python基础学习
py文件运行:
先进入py文件的目录,python3版本执行语句:py -3 demo.py
python2版本执行语句(python默认为python2):python demo.py
pycharm代码优化:ctrl+alt+l
pycharm执行:ctrl+shift+f10
python中" // "来表示整数除法,返回不大于结果的一个最大的整数
eg:2//4 = 0, 6//3 = 2
print(str[2:5])# 输出从第三个开始到第五个的字符(不包含第五个字符)
string(不可以被修改)可以看做是一种特殊的元组
list元素写在[]中,元素可以被修改(内置append()、pop()方法)
tuple元素写在()中,元素不可以被修改
string、list和tuple都属于sequence(序列)->有序(支持索引)
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表:tup = (["aaa",123],["bbb",123],123)
集合(set)是一个无序不重复元素的序列:可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
字典是无序的对象集合
set和dictionary->无序(不支持索引)eg:set1 = {"agg", 1, "ooo"} set1[0]="aaa"是错的
可变类型和不可变类型解释:http://www.runoob.com/python3/python3-function.html
可变数据类型:列表list,字典dict和集合set;
不可变数据类型:整型int、浮点型float、字符串型string、元组tuple。
字符串、元组、(因为不可变)、集合set(因为不可索引)不能给其中一个元素重新赋值
元组能够拼接,但只能是两个元组进行拼接,不能tup+‘aaa’( tup=(1,2,'adf') )
字符串可以拼接,包括两个字符串拼接,以及string+‘aaa’(string = 'adf')
列表可以拼接,包括两个列表拼接,以及list +=["aaa"]或者list += "aaa",前者结果多了一个'aaa',后者多了三个‘a’
集合set拼接,可以用add函数,不支持+=操作
字典目前没有拼接的方法
“python中的不可变数据类型,不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象,内部会有一个引用计数来记录有多少个变量引用这个对象;可变数据类型,允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。”
对于不可变对象来说,eg:a=[1,123,44,'hh'](此时没有__iadd__()方法)
a+=[3]和a=a+[3]涵义是一样的,都相当于a被重新赋值,即a指向了一个新的对象,原对象不修改
对于可变对象来说,(前者等价于a.__iadd__([3]),后者相当于a.__iadd__([3]))
a+=[3]和a=a+[3]涵义不一样,前者直接在原对象a上进行更新,该方法的返回值为None;对于后者,相当于a被重新赋值,即a指向了一个新的对象,原对象不修改。
b = a(eg:a=[1,123,44,'hh'])
a和b指向同一个内存空间,此时a is b和a==b都是对的(a is b等价于id(a)==id(B))
b = a[:]
a和b指向不用内存空间,但是值是一样的,此时,a is b是错的,而a==b是对的
is 用于判断两个变量引用对象是否为同一个, == 用于判断引用变量的值是否相等。
<>:表示不等于运算符
del语句:可以删除单个或多个对象的引用
a = 10
del a
复数( (complex)) - 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
Python 解释器可以作为一个简单的计算器,您可以在解释器里输入一个表达式,它将输出表达式的值。
在交互模式中,最后被输出的表达式结果被赋值给变量 _:
>>> tax = 12.5 / 100 >>> price = 100.50 >>> price * tax 12.5625 >>> price + _ 113.0625 >>> round(_, 2) 113.06a = "hello"
a[1:4] = ell(这样截取会取到第四个之前的值,不包括第四个值)
ASC码:一个字符是一个字节,用8位二进制来表示(为了便于我们看,会将二进制转换为十进制给我们看),一共能表示2的8次方,即256个字符
能表示的最大的十进制数是127(有符号八位二进制)或者255(无符号八位二进制数) 一般用来表示英文
Unicode:一个字符用16位表示(两个字节:一个中文字),能表示更多的字符 所以可以表示更多的国家语言
GBK 编码主要用来表示中文
UTF-8:应该是Unicode的扩展,是可变长度字符编码(可用8/16位...或其它位数的二进制来表示)
考虑各种编码是否能兼容就可以。
在Python3中,所有的字符串都是Unicode字符串。(python编程中每一个字符在电脑中用16位的二进制来表示)
python3:用print(x, end='')表示不换行
