edit_at = scrapy.Field()
# 文本
text = scrapy.Field()
# 转发数
reposts_count = scrapy.Field()
# 评论数
comments_count = scrapy.Field()
# 点赞数
attitudes_count = scrapy.Field()
# 微博id
statues_id = scrapy.Field()
# 详情页URL
origin_url = scrapy.Field()
5.4 编写one_people.py
长代码警告
import scrapy
import json
from weibo.items import PeopleItem, StatusesItem, CommentItem
import re
class OnePeopleSpider(scrapy.Spider):
name = 'one_people'
allowed_domains = ['w.weibo.cn']
start_urls = ['https://m.weibo.cn/u/3664122147']
usr_id = start_urls[0].split('/')[-1]
def start_requests(self):
'''首先请求第一个js文件,包含有关注量,姓名等信息'''
js_url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value=' + \
self.usr_id
yield scrapy.Request(url=js_url,
callback=self.parse_info,
dont_filter=True)
def parse_info(self, response):
js = json.loads(response.text)
infos = js['data']['userInfo']
name = infos['screen_name']
user_id = infos['id']
follow_count = infos['follow_count']
followers_count = infos['followers_count']
description = infos['description']
# 微博数
statuses_count = infos['statuses_count']
verified = infos['verified']
verified_reason = ''
if verified == True:
verified_reason = infos['verified_reason']
item = PeopleItem(name=name,
user_id=user_id,
follow_count=follow_count,
followers_count=followers_count,
description=description,
statuses_count=statuses_count,
verified=verified,
verified_reason=verified_reason)
yield item
weibo_containerid = str(
js['data']['tabsInfo']['tabs'][1]['containerid'])
con_url = '&containerid=' + weibo_containerid
next_url = response.url + con_url
print(next_url)
yield scrapy.Request(url=next_url,
callback=self.parse_wb,
dont_filter=True)
def parse_wb(self, response):
try:
js = json.loads(response.text)
datas = js['data']['cards']
for data in datas:
# 去掉推荐位和标签位
if len(data) == 4 or 'mblog' not in data:
continue
edit_at = data['mblog']['created_at']
text = data['mblog']['text']
reposts_count = data['mblog']['reposts_count']
comments_count = data['mblog']['comments_count']
attitudes_count = data['mblog']['attitudes_count']
statues_id = str(data['mblog']['id'])
origin_url = data['scheme'].split('?')[0]
item = StatusesItem(edit_at=edit_at,
text=text,
reposts_count=reposts_count,
comments_count=comments_count,
attitudes_count=attitudes_count,
statues_id=statues_id,
origin_url=origin_url)
yield item
if 'since_id' not in js['data']['cardlistInfo']:
exit(0)
since_id = str(js['data']['cardlistInfo']['since_id'])
next_url = ''
if 'since_id' not in response.url:
next_url = response.url + '&since_id=' + since_id
else:
next_url = re.sub(r'since_id=\d+', 'since_id=%s' %
since_id, response.url)
except Exception as ret:
print("=" * 40)
print("这里出错了: %s" % ret)
print("="*40)
print(js)
print("=" * 40)
yield scrapy.Request(url=next_url,
callback=self.parse_wb,
dont_filter=True)
self.comments_url = 'https://m.weibo.cn/comments/hotflow?id={0}&mid={1}'.format(statues_id, statues_id)
yield scrapy.Request(url=self.comments_url,
callback=self.parse_comments,
dont_filter=True)
# =========================================================================
# 下面这部分爬取每条微博的评论,
def parse_comments(self, response):
js = json.loads(response.text)
max_id = '&max_id=' + str(js['data']['max_id'])
next_url = response.url + max_id
print("=" * 40)
print(next_url)
yield scrapy.Request(url=response.url + max_id,
callback=self.parse_comments_next,
dont_filter=True)
def parse_comments_next(self, response):
try:
js = json.loads(response.text)
for comment in js['data']['data']:
comment_time = comment['created_at']
text = comment['text']
comment_people_id = comment['user']['id']
comment_people_name = comment['user']['screen_name']
comment_likes = comment['like_count']
total_number = comment['total_number']
item = CommentItem(comment_time=comment_time,
text=text,
comment_people_id=comment_people_id,
comment_people_name=comment_people_name,
comment_likes=comment_likes,
total_number=total_number)
yield item
max_id = "&max_id=" + str(js['data']['max_id'])
max_id_type = '&max_id_type=' + str(js['data']['max_id_type'])
print("=" * 40)
print(max_id)
print(max_id_type)
print("=" * 40)
yield scrapy.Request(url=self.comments_url + max_id + max_id_type,
callback=self.parse_comments_next,
dont_filter=True)
except Exception as ret:
print("=" * 40)
print("此处出错!%s" % ret)
print(response.text)
print("=" * 40)
这份爬虫代码,已经将爬取用户微博主页和爬取微博详情页结合了起来,能够实现爬取一个微博用户的所有微博和他所有微博的所有评论功能。
具体的实现涉及到了scrapy框架的应用,利用callback不断跳转处理函数来实现处理不同的信息以及拼凑和传递不同的URL。
同时里面有一些看起来无用的调试代码,能让我在运行scrapy爬虫的时候清楚的看到哪里错了,除了什么问题等。
5.5 编写pipelines.py
- 根据传入进来的item类不同,将信息放入不同的json文件夹里面去
- 使用了scrapy内置的json导出类
from weibo.items import PeopleItem, StatusesItem, CommentItem
from scrapy.exporters import JsonLinesItemExporter
class WeiboPipeline(object):
def __init__(self):
self.comments_fp = open("comments.json", "wb")
self.people_fp = open('people.json', 'wb')
self.statuses_fp = open('statuses.json', 'wb')
self.comments_exporter = JsonLinesItemExporter(self.comments_fp,
ensure_ascii=False)
self.people_exporter = JsonLinesItemExporter(self.people_fp,
ensure_ascii=False)
self.statuses_exporter = JsonLinesItemExporter(self.statuses_fp,
ensure_ascii=False)
def process_item(self, item, spider):
if isinstance(item, CommentItem):
self.comments_exporter.export_item(item)
elif isinstance(item, PeopleItem):
self.people_exporter.export_item(item)
else:
self.statuses_exporter.export_item(item)
return item
def close_item(self, spider):
print("存储成功!")
self.comments_fp.close()
self.people_fp.close()
self.statuses_fp.close()
5.6 编写midelewares.py
- 实现自动更换请求头
class WeiboDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
user_agents = [
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv,2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; rv,2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11'
]
def process_request(self, request, spider):
user_agent = random.choice(self.user_agents)
request.headers['User-Agent'] = user_agent
六、 结果展示
6.1 评论数据展示

6.2 微博数据展示

七、 项目总结
-
这次微博数据爬取,对我自己也是一个不小的挑战,刚开始并没有使用mitmweb来抓包分析请求,一直在用jupyter和requests来不断更改请求头来确认需要的值和优化请求,经常会碰到请求数据失败和重定向而导致请求不到数据的问题。
-
同时,微博的这种前一个请求中带有后一个请求需要的参数这种请求方式刚开始也让我很懵逼,摸不着头脑。
-
与上文提到的一样,就在我以为成功了的时候,那个max_id_type着实坑了我一把,我想当然的以为这个值恒为0,没算到它居然会变。
-
接下来想去破解js加密的一些内容和登录的内容,然后去尝试抓取手机app的信息。
我是落阳,一个正在努力的无名之辈,谢谢你的关注。欢迎找我一起探讨问题。
获取源代码请关注公众号【程序小员】回复:微博爬虫。