Intel汇编语言程序设计学习-第三章 汇编语言基础-下
3.4 定义数据
3.4.1 内部数据类型
MASM定义了多种内部数据类型,每种数据类型都描述了该模型的变量和表达式的取值集合。数据类型的基本特征是以数据位的数目量的大小:8,16,32,,48,64,80位。其他特征(如有符号、指针、浮点等)主要是为了方便程序员记忆变量中存储的数据的类型。例如,声明为DOWRD变量逻辑上存储的是一个32位整数、一个32位的浮点数或一个32位的指针。MASM汇编器默认情况下是大小写不敏感的,因此伪指令如DWORD可写成dword,Dword.dWord等大小写混合的格式。
下表中,除了最后三种之外,其余的所有的数据类型都是整数数据类型。表中IEEE符号是指IEEE委员会发布的标准实数格式。

3.4.2 数据定义语句
在数据定义语句中使用BYTE(定义字节)和SBYTE(定义有符号字节)伪指令,可以为一个或多个有符号及无符号字节分配存储空间,每个初始值必须是8位整数表达式或者字符常量。例如:
value1 BYTE ‘A’ ;字符常量
value2 BYTE 0 ;最小无符号字节常量
value3 BYTE 255 ;最大无符号字节常量
value4 SBYTE -128 ;最小有符号字节常量
value5 SBYTE +127 ;最大有符号字节常量
使用问号代替初始值可以定义未初始化的变量,这表示将由可执行指令在运行时为变量动态赋值:
value6 BYTE ?
可选的变量名是一个标号,标记该变量相对其所在段开始的偏移。例如,假设value1位于数据段的偏移0000出并占用1个字节的存储空间,那么value2将位于段内偏移值0001的地方:
value1 BYTE 10h
value2 BYTE 20h
遗留的DB伪指令可以定义有符号或无符号的8位的变量:
val1 DB 255 ;无符号字节
val2 DB -128 ;有符号字节
多个初始值
如果一条数据定义语句中有多个初始值,那么标号(名字)仅仅代表第一个初始值的偏移。在下列中,假设list位于偏移0000处,那么值10将位于0000处值20位于0001处,一次类推。
list BYTE 10,20,30,40
下图以字节序列的形式显示了list的定义情况:

并非所有的数据定义都需要标号(名字),如果想继续以list开始的字节数组,就可以在随后的行上接着定义其他数据:
list BYTE 10,20,30,40
BYTE 50,60,70,80
BYTE 81,82,83,84
在单条数据定义语句中,初始值可使用不同的基数,字符和字符串课可以自由混用。在下面例子中,list1和list2的内容是相同的。
list1 BYTE 10 ,32 ,41h ,00100010b
list2 BYTE 0Ah,20h,’A’ ,22h
定义字符串
要想定义字符串,应将一组字符用单引号或双引号括起来。最常见的字符串是以空字符(也称为NULL,0)结尾的字符串,C/C++,Java程序使用这种类型的字符串:
greeting1 BYTE "Good afternoon",0
greeting2 BYTE 'Good night',0
每个字节都占用一个字节,对于前面提到过的数据定义中多个初始值必须以逗号分隔的规则,字符串是一个例外。如果没有这种例外,就不得不这样定义greeting1:
greeting1 BYTE ‘G’,’o’,’o’....etc.
这样太冗长乏味了!
字符串可以占用多行,而无需为每一行都提供一个标号,如下例所示:

十六进制字节0Dh和0Ah也称为CR/LF(回车换行符)或航结束字符,在向标准输出设备上写的时候,回车换行将光标移至下面一行左右开始处。
续行符(\)用来把两行连接陈过一条程序语句,续行符只能放在每行的最后,下面的语句是等价的:
greeting1 BYTE "Good afternoon",0
greeting1 BYTE \
"Good afternoon",0
DUP操作符
DUP操作符使用一个常量表达式作为计数器为多个数据项分配存储空间。在为字符串和数组分配空间的时候,DUP伪指令就十分有用。初始化和未初始化数据均可使用DPU伪代码定义:
BYTE 20 DUP(0) ;20字节,全部等于0
BYTE 20 DUP(?) ;20字节,未初始化
BYTE 4 DUP("STACK") ;20字节:"STACKSTACKSTACK"
3.4.4 定义WORD和SWORD数据
和BYTE一样,这里就简单写几个例子。
word1 WORD 65535
word2 SWORD -32768
word2 WORD ?
val1 DW 65535
val2 DW -32768
myList WORD 1,2,3,4,5