python2:用print x,表示不换行(for x in [1, 123] print x)
可以使用 del 语句来删除列表或者列表的元素,eg:del list 或者 del list[0]
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,eg:del tup
可以使用 del 语句来删除字典或者字典的元素,eg: del dictionary或者del dictionary['aaa'] dictionary = {'aaa':123} dictionary.clear(): 清空字典中元素,但是字典不存在了 而del dictionary:字典将会不存在
L = ('Google','Taobao','Runoob')
L[-2]:读取倒数第二个元素,为‘TaoBao’而不是‘Google’
列表list、元组tup、集合set、字典dic均可称为容器(分不可变容器和可变容器,可变不可变上面有说)
python的浅拷贝:
python的深拷贝:
网址:http://www.runoob.com/python3/python3-att-dictionary-copy.html
http://www.runoob.com/w3cnote/python-understanding-dict-copy-shallow-or-deep.html
注:字典比较特殊,自我感觉每个key都是一个对象,它们都会在内存开辟属于自己的空间,它们的value(若是一个单个值)也会在内存另开辟空间存储这个value(key将指向它们各自的值);若它们的value(若是一个非单个值,eg:列表)则不会在内存开辟一个新空间,而是在key开辟的空间内存储value的引用,eg:该引用指向dic1中num所指的内存空间(此时的value引用指的是[1,2,3]的引用)
dict1 = {'user':'runoob','num':[1,2,3]}
dict2 = dict1# 浅拷贝: 引用对象
dict3 = dict1.copy()# 浅拷贝:深拷贝父对象(一级目录:包括所有的key值,如果key值对应的value是单个值,那么这个值也是深拷贝->另开辟一个新的空间存储这个value,此时没有所谓的子对象),子对象(二级目录:如果value是列表之类的含有多个值,那么这个value是浅拷贝,即和dic1的‘num’指向同一个内存空间,里面存的是[1,2,3])不拷贝,还是引用
# 修改 data 数据
dict1['user']='root'
dict1['num'].remove(1)
# 输出结果
print(dict1)
print(dict2)
print(dict3)
{'user': 'root', 'num': [2, 3]} {'user': 'root', 'num': [2, 3]} {'user': 'runoob', 'num': [2, 3]}代码块整体向右向左移动: 用快捷键Tab 向右,Shift+Tab 向左
int(input("输入一个数字:") ) input函数的输出是字符串,可用int()函数转成整型
while 表达式:
语句块
else:
语句块
for 变量 in list:
语句块
else:
语句块
if 表达式:
语句块
elif 表达式:
语句块
else:
语句块
pass 不做任何事情,一般用做占位语句(连空行也不占)
字符串,列表或元组对象以及字典(自己试过,用next()输出的是每个key值)都可用于创建迭代器;
在 python 中,类型属于对象,变量是没有类型的:
a = [1, 2, 3]
a = "Runoob"
以上代码中,[1,2,3] 是 List 类型,"Runoob" 是 String 类型,而变量 a 是没有类型,她仅仅是一个对象的引用(一个指针),可以是 List 类型对象,也可以指向 String 类型对象。
list = [1, 2, 333, 'aaa']
list.clear()
del list[:]
del list
前两个操作list还在,就是没有元素
后一个操作list已经不存在
对于自己写的模块:(包不仅能放在你现在执行的py同级目录下,还可以放在sys.path列表中的任意路径下)
引入模块中的所有东西(函数以及变量等):from 模块 import */函数名/变量名(这个模块可以与现在执行的py文件在同一个目录下,也可以放在sys.path列表中的任意一条路径下)
对于自己写的包(需要在包中创建一个空的_init_.py文件)/在pycharm中创建的包: (包只能放在你现在执行的py同级目录下)
引入包中所有模块:from 包 import 模块名(用*使用不了这个包下的模块中的函数和变量)(import 后不能导入某个模块下的某个具体函数/变量)(这个包一定要与你现在执行的py文件在同一个目录下,放在sys.path列表中的其他任意路径下是不可以的)
Python是:解释型语言,但带有一些编译型特征。CPython把Python源码编译成字节码,之后再解释这些字节码,执行之。
*注意:这个编译不是通常意义上的编译。通常我们说的编译,是指把高级语言代码转换成机器码。但这里实际上是一种种类的编译。(原文是it is a ‘compilation’ of sorts)
字节码 vs. 机器码
