Python网络爬虫数据采集实战:Selenium库爬取京东商品
通过前文爬虫理论结合实战的部分我们对爬虫有了初步的了解,首先通过requests模拟浏览器进行请求,接着通过正则表达式或者解析库对网页进行解析,还知道了动态网页Ajax的爬取方法,但总是担心模拟不够会被反爬侦测出来,而本文要介绍的方法则是直接调用浏览器的方式进行高仿浏览器爬虫,这样就再也不用担心啦~
目录
一、Selenium库介绍
1.Selenium简介
2.Selenium安装
3.Selenium使用
二、京东商品爬虫实战
1.京东网页分析与获取
2.网页信息提取
3.网页信息存储
4.自动化爬虫构建
一、Selenium库介绍
1.Selenium简介
selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)。Selenium的核心Selenium Core基于JsUnit,完全由JavaScript编写,因此可以用于任何支持JavaScript的浏览器上。

2.Selenium安装
Selenium的安装可以使用如下命令:
pip install selenium还没完!由于我们推荐chrome谷歌浏览器作为模拟浏览器,因此我们还需要chromedriver作为驱动,相应版本选择需要查看谷歌浏览器版本,在chrome浏览器上方地址栏输入:
chrome://settings/help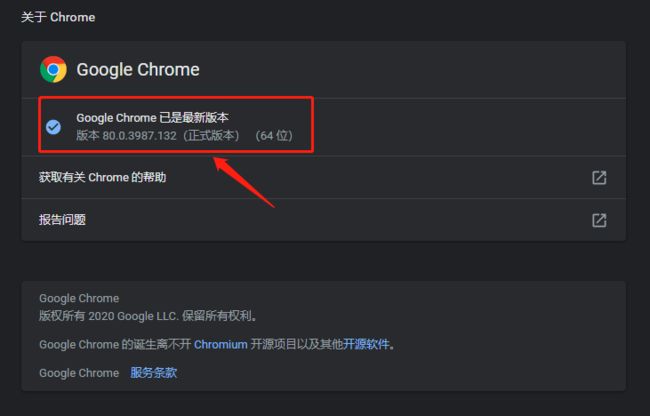
作者chrome浏览器版本为80.0.2987.132,通过此版本号进入chrome-driver镜像地址:http://npm.taobao.org/mirrors/chromedriver/ 找到并下载放入anaconda根目录(即与python.exe同目录下面):

3.Selenium使用
如果想要声明并调用浏览器则需要:
# 通过selenium导入webdriver方法from selenium import webdriver# 通过webdriver方法调用谷歌浏览器驱动browser = webdriver.Chrome()

访问页面:
url = 'https:www.baidu.com'#打开浏览器预设网址browser.get(url)#打印网页源代码print(browser.page_source)#关闭浏览器browser.close()
查找元素,此处列举下常用查找元素方法:
-
find_element_by_name
-
find_element_by_id
-
find_element_by_xpath
-
find_element_by_link_text
-
find_element_by_partial_link_text
-
find_element_by_tag_name
-
find_element_by_class_name
-
find_element_by_css_selector
url = 'https:www.taobao.com'#打开浏览器预设网址browser.get(url)# 通过input_first = browser.find_element_by_id('q')input_two = browser.find_element_by_css_selector('#q')print(input_first)print(input_two)
交互动作:
from selenium import webdriver# 导入交互动作模块from selenium.webdriver import ActionChainsbrowser = webdriver.Chrome()url = "http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable"browser.get(url)browser.switch_to.frame('iframeResult')source = browser.find_element_by_css_selector('#draggable')target = browser.find_element_by_css_selector('#droppable')actions = ActionChains(browser)actions.drag_and_drop(source, target)actions.perform()
获取ID,位置,标签名:
from selenium import webdriverbrowser = webdriver.Chrome()# 知乎探索页url = 'https://www.zhihu.com/explore'browser.get(url)# 通过css选择器查找标签input = browser.find_element_by_css_selector('.zu-top-add-question')print(input.id)print(input.location)print(input.tag_name)print(input.size)
二、京东商品爬虫实战
1.京东网页分析与获取
首先确定想要爬取的商品,此处我们假定要爬取京东关键字为“电脑”的所有商品信息,先登录京东界面并在搜索框中输入“电脑”,之后将链接复制。


