Python爬虫攻略(1)>使用Requests获取LOL游戏攻略
申明:本文对爬取的数据仅做学习使用,不涉及任何商业活动,侵删
Python爬虫教程>1 使用Requests获取LOL游戏攻略
前戏
如果你想先了解一下什么是爬虫, 建议看一下这篇文章:学习爬虫前你需要知道这些
英雄联盟官方攻略站, 我们的目标是这些带有教学标签的文章

页面分析
这里大多是类似新闻的时效性文章, 因此推断 ->文章列表随时会更新 -> 动态加载
既然是动态加载, 那就说明要么是JS动态渲染, 要么就是ajax请求数据, 我们来逐个排除
先看ajax, 直接F12, 然后刷新页面并查看Network中的请求记录 (XHR即为ajax请求), 可以发现并没有类似文章数据的请求

ps: 鼠标放在社区栏时, 会有一个社区文章的ajax请求(图中第4个), 其余的专栏都是没有ajax的
既然不是ajax, 那就是js, 来看js中的情况
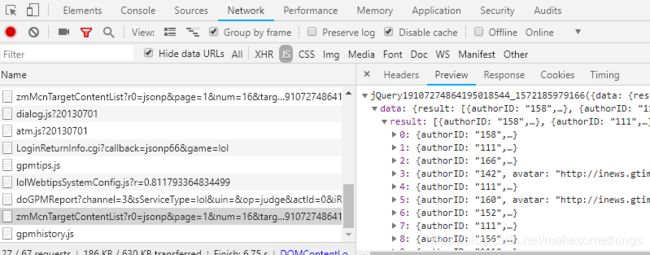
如图, 这个以zmMcnTargetContentList为开头的就是我们要找的, url如下:
https://apps.game.qq.com/cmc/zmMcnTargetContentList?r0=jsonp&page=1&num=16&target=27&source=web_pc&r1=jQuery19107274864195018544_1572185979166&_=1572185979169
其中参数page代表页码, num代表每页文章的个数
开始编码
爬虫代码如下
import requests
import re
import json
def get_data(m_url):
# 向目标网站发送get请求
resp = requests.get(url=m_url)
# 清洗返回的响应, 清洗得到的是str
resp_cleared = re.findall(r'.*?\(({.*?})\);', resp.text)[0]
# str转化为json, 返回一个list, 包含文章数据
return json.loads(resp_cleared)['data']['result']
def write_data(data_list):
item = {} # 定义一个空字典作为容器, 用来存放目标数据
with open('lol_guide.json', 'w') as file:
# 循环遍历文章list中的每一篇文章
for data in data_list:
# 写入容器
item['Title'] = data['sTitle']
item['URL'] = data['sRedirectURL']
item['Date'] = data['sIdxTime']
# 使用dumps, 将字典转化为json, 以便写入文件
content = json.dumps(item, ensure_ascii=False) + '\n'
file.write(content) # 写入文件
print('#写入成功 - {}'.format(item['Title']))
if __name__ == '__main__':
url_mode ='https://apps.game.qq.com/cmc/zmMcnTargetContentList?r0=jsonp&page={}&num=16&target=27&source=web_pc'
# 循环的目的是遍历下一页的url
for i in range(1, 7):
url = url_mode.format(i)
write_data(get_data(url))
执行结果
得到的json数据如下
{"Title": "恶魔刺客轻松应对 降星枪剑体系重新崛起", "URL": "https://lol.tuwan.com/400929/", "Date": "2019-09-06 15:03:40"}
{"Title": "9.17云顶之弈三大新兴套路 贵族船长翻身成为主C", "URL": "https://www.lolfun.cn/news/detail.html?id=9031", "Date": "2019-09-05 16:16:50"}
{"Title": "9.18云顶新装备来袭!阵容搭配全面解读", "URL": "https://www.titanar.com/pub/propaganda/5757", "Date": "2019-09-05 16:15:08"}
...
参考链接
Request(官方) 快速上手
Python中的JSON库
正则表达式