了解字节码和机器码(或者native code)的区别是很重要的,最好的办法或许是看看例子:
- C代码被编译成机器码,将在处理器上直接执行。每一条指令控制CPU工作。
- Java代码被编译成字节码,将在Java虚拟机(JVM)这个抽象的计算机上执行。每一条指令由JVM处理,JVM同计算机本身之间交互。
简而言之:机器码快的多,但字节码更易迁移,也更安全。
机器码随机器的变化而变化,但字节码在所有的机器上都是一样的。有人可能会认为机器码是对特定环境优化了的。
回到CPython,工具链的执行过程如下:
- CPython编译你的Python源代码,生成字节码(.pyc文件)。
2. 字节码随后在CPython虚拟机上执行。
初学者常常因为看到.pyc文件而假设Python是编译型的。这也有一些合理性:.pyc文件是之后要解释的字节码文件。所以,你若之前运行过你的Python代码,生成了.pyc文件,再次运行时就要快得多,因为不需要再次编译生成字节码了。
Python 本身带着一些标准的模块库,有些模块直接被构建/内置在解析器里(eg:sys模块),这些模块可以在python解释器中直接导入(import),不用管模块所在具体目录;而自己写的模块就不能在python解释器中直接导入,而是应该先定位到自己写的py模块的路径,在此路径下cmd,再进入python解释器,再导入自己的py模块。
默认的标准输入时键盘
派生类不能继承基类的私有属性
shutil.copyfile('c.txt','b.txt'):将c.txt内容复制到b.txt中(并覆盖b.txt中的内容)
shutil.move('a.txt','/home/335/zxj'):将a.txt移动到/home/335/zxj文件夹下
结果:'/home/335/zxj/a.txt'
小的py文件叫脚本,大的功能很强的py文件称为工具。
字符串前加r: 'r'是防止字符转义的
\b: 在正则中表示单词间隔
邮箱服务器端口号:一般的(163,qq)默认为25,若是自己搭建的服务器(比如某个公司),一般设置为25,当然也可以设置成别的端口号。
163第三方邮箱服务器地址:smtp.163.com(发邮件服务器)
pop.163.com(收邮件服务器)
常见邮件服务器(接收服务器和发送邮件服务器)地址: https://zhidao.baidu.com/question/580651951.html
from datetime import date中: datetime是模块,date是一个类
from timeit import Timer: timeit是模块,Timer是一个类
import 模块1[, 模块2[,...模块N]
from 模块 import 函数1,函数2...
from 模块 import* 把一个模块的所有内容全都导入到当前的命名空间
import 包.子包.模块 引用函数时:包.子包.模块.函数()
from 包.子包 import 模块 引用函数时: 模块.函数()
from 包.子包.模块 import 函数/变量 后面直接调用这个函数即可
u/U:表示unicode字符串
不是仅仅是针对中文, 可以针对任何的字符串,代表是对字符串进行unicode编码。
一般英文字符在使用各种编码下, 基本都可以正常解析, 所以一般不带u;但是中文, 必须表明所需编码, 否则一旦编码转换就会出现乱码。
建议所有编码方式采用utf8r/R:非转义的原始字符串
与普通字符相比,其他相对特殊的字符,其中可能包含转义字符,即那些,反斜杠加上对应字母,表示对应的特殊含义的,比如最常见的”\n”表示换行,”\t”表示Tab等。而如果是以r开头,那么说明后面的字符,都是普通的字符了,即如果是“\n”那么表示一个反斜杠字符,一个字母n,而不是表示换行了。
以r开头的字符,常用于正则表达式,对应着re模块。b:bytes
python3.x里默认的str是(py2.x里的)unicode, bytes是(py2.x)的str, b”“前缀代表的就是bytes
python2.x里, b前缀没什么具体意义, 只是为了兼容python3.x的这种写法python变量赋值(可变与不可变):
>>>a = 1 #将名字a与内存中值为1的内存绑定在一起 >>>a = 2 #将名字a与内存中值为2的内存绑定在一起,而不是修改原来a绑定的内存中的值,这时,内存中值为1的内存地址引用计数-1,当引用计数为0时,内存地址被回收 >>>b = a #变量b执行与a绑定的内存 >>>b = 3 #创建一个内存值为3的内存地址与变量名字b进行绑定。这时a还是指向值为2的内存地址。 >>>a,b >>>(2,3)
>>>x = 1 >>>y = 1 >>>z = 1 >>> x is y True >>>y is z True
解决CSDN写博客时行间距大:按shift+enter