我们需要爬取的是这样的一个页面,包含电脑相关信息,并且还要进行翻页爬取,这里我们将直接采用Selenium库模拟谷歌浏览器进行操作。爬虫的基本思路为:利用程序模拟浏览器自动打开网页,然后以上文链接作为起始页打开,等到页面加载完毕后,爬取这一页的数据,然后模拟鼠标点击下一页,等下一页加载完毕后再次爬取数据。
首先导入库:
import csvimport jsonimport timeimport randomfrom selenium import webdriverfrom selenium.webdriver.support.wait import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.by import Byimport selenium.common.exceptions
之后通过调用webdriver的的chrome方法控制chrome浏览器并设置等待,
start_url = 'https://search.jd.com/Search?keyword=%E7%94%B5%E8%84%91&enc=utf-8&pvid=fc7e43c13ba3462ca2cfbbbc71781862'browser = webdriver.Chrome()browser.implicitly_wait(10)wait = WebDriverWait(browser,10)
2.网页信息提取
通过Selenium库内置的Xpath解析方法和css选择器将商品价格、名称、评论提取出来:
prices = wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[2]/strong/i')))names = wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[3]/a/em')))commits = wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[4]/strong')))
3.网页信息存储
本文设置两种存储方式,json和csv:
if file_format=='json' :for i in range(60):count += 1print('写入数据:'+str(count))item = {}item['price'] = prices[i].textitem['name'] = names[i].textitem['commit'] = commits[i].textjson.dump(item,file,ensure_ascii = False)elif file_format=='csv' :for i in range(60):count += 1print('写入数据:'+str(count))item = {}item['price'] = prices[i].textitem['name'] = names[i].textitem['commit'] = commits[i].textfor key in item:writer.writerow([key, item[key]])
4.自动化爬虫构建
定义模拟翻页程序:
def turn_page(self):try:self.wait.until(EC.element_to_be_clickable((By.XPATH,'//a[@class="pn-next"]'))).click()self.browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")time.sleep(3)except selenium.common.exceptions.NoSuchElementException:return Trueexcept selenium.common.exceptions.TimeoutException:print('turn_page:TimeoutException')self.page_turning()except selenium.common.exceptions.StaleElementReferenceException:print('turn_page:StaleElementReferenceException')self.browser.refresh()else:return False
综上,我们将整个爬虫程序写入JditemSpider类,同时将存储文件形式写入类的构造方法,在类中依次定义parse_page方法用于解析单页网页,write2file方法将数据增量写入csv文件或json文件中,turn_page方法定义翻页,close方法在爬虫结束之后自动关闭浏览器,crawl方法为京东商品自动化行为,整个JditemSpider面向对象类结构如下,可进一步加入异常处理:
class JditemSpider():def init(self):self.file_format = 'csv'while self.file_format!='json' and self.file_format!='csv':self.file_format = input('请选择[json] [csv]中的一种输入')if self.file_format=='json' :self.file = open('jd_item.json','w',encoding='utf-8')elif self.file_format=='csv' :self.file = open('jd_item.csv','w',encoding='utf-8',newline='')self.writer = csv.writer(self.file)print('File Initialized')self.prices = []self.names = []self.commits = []self.count = 0self.start_url = 'https://search.jd.com/Search?keyword=%E7%94%B5%E8%84%91&enc=utf-8&pvid=fc7e43c13ba3462ca2cfbbbc71781862'print('Data Initialized')self.browser = webdriver.Chrome()self.browser.implicitly_wait(10)self.wait = WebDriverWait(self.browser,10)print('Browser Initialized')def parse_page(self):self.prices = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[2]/strong/i')))self.names = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[3]/a/em')))self.commits = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[4]/strong')))def write2file(self):if self.file_format=='json' :for i in range(60):self.count += 1print('写入数据:'+str(self.count))item = {}item['price'] = self.prices[i].textitem['name'] = self.names[i].textitem['commit'] = self.commits[i].textjson.dump(item,self.file,ensure_ascii = False)elif self.file_format=='csv' :for i in range(60):self.count += 1print('写入数据:'+str(self.count))item = {}item['price'] = self.prices[i].textitem['name'] = self.names[i].textitem['commit'] = self.commits[i].textfor key in item:self.writer.writerow([key, item[key]])def turn_page(self):self.wait.until(EC.element_to_be_clickable((By.XPATH,'//a[@class="pn-next"]'))).click()self.browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")time.sleep(3)def close(self):self.browser.quit()print('Finished')def crawl(self):self.init()self.browser.get(self.start_url)self.browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")while True:self.parse_page()self.write2file()if self.turn_page()==True :breakself.close()
至此利用Selenium库模拟浏览器爬取京东动态网页的爬虫构建完成,再通过此爬虫总结一下:首先我们通过浏览网页结构获取网页起始页,并通过webdriver方法调起谷歌浏览器,然后通过xpath解析方法获取当前页面所想获取到的信息并存为csv,之后通过模拟浏览器翻页行为进行自动化翻页,从而建立起整个循环爬虫结构,最后将其封装为一个JditemSpyder类,通过调用此类的crawl方法即可完成自动化爬取。结果如下:

爬虫完整代码可以在公众号中回复“京东”获得。下文将进一步对手机app抓包爬虫进行讲解和实战,前文涉及的基础知识可参考下面链接:
Python网络爬虫数据采集实战:基础知识
Python网络爬虫数据采集实战:Requests和Re库
Python网络爬虫数据采集实战:豆瓣电影top250爬取
Python网络爬虫数据采集实战:网页解析库
Python网络爬虫数据采集实战:同花顺动态网页爬取
学习号,涉及数据分析与挖掘、数据结构与算法、大数据组件及机器学习等内容