3.4.5 定义DWORD和SDWORD数据
和BYTE一样,直接上例子
val1 DWORD 13245678h
val2 SDWORD -2147483684
val3 DWORD 20 DUP(?)
val1 DD 12345678h
val2 DD -2147483648
myList DWORD 1,2,3,4,5

3.4.6 定义QWORD数据
quad1 QWORD 1234567812345678h
quad1 DQ 1234567812345678h
3.4.7 定义TBYTE数据
val1 TBYTE 100000000000000123456789Ah
val1 DT 100000000000000123456789Ah
3.4.8 定义实数
REAL4定义4字节的单精度实数,REAL8定义8字节的双精度实数,REAL10定义10字节的扩展精度实数。每个伪指令都要求一个或多个与其对应的数据尺寸相匹配的实数常量初始值,例如:
rVal1 REAL4 -2.1
rVal2 REAL8 3.2E-260
rVal3 REAL10 4.6E+4096
ShortArray REAL4 20 DUP(0.0)
下表列出了每种实数类型的最少有小数据位和最大有效数据位

遗留的DD,DQ和DT伪指令也可以用于定义实数:
rVal1 DD -1.2
rVal2 DQ 3.2E-260
rVal3 DT 4.6E+4096
3.4.9 小尾顺序
Intel处理器使用称为小尾顺序(little endian order)的方案存取内存数据,小尾的含义就是变量的最低有效字节存储在地址值最小的地址单元中,其余字节在内存中按顺序连续存储。
考虑一下双字节12345678h在内存中的存储情况,如果将该双字存储在偏移0处,78h将存储在第一个字节中,56h存储在第二个字节中,其余存储在第三和第四字节。如下图:

大尾则相反:

3.4.10 为AddSub程序添加变量
现在写一个AddSub2,在里面添加一些变量:
TITLE Add and Subtract ,Version 2 (AddSub2.asm)
;This program adds and subtracts 32-bit unsigned
;integers and stores the sum in a variable
INCLUDE Irvine32.inc
.data
val1 DWORD 10000h
val2 DWORD 40000h
val3 DWORD 20000h
finalVal DWORD ?
.code
main PROC
mov eax,val1 ;start whith 10000h
add eax,val2 ;add 40000h
sub eax,val3 ;subtract 20000h
mov finalVal,eax;store the result (30000h)
call DumpRegs ;display the registers
exit
main ENDP
END main
这个新的程序是如何工作的呢?首先,变量val1里的整数倍送到EAX寄存器:
mov eax,val1 ;start with 10000h
接下来,变量val2存储的整数值被加到EAX寄存器中:
add eax,val2 ;add 40000h
再接下来,EAX寄存器内的整数值减掉变量val3内的整数值:
sub eax,val3 ;subtract 20000h
最后,EAX寄存器内的整数被复制到变量finalVal内:
Mov finalVal,eax ;store the result(30000h)
3.4.11 未初始化数据的声明
“.DATA?”伪指令可用于声明未初始化数据,”.DATA?”在定义大块的未初始化数据时非常有用,因为它可以减少编译后的程序的尺寸,下面的声明是很有效率的:
.data
smallArray DWORD 10 DUP(0) ;40字节
.data?
bigArray DWORD 5000 DUP(?) ;20000字节,未初始化
相反,下面的代码例子编译后将生成大于20000字节的程序:
.data
smallArray DWORD 10 DUP(0) ;40字节
bigArray DWORD 5000 DUP(?) ;20000字节,未初始化
我自己做了个测试,发现果真有效果,除了上面的数据定义,其他配置选项或者是代码完全一样,下面是结果:

