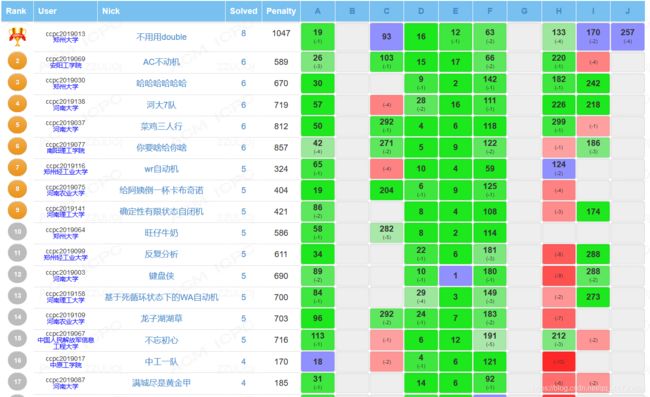
第五届ccpc河南省赛 //题解 + 体会
“卓见杯”第五届CCPC中国大学生程序设计竞赛河南省赛 ---- 4.13.2019
zzq一眼看破两个签到题,6分钟就A了。
第一个题:
PD
文本修正
时间限制: 1 Sec 内存限制: 256 MB
提交: 588 解决: 239
[提交] [状态] [讨论版] [命题人:外部导入]题目描述
Chika接到了去检查河南省算法竞赛题面的任务,她发现所有单词"Henan"的首字母都没有大写。她需要去修正文本中的所有错误。换句话说,她需要把所有单词"henan"的首字母从"h"替换为"H",同时保留文本的其余部分不变。你能帮助她吗?
输入
输入文件仅包含一行,包含被空格分割开的单词,代表Chika被要求去检查的文本。输入的字符总数不超过200,只含有大小写字母和空格。要注意,只有被空格分割开的仅包含字母的连续串才被称为“单词”。
输出
输出文件应该只包含一行,代表你修正后的文本。
样例输入 Copy
Hello henan algorithm contest样例输出 Copy
Hello Henan algorithm contest
zzq花式多组输入,秀(好像看不到输出WA了一次,但是我自己电脑上面可以看到输出),不过确实好用。
#include
using namespace std;
#define LL long long
#define mod 1000000007
const int max_n=1e3;
int main(){
string s;bool vis=0;
while(cin>>s){
if(vis==1)cout<<' ';
else vis=1;
if(s=="henan") cout<<"Henan";
else cout< 第二个题:
PE
咕咕的的复复读读机机
时间限制: 1 Sec 内存限制: 64 MB
提交: 419 解决: 241
[提交] [状态] [讨论版] [命题人:外部导入]题目描述
咕咕一直想买台复读机,今天他终于走进了一家卖复读机的小店!这里有很多很多的复读机,咕咕看中 了一台相貌平平无奇的,他决定试用一下这台复读机的功能。然而,当他打开复读机的开关后,复读机 说了 n 个数字,而且这些数字不完全一样——作为一台复读机,怎么会这样呢?看到满脸疑惑的咕咕, 店员说道:” 这是一台带有自动加噪的复读机,它虽然 n 次中说的数字不完全一样,但是它所复读的 那个数字永远会在这 n 次中出现次数最多!”
于是,聪明的你,知道这 n 个数字之后,你能猜出那个数字是它所复读的数字吗?
于是,聪明的你,知道这 n 个数字之后,你能猜出那个数字是它所复读的数字吗?输入
第一行一个数字 n(1 ≤ n ≤ 100)。
第二行有 n 个数字(范围在 [1,100] 之间),表示这台复读机所说的 n 个数字。
这台复读机保证它所复读的那个数字是唯一的!输出
输出那个数字。
样例输入 Copy
3 2 4 2样例输出 Copy
2
#include
using namespace std;
#define LL long long
#define mod 1000000007
const int max_n=1e3+5;
int cnt[max_n];
int main(){
int n;cin>>n;
int ans;
int mx=0;
while(n--){
int x;cin>>x;
cnt[x]++;
if(cnt[x]>mx){
mx=cnt[x];
ans=x;
}
}
cout<
然后和zzq一起看A,dpjujuzzq想了几秒说是LIS,当我还在考虑要不要用二分,手速极快zzq就敲完了,交了一发后发现WA了,此时发现这题居然没人通过,zzq直接说换题,果然明智。过了半小时,重判后,拿了首杀。
第三个题:
PA
最大下降矩阵
时间限制: 1 Sec 内存限制: 512 MB
提交: 524 解决: 115
[提交] [状态] [讨论版] [命题人:外部导入]题目描述
我们称一个矩阵是下降矩阵,当且仅当,矩阵的每一列都是严格下降的。很显然,这个要求很苛刻,大多数矩阵都无法满足。但是显然如果消去一些行,一定可以使得这个矩阵变成下降矩阵。
现在给出一个n行m列的矩阵,请你求出最少消去多少行,可以使得这个矩阵变为下降矩阵。输入
输入第一行包含两个正整数n,m分别表示矩阵的行数和列数。(1<=n,m<=300)
接下来n行,每行有m个数,中间用空格隔开,每个数都小于2^31.输出
输出仅包含一个整数,即最少消去的行数。
样例输入 Copy
1 3 1 2 3样例输出 Copy
0
一行当做一个元素,重写cmp。
300*300*300 不需要二分(越来越喜欢当一行怪了...
