MySQL集群笔记(读写分离、MyCat、负载均衡、PXC)
视频教程传送门 -> MySQL集群解决方案(主从复制、PXC集群、MyCat、HAProxy)https://www.bilibili.com/video/BV1R4411s7zi
目录
MySQL数据库的集群方案
读写分离(主从复制)架构
MyCat数据库中间件
HAProxy负载均衡
PXC集群的使用
多种集群架构综合应用
1. MySQL数据库的集群方案
相对于单节点DB Server,集群可以应对大并发、海量数据存储等问题。下文以MySQL数据库为例。
一般应用对数据库是“读多写少”,思路=> 采用数据库集群方案读写分离
其中一个是主库,负责写入数据 -> 写库
其它都是从库,负责读取数据 -> 从库
需要遵循,
1)读库和写库数据一致
2)写数据必须到写库
3)读数据必须到读库
1.1 架构
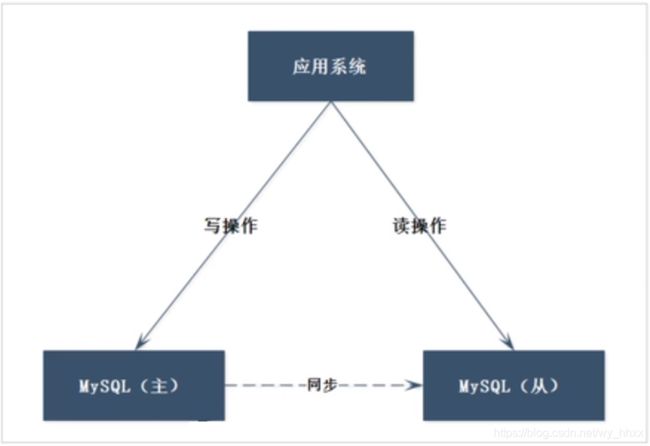
说明:
数据库从单节点变为多节点提供服务
主节点数据同步到从节点(实际可有多个从节点)
应用程序需要连到2个数据库节点,并在程序内部实现判断读写操作
该架构存在的问题:
1)应用程序需要连接到多个节点,对应用程序而言开发变得复杂
解决:中间件;程序内部使用Spring的AOP功能实现
2)主从之间的同步,是异步完成 => 弱一致性
存在数据写入主库后应用程序读取从库获取不到数据的情况,且可能丢失数据 =>不适合对数据安全要求较高的应用
解决:PXC集群
1.2 中间件

说明:
应用程序无需连接到多个数据节点,连接到中间件即可
应用程序无需区分读写操作,对中间件直接进行读写操作即可
在中间件区分读写操作,读发送到从节点,写发送到主节点
该架构存在的问题:中间件的性能成为了系统的瓶颈
解决:中间件做集群