import re line = "Cats are smarter than than dogs " matchObj = re.match( r'(.*) are (.*?) (.*?) (.*?) (.*? )', line, re.M|re.I) if matchObj: print ("matchObj.group() : ", matchObj.group()) print ("matchObj.group(1) : ", matchObj.group(1)) print ("matchObj.group(2) : ", matchObj.group(2)) print("matchObj.group(3) : ", matchObj.group(3)) print("matchObj.group(4) : ", matchObj.group(4)) print("matchObj.group(5) : ", matchObj.group(5)) else: print ("No match!!")结果:
matchObj.group(1) : Cats
matchObj.group(2) : smarter
matchObj.group(3) : than
matchObj.group(4) : than
matchObj.group(5) : dogs
举个例子一:
字符串"abcd"
那么"a.*"匹配的是"abcd"
"a.*?"匹配的是"a"
"a.*?d"匹配的是"abcd"
"a.*d"匹配的是"abcd"
举个例子一二:
字符串"abcdabcd" "a.*?d"匹配的是"abcd"(非贪婪模式即懒惰模式) "a.*d"匹配的是"abcdabcdabcd"(贪婪模式) 这就是贪婪和非贪婪的区别
#打开数据库链接 db = pymysql.connect('localhost', 'root', '12345', 'TESTDB')
db是数据库连接成功后返回的对象,可以用db对象对数据库进行增删改(操作数据库)cursor = db.cursor()
HTTP协议的几个重要概念(包括代理,网关等概念): https://zhidao.baidu.com/question/248304064.html
TCP/IP协议分层:https://www.jianshu.com/p/ef892323e68f
localhost是本地ip:127.0.0.1(指的是自己的电脑)| time.clock() 用以浮点数计算的秒数返回当前的CPU时间。用来衡量不同程序的耗时,比time.time()更有用。 这个需要注意,在不同的系统上含义不同。在UNIX/Linux系统上,它返回的是"进程时间",它是用秒表示的浮点数(时间戳)。而在WINDOWS中,第一次调用,返回的是进程运行的实际时间(wall time)。而第二次之后的调用是自第一次调用以后到现在的运行时间。(实际上是以WIN32上QueryPerformanceCounter()为基础,它比毫秒表示更为精确) |
smtpObj = smtplib.SMTP(mail_host) #创建SMTP对象
threadLock = threading.Lock()threading是线程模块,Lock()是一个函数,在这个函数中,有创建一个对象(具体是什么对象,要看这个函数最终返回的是什么对象,可以ctrl并点击这个函数进入函数体内查看具体是什么样的,看具体返回哪个对象),并返回这个对象,赋值给threadLock,该对象threadLock可以调用acquire和release函数,分别代表获取锁和释放锁(在线程同步中用到)
| time.clock() 用以浮点数计算的秒数返回当前的CPU时间。用来衡量不同程序的耗时,比time.time()更有用。 |
Python 有办法将任意值转为字符串:将它传入repr() 或str() 函数。
函数str() 用于将值转化为适于人阅读的形式,而repr() 转化为供解释器读取的形式。
repr()函数得到的字符串通常可以用来重新获得该对象,repr()的输入对python比较友好。通常情况下obj==eval(repr(obj))这个等式是成立的。而str()函数这没有这个功能。
在python中使用import语句导入模块时,python通过三个步骤来完成这个行为。(网址:http://blog.csdn.net/tuxl_c_s_d_n/article/details/45462139)
1:在python模块加载路径中查找相应的模块文件
2:将模块文件编译成中间代码
3:执行模块文件中的代码
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式。(n是前后台传递用的比较多的一种格式)
单引号里面不能出现单引号,双引号里面不能出现双引号。在写代码的时候,一条使用了单引号(‘’)或双引号(“”)的代码中如果出现了变量也需要使用引号,那么有两种解决办法:
1、使用单引号和双引号混编(谁在内谁在外都行)
rint("data2['url']", data2['url'])
rint('data2["url"]', data2['url'])2、 如果不混编的话,可以用转义符:
print('data2[\'name\']:', data2['name'])
print("data2[\"name\"]:", data2['name'])
闰秒,是指为保持协调世界时接近于世界时时刻,由国际计量局统一规定在年底或年中(也可能在季末)对协调世界时增加或减少1秒的调整。
儒略历(Julian calendar)是由罗马共和国独裁官儒略·恺撒(即盖乌斯·尤里乌斯·凯撒)采纳数学家兼天文学家索西琴尼的计算后,于公元前45年1月1日起执行的取代旧罗马历法的一种历法。儒略历中,一年被划分为12个月,大小月交替;四年一闰,平年365日,闰年366