我的天!差距还真是大。
混合代码和数据:汇编器允许程序在代码和数据之间来回切换。在定义仅在局部程序中使用的变量时,这是非常方便的。下面的例子在两端代码中直接插入并创建一个名为temp的变量:
.code
mov eax,ebx
.data
temp DWORD ?
.code
mov temp,eax
3.5 符号常量
符号常量(或符号定义)是通过将标示符(或符号)与整数表达式或文本联系起来而创建的。与保留存储空间的变量定义不同,符号常量并不占用任何实际的存储空间。符号常量仅在编译期间汇编器扫描程序的时候使用,在运行期间不能更改。下表总结了二者的区别:
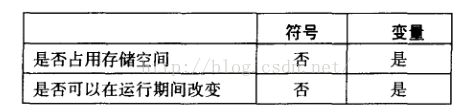
接下来讲述如何使用等号伪指令(=)来创建代表整数表达式的符号常量,之后,还将讲述如何使用EQU和TEXTEQU伪指令创建可代表任意文本的符号常量。
3.5.1 等号伪指令
等号伪指令将符号名和整数表达式联系起来。格式如下:
名字=表达式
通常,表达式(expression)是32位的整数值,汇编程序的时候,所有出现名字(name)的地方都由汇编器在预处理阶段替换为对应表达式的值。例如,当编译器遇到下列语句的时候:
COUNT = 500
mov ax,COUNT
将生成并编译下面的语句:
mov ax,500
为什么要使用符号:跟C++的宏有点像(但不是,=号后面只能是表达式),改一个可以全改。
键值的定义:程序中经常要为重要的键盘字符定义符号,例如27是Esc键的ASCII码值:
Esc_key = 27
这样在同一程序中,如果语句中使用了这个符号而不是一个立即数,那么语句的额含义就不言自明了。例如,应该使用下面的语句:
mov al,Esc_key ;好的风格
而不是:
mov al,27 ;不好的风格
使用DUP操作符:3.4.3节讲述了如何使用DUP操作符为数组和字符串分配存储空间。好的编程风格是使用符号常量作为DUP操作符的计数器,以简化程序的维护。在下例中,如果COUNT已经预先定义,那么就可以用在下面的数据定义中:
array COUNT DUP(0)
重定义:同一程序中以”=”定义的符号可重定义。下面展示了在每次改变COUNT值时编译器是如何对其进行求值的:
COUNT = 5
mov al,COUNT ;AL = 5
COUNT = 10
mov al,COUNT ;Al = 10
COUNT = 100
mov al,COUNT ;Al = 100
行号(如COUNT)值的改变与运行时语句执行的顺序无关,相反符号值是按照汇编器对源代码的顺序处理进行改变的。
3.5.2 计算数组和字符串的大小
使用数组的时候,有时候需要知道数组的大小。下列使用一个名为listSize的常量声明数组list的大小:
list BYTE 10,20,30,40
ListSize = 43
在数组可能会改变大小的时候,手动计算其大小并不是一个好主意。如果要为list添加几个字节,就需要同时修正ListSize。处理这种情况讲好的办法是让编译器自动为我们计算ListSIze的值。MASM用($)减掉list的地址偏移值就得到了ListSize值(4):
list BYTE 10,20,30,40
ListSize = ($ - list)
ListSize必须紧跟在list之后。例如,下例中ListSize的值过大,这是因为ListSize包括了var2占用的存储空间:(24)
List BYTE 10,20,30,40
var2 BYTE 20 DUP(?)
ListSize = ($ - list)
与其手动计算字符串的长度,不如让编译器自动做这种工作:(57)
myString BYTE "This is a long string, containing"
BYTE "any number of characters"
myString_len = ($ - myString)
字数组和双字数组:如果数组的每个元素都是16位的字,以字节计算的数组长度必须初一2才能得到数组元素的个数(4)
list WORD 100h ,200h ,300h ,400h
ListSize = ($ - list) / 2
与此类推,双字数组的呢个元素时4字节长的,因此/4 (3)
list DWORD 100000h ,200000h,300000h
ListSize = ($ - list) / 4
3.5.3 EQU伪指令