中间件的可靠性得到了保证,但也带来了新的问题,应用系统需要连接到两个中间件增加了复杂度
解决:负载均衡
1.3 负载均衡
在应用程序和中间件之间增加proxy代理
由代理来完成负载均衡的功能,应用程序只需对接到proxy即可
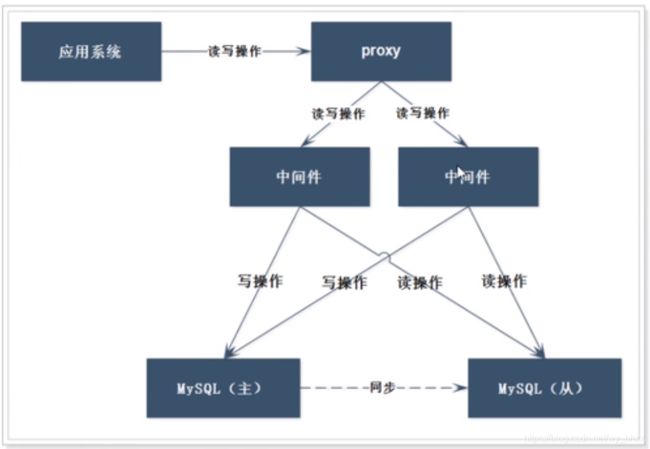
1.4 PXC集群架构
前述的架构都是基于MySQL主从架构,问题:弱一致性
有的场景,如交易数据,需要强一致性
解决:PXC提供了读写强一致性的功能,可以保证数据在任何一个节点写入的同时可以同步到其它节点
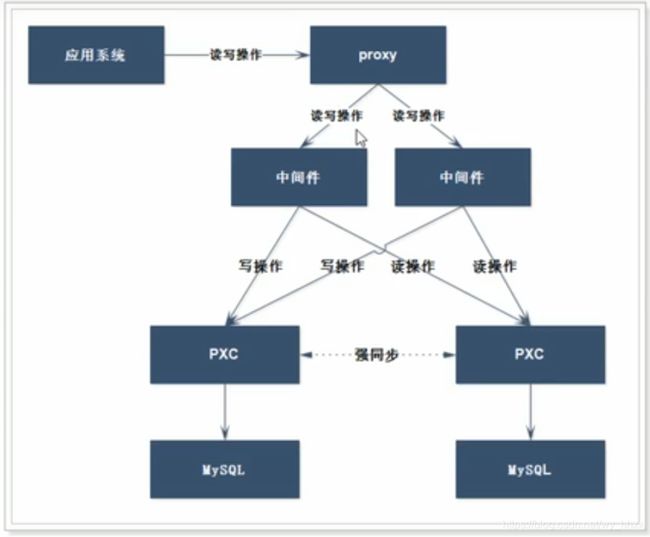
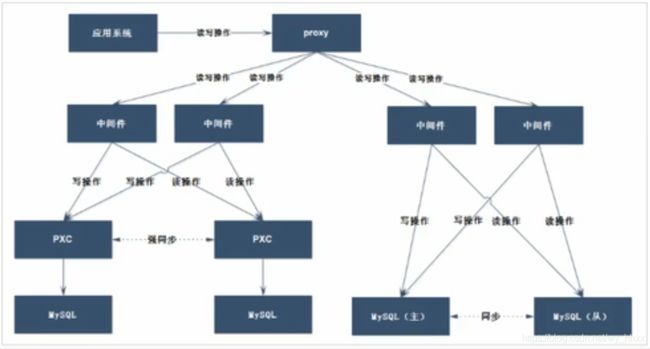
1.5 混合架构
在PXC架构中,实现了事务的强一致性,但是牺牲了性能
如果在某些业务的场景下没有强一致性的需求,使用PXC不合适
因此可以将读写分离和PXC综合起来,如下
2. 主从复制(读写分离)架构
环境说明:使用docker,MySQL使用衍生版Percona(版本5.7.23);所有应用启动在一台服务器,所以有的地方需要修改端口
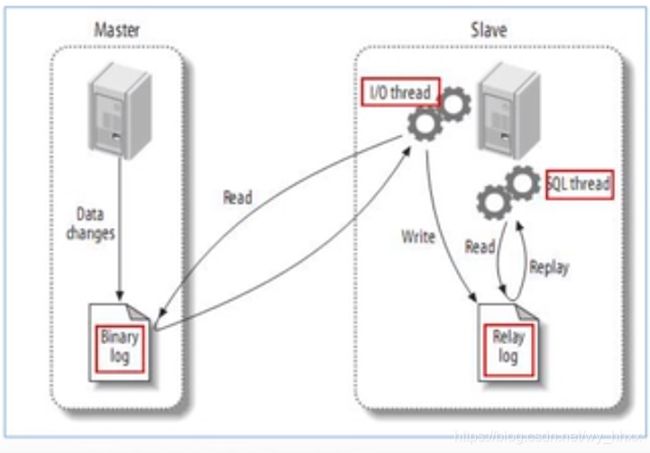
2.1 主从复制原理
master将数据改变记录到二进制日志(binary log)中,这些记录叫做binary log events
slave将master的binary log events拷贝到它的中继日志(relay log)
slave重做中继日志中的事件
主从配置需要注意的地方:
1)主数据库和从数据库的版本一致
2)主数据库和从数据库数据一致
3)主数据库开启二进制日志
4)主数据库和从数据库的server_id都必须唯一
2.2 主库配置文件my.conf
编辑主库my.cnf
#开启主从复制
log-bin=mysql-bin
#指定主库server-id
server-id=1
#指定同步的数据库,如果不指定则同步全部数据库
binlog-do-db=my_test执行SQL语句查询主库状态:SHOW MASTER STATUS
2.3 在主库创建同步用户
主库执行如下语句
#授权用户slave01使用密码123456登录MySQL
grant replication slave on *.* to 'slave01'@'127.0.0.1' identified by '123456';
#刷新配置
flush privileges;
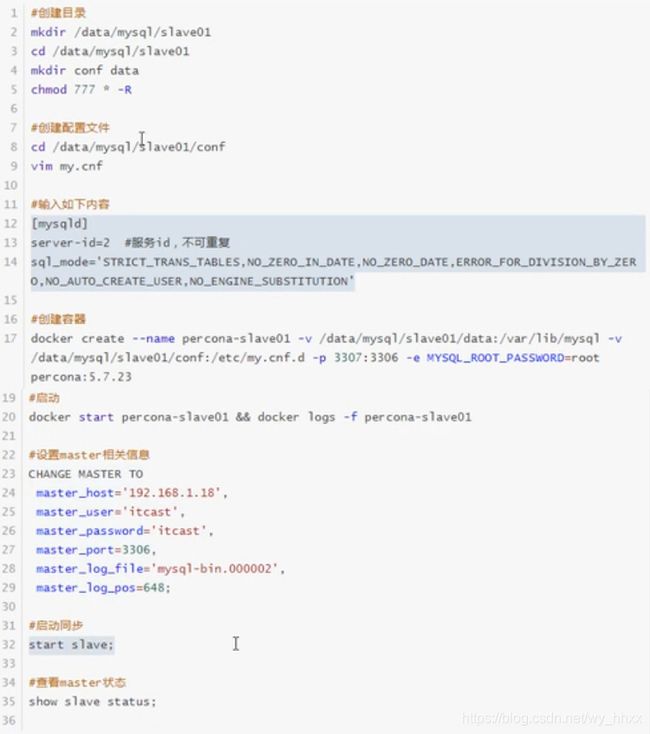
2.4 从库配置文件my.conf
编辑从库my.conf
#指定server-id,不重复即可
server-id=2执行以下SQL语句
CHANGE MASTER TO
master_host='127.0.0.1',
master_user='slave01',
master_password='123456',
master_port=3306,
master_log_file='mysql-bin.000006', #通过SHOW MASTER STATUS;查询
master_log_pos=1120; #通过SHOW MASTER STATUS;查询启动slave同步:START SLAVE;
查看同步状态:SHOW SLAVE STATUS;
2.5 搭建主库