#include
using namespace std;
#define LL long long
#define mod 1000000007
const int max_n=305;
int mp[max_n][max_n];
int dp[max_n];
bool check(int x1,int x2,int m){
for(int i=1;i<=m;i++)if(mp[x1][i]<=mp[x2][i]) return 0;
return 1;
}
int main(){
int n,m;cin>>n>>m;
for(int i=1;i<=n;i++) for(int j=1;j<=m;j++) scanf("%d",&mp[i][j]);
dp[1]=1;
for(int i=2;i<=n;i++){
dp[i]=1;
for(int j=1;j 然后我B,C,H(三棵树...),看了一圈,因为C输出描述有问题,我就去看H了。
H我有了思路,结果写了一发WA了。
这时郑大juju过了C,我去看C,,,,,,,,,,,,,,
zzq和我看了好一会C,也没有思路,vector,set瞎搞了半天,最后写了个TLE算法。
然后zzq和一直在看F的wzy过了F,然而我还在看我不可能写出来的C,,,,
第四个题:
PF
咕咕的计数题 II
时间限制: 1 Sec 内存限制: 64 MB
提交: 1109 解决: 69
[提交] [状态] [讨论版] [命题人:外部导入]题目描述
咕咕最近在学习初等数论,并且对下取整函数产生了极大的兴趣。下取整函数是指一个函数,自变量为 一个实数,因变量为一个整数,这个整数恰好是小于或等于自变量的最大的整数,通常记做 ⌊x⌋。例如, ⌊2.5⌋ = 2,⌊2⌋ = 2,⌊−2.5⌋ = −3。
咕咕发现,给定一个 a,并不是所有的自然数 n 都存在一个正整数 i 使得 ⌊n/i⌋ = a。那么,如果给定 l,r,咕咕好奇在区间 [l,r] 中有多少个正整数能使这个等式有正整数解 i 呢?
那么,聪明的你,你能告诉咕咕吗?输入
第一行有一个整数 T(1 ≤ T ≤ 106),表示数据组数。接下来有 T 行,每行有三个数 a,l,r(1 ≤ a ≤ 1018,1 ≤ l ≤ r ≤ 1018),表示一组询问。
输出
输出 T 行,对每组询问,输出一个整数表示答案。
样例输入 Copy
4 5 7 10 7 39 42 1000 1000 1000 27 100 1000样例输出 Copy
1 2 1 617提示
数据范围
当 n = 39,a = 7 时,能找到 i = 5 使得 ⌊39 /5 ⌋ = 7。
题解看zzq赛后写的吧:https://www.cnblogs.com/zzqc/p/10704290.html
过了F zzq和我又开始看C,,,,学过主席树的zzq发现是个主席树(liangliang)。。。。
无能为力,我又回到了H,突然恍然大悟,思路有bug,没有考虑到不在一个子树的情况,。
发现需要求出lca的对应的子树,走投无路的我只能硬着头皮开始写H(然而我第一次写普通lca,只写过tarjan),抄模板写出了倍增lca,,,,交了MLE,,MLE???行吧,,,
最后时间剩大概一个小时,zzq和wzy开 I,我继续改lca,到最后我也没发现,直接暴力lca就行。。。。zzq想复杂了 I,结束了前我xjb改了lca 交了13发,都是无情MLE(怪我没有见过MLE,不怎么考虑空间复杂度鸭)...
最后结束 C H I 通过 7 7 9
不幸中的幸运是,我们金尾....
好气啊,H和I可惜了(哭唧唧.jpg)....万恶C卡2小时,万恶歪榜!
赛后我补的H
咕咕的搜索序列
时间限制: 1 Sec 内存限制: 128 MB
提交: 238 解决: 10
[提交] [状态] [讨论版] [命题人:外部导入]题目描述
咕咕已经学到树上的深度优先搜索 (dfs) 啦!由于同一棵树不同的 dfs 访问结点的次序不一样,咕咕干脆定义 了一个搜索序列:一开始序列为空,而每次离开这个点,并且不会再返回这个点时,就把这个点加入序列中, 最后返回到根节点后也把根节点加入这个序列中,这样就定义了一个与 dfs 一一对应的搜索序列!而且这个 搜索序列,也是所有点的一个排列。
对于一棵有根树(结点标号 1 到 n,以 1 为根),咕咕对它跑了一遍 dfs 得到了搜索序列后,它准备把这个序 列抄在纸上拿给咸鱼看。但是,粗心的咕咕在抄这个序列的时候,一些点被它忽略了,纸上的序列只有 m 个 点。待咸鱼看到纸上这个序列后,咸鱼就很好奇:咕咕那么粗心,只是抄少了点这么简单吗,会不会同时把 一些点的位置也给变化了呢?