EQU伪指令将符号名同整数表达式或任意文本联系起来,有一下三种格式:
name EQU expression
name EQU symbol
name EQU
在第一种格式中,表达式(expression)必须是有效的整数表达式;在第二种格式中,符号(synbol)必须是已经=或EQU定义的符号名;第三种格式中,尖括号内可以是任意文本。当汇编器在后面遇到已经定义的 “名字”(name)时,就用改名字代表的整数值或文本替代。当定义任何非整数值的时候,EQU就可能非常有用了,例如实数常量就可以用EQU定义:
P1 EQU <3.1416>
例子:下列把一个符号同一个字符串联系了起来,然后使用该符号创建了一个变量:
pressKey EQU <”Press any key to continue...”,0>
.
.
.data
pronpt BYTE pressKey
再来一个例子:
matrix1 EQU 10*10
matrix2 EQU <10*10>
.data
M1 WORD matrix1
M2 WORD matrix2
汇编器为M1和M2生成不同的数据定义,martix1中的整数表达式被计算并赋给M1,而matrix2内的文本将直接复制到M2的数据定义中,实际的等效语句是:
M1 WORD 100
M2 WORD 10*10
不允许重定义:与”=”伪指令不同,用EQU定义的符号不能再同一源代码文件中重定义,这个限制能够防止已存在的符号被无意中赋了新值。
3.5.4 TEXTEQU伪指令
TEXTEQU伪指令与EQU非常相似,也可用来创建文本宏(text macro)。它有三种不同的使用格式:第一种格式将文本赋给符号;第二种格式将已定义的文本宏内容赋给符号;第三种格式将整数表达式常量赋给符号。
name TEXTEQU
name TEXTEQU textmacro
name TEXTEQU %constExpr
例如,prompt1变量使用了continueMsg文本宏:
continueMsg TEXTEQU <”Do you wish to continue (Y/N)?”>
.data
Prompt1 BYTE continueMsg
可用文本宏方便地创建其他的文本宏。在下例中,count被设置为包含宏rowSize的整数表达式的值,接下来符号move被定义为mov,setupAL则由move和count共同创建:
rowSize=5
count TEXTEQU %(rowSize*2)
move TEXTEQU
setupAL TEXTEQU
因此下面的语句:
setupAl
将被汇编成
mov al,10
与EQU伪指令不同的是,TEXTEQU可以在程序中重新定义。
3.6 实地址模式程序设计(可选)
为MS-DOS设计的程序必须是云心更是低至模式下的16位应用。实地址模式应用程序使用16位的段并且遵循2.3.1节描述的分段寻址方案。如果使用的是IA-32处理器,则仍然可以使用32位通用寄存器存取数据。
3.6.1 基本的修改
将本章中的32位程序转换成实地址模式程序,需要做一些修改:
INCLUDE伪指令要引用另外一个不同的库文件:
INCLUDE Irvine16.inc
在启动过程(main)的开始插入两条额外的指令,这两条指令将DS寄存器初始化为数据段的其实地址,数据段的其实地址用MASM的预定义常量@data表示:
mov ax ,@data
mov ds,ax
如何汇编16位程序的步骤请参见www.asmirvine.com
数据标号和代码标号的偏移(地址)是16位而不是32位。
不能把@data直接送DS和ES寄存器,因为MOV指令不允许直接向段寄存器传送常量;
实地址AddSub程序:
INCLUDE Irvine16.inc ;changed
.data
val1 DWORD 10000h
val2 DWORD 40000h
val3 DWORD 20000h
finalVal DWORD ?
.code
main PROC
mov ax,@data ;new
mov ds,ax ;new
mov eax,val1
add eax,val2
sub eax,val3
mov finalVal,eax
call DumpRegs
exit
main ENDP
END main
PS:这个我本机没有编过,我的环境是vs2012+masm32 debug模式。不查了,用到的时候再说吧,实地址模式我几乎用不上。
3.7 本章小结