2.6 搭建从库
@关于binlog_format
MySQL提供3种模式
1)基于SQL语句的复制(statement-based replication,SBR)
2)基于行的复制(row-based replication,RBR)
3)混合模式复制(mixed-based replication,MBR)
binlog的模式也有三种:STATEMENT、ROW(默认)、MIXED(建议使用)
STATEMENT(SBR)
每一条修改数据的SQL语句都会记录到binlog中
优点:不需要记录每一条SQL语句和每一行的数据变化,减少binlog日志量,节约IO,提高性能
缺点:某些情况会导致master-slave中的数据不一致,如SELECT NOW()
ROW(RBR)
不记录每条SQL语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了
会产生大量日志,尤其是ALTER TABLE(在已有的表中添加、修改或删除列)的时候会让日志暴涨
MIXED(MBR)
以上两种模式的混合使用,
一般的复制使用STATEMENT模式保存binlog
对于STATEMENT模式无法复制的操作使用ROW模式保存binlog
MySQL会根据执行的SQL语句选择日志保存方式
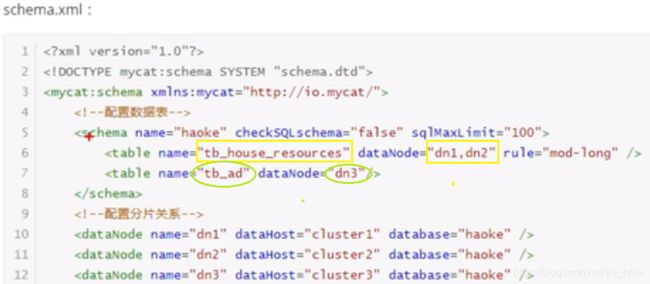
3. MyCat中间件
3.1 读写分离
MySQL服务部署举例
| 主机 | 端口 | 容器名称 | 角色 |
| 192.168.1.18 | 3306 | percona-master01 | master |
| 192.168.1.18 | 3307 | percona-slave01 | slave |
step 1 编辑配置文件
(1)server.xml