现在,聪明的你,你能判断出来咕咕在抄的时候有没有把点的位置变化了吗?也就是说,咕咕给的 m 个点的 序列,真的能够由一个 dfs 得到的搜索序列删除几个点后得到吗?输入
第一行一个整数 T(1≤ T ≤106),表示有 T 组数据。
对于每组数据:
第一行有两个正整数 n 和 m(1≤m≤n≤106),表示树的点数和咕咕给的序列的点数。
第二行有 n−1 个正整数 a1,a2,··· ,an−1(1≤ ai ≤i),表示点 ai 是点 (i+1) 的父结点。
第三行有 m 个互不相同的正整数,b1,b2,··· ,bm(1≤bi ≤n),表示咕咕给的序列。
输入保证同一个测试点下的所有数据的 n 的和不超过 106。输出
对每一组数据,输出一行。如果一定不能得到,输出 BAD GUGU ;否则输出 NOT BAD 。
样例输入 Copy
2 4 4 1 1 2 3 4 2 1 4 2 1 1 2 2 4样例输出 Copy
NOT BAD BAD GUGU
直接按照dfs顺序删掉不可能再次访问到的点即可。
比如说下图
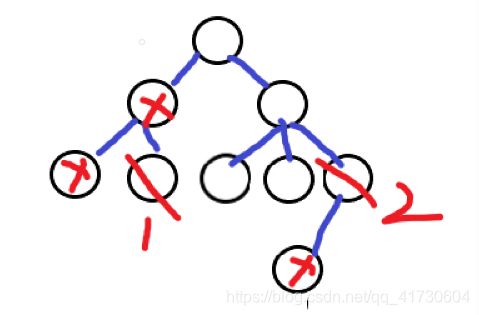
第一次访问的1,那么直接把1以及1的子树的所有删除即可(虽然没有子树),第二次删的是2,那么删掉2以及2的子树,以及
lca(1,2)的1所在的子树的所有节点。
也就是说,要维护一个last(上一次删的点),每次删要删除上述的节点。
关键在如何lca,如果倍增的话,栈开的空间就会爆内存,
而最后大家告诉我,直接暴力就行,平均下来lca的复杂度只有O(1),没毛病,上升的越多,删的也越多,()
卡我MLE是真的难受了,慎用倍增或RMQ求lca.....
这题时间和空间都卡的正好,,
#include
using namespace std;
#define LL long long
#define mod 1000000007
const int max_n=1e6+5;
vector g[max_n]; //父亲指向儿子
int root=1;
int par[max_n];//父亲
int de[max_n];//深度,根为0
bool vis[max_n];
void dfs(int v,int p,int d){ //处理de和par
par[v]=p;de[v]=d;
for(int i=0;ide[v])u=par[u];
while(de[v]>de[u])v=par[v];
while(u!=v){u=par[u];v=par[v];}
return u;
}*/
int lca(int u,int v){
int cc=0,tv=v;
while(de[u]>de[v]){u=par[u];}
while(de[v]>de[u]){v=par[v];cc++;}
while(u!=v){u=par[u];v=par[v];cc++;}
cc--;
while(cc-->0){
tv=par[tv];
}
return tv;
}
void deldfs(int u){
vis[u]=1;
for(int i=0;i>n>>m;
for(int i=2;i<=n;i++) {int x;scanf("%d",&x);g[x].push_back(i);}
init();
int last=0,ans=1;
while(m--){
int q;scanf("%d",&q);
if(vis[q])ans=0;
del(q,last);
last =q;
}
if(ans) cout<<"NOT BAD"< 还有zzq赛后补的I:https://www.cnblogs.com/zzqc/p/10704290.html
速学主席树后补C(气了):4.15:C来了 https://blog.csdn.net/qq_41730604/article/details/89321497
4.16:J来了(网络流)https://blog.csdn.net/qq_41730604/article/details/89340188
int a=1.不要一起看一题太久.....双开稳
int a=2.多见见题型,或许就不会卡在自己不可能做的题上
int a=3.想清楚再交流
int a=4.如何保证早起,且没胃口吃午饭的时候精力充沛,脑子不卡顿?
int a=5.如何跟榜??
int a=6.题目都挺好,就是为啥4题是树?蚂蚁森林?
int a=7.面包好吃
int a=8.zzuJuJu好强
int a=9.不到最后一刻,不放弃
int a=10.继续努力,省赛加油!