(2)schema.xml

@balance属性说明
代表负载均衡类型,取值说明如下
balance="0" 不开启读写分离机制,所有读操作都发送到当前可用的writeHost上
balance="1" 全部的readHost与standby writeHost参与select语句的负载均衡
即双主从模式(M1->S1,M2->S2,并且M1和M2互为主备),M2,S1,S2都参与select语句的负载均衡
balance="2" 所有读操作都随机地在writeHost、readHost上分发
balance="3" 所有读操作随机地分发到writeHost对应地readHost执行,writeHost不负担读压力
(3) rule.xml,因为只有一个MySQL集群,这里count保持为1

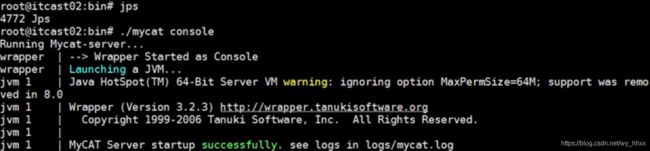
step 2 启动MyCat
先使用命令./mycat console测试,如果显示successfully就没问题,再用命令./startup_nowrap.sh启动
step3 连接Mycat
默认端口8806,可以再配置文件server.xml中修改
@搭建多节点MyCat
以上是搭建单节点MyCat步骤,如果需要搭建多节点MyCat参考如下
注:因为放在一台服务器,所以需要设置不同端口

3.2 数据分片
MySQL服务部署举例
MySQL集群1
| 主机 | 端口 | 容器名称 | 角色 |
| 192.168.1.18 | 3306 | percona-master01 | master |
| 192.168.1.18 | 3307 | percona-slave01 | slave |
MySQL集群2
| 主机 | 端口 | 容器名称 | 角色 |
| 192.168.1.18 | 3316 | percona-master02 | master |
| 192.168.1.18 | 3317 | percona-slave02 | slave |
step 1 修改配置文件
配置schema.xml

配置rule.xml,因为有两个MySQL集群,count设置为2
2
4. HAProxy负载均衡
官网:http://www.haproxy.org
4.1 部署安装HAProxy
拉取镜像
docker pull haproxy:1.9.3
创建目录,用于存放配置文件
mkdir /test/haproxy
创建容器
docker create --name haproxy --net host -v /test/haproxy:/usr/local/etc/haproxy haproxy:1.9.3
编辑配置文件
vim /test/haproxy/haproxy.cfg

可以根据以上配置打开URL查看MyCat状态(如下,绿色为正常运行)
5.PXC集群的使用
Percona XtraDB Cluster(PXC)是针对MySQL用户高可用性地扩展性解决方案,基于Percona Server。
Percona Server是MySQL的改进版本,使用XtraDB存储引擎,提升了在高负载情况下的InnoDB的性能,另外有更多的参数和命令来控制服务器行为。
PXC提供了,
同步复制,事务可以在所有节点上提交
多主机复制,可以写到任意节点
从(slave)服务器上的并行应用事件,真正地并行复制
自动节点配置
数据一致性,不再有位同步地从服务器
5.1 部署安装
部署三节点PXC举例
| 节点 | 端口 | 容器名称 | 数据卷 |
| node1 | 13306 | pxc_node1 | v1 |
| node2 | 13307 | pxc_node2 | v2 |
| node3 | 13308 | pxc_node3 | v3 |
具体步骤如下
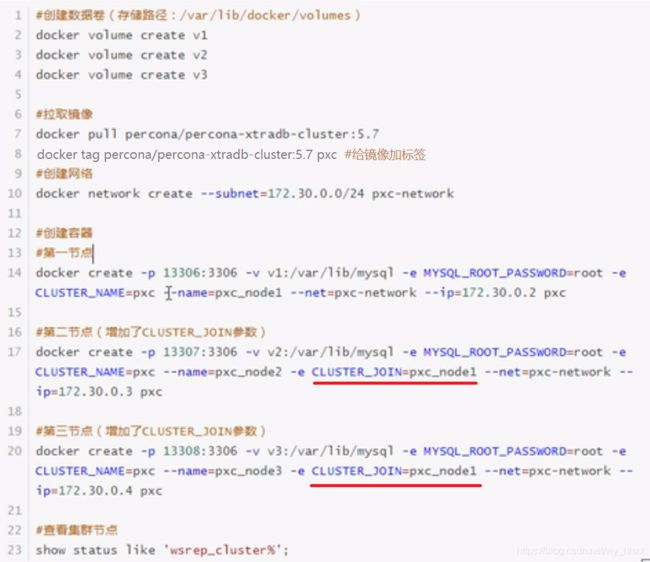
注意:先启动第一个节点,等mysql客户端可以连接到服务后再启动其它节点。
5.2 集群的说明
尽可能控制PXC集群规模,节点越多,数据同步速度越慢
所有PXC节点地硬件配置要一致,如果不一致,配置低地节点将拖慢数据同步速度
PXC集群只支持InnoDB引擎,不支持其它地存储引擎
@PXC集群方案与Replication区别
| PXC | Replication |
| 所有节点都是可读可写的 | 从节点不能写入,因为主从同步是单向的 |
| 同步机制是同步进行的 | 同步机制是异步进行的 |
| 牺牲性能保证数据的一致性 | 性能上高于PXC |
| 用于重要信息的存储,例如:订单、用户信息等 | 用于一般信息的存储,能够容忍数据丢失,例如:购物车、用户行为日志等 |
6.多种集群架构综合应用
6.1 架构
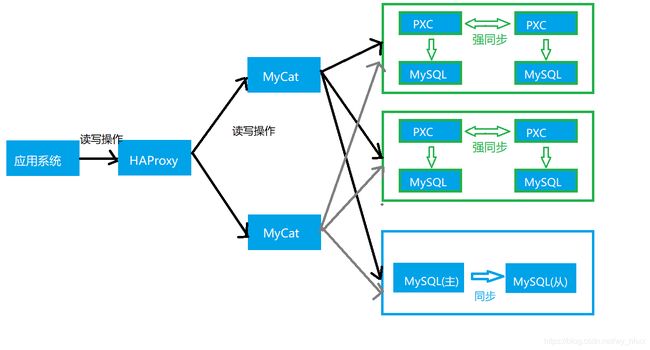
说明:
HAProxy作为负载均衡器
部署了2个MyCat节点作为数据库中间件
部署了2个PXC集群节点,作为2个 MyCat分片,每个PXC集群中有2个节点,作为数据的同步存储
房源数据保存到PXC分片中,其余数据如广告保存到主从架构中(按表区分)
配置可以参考前述,需注意:
1)schema.xml文件前两个集群(PXC)balance设置为2 -> 读操作随机到在writeHost、readHost),第三个集群(主从)balance设置为3 -> 读操作随机到writeHost对应地readHost执行,writeHost不负担读压力。
2)schema.xml指定表给PXC或主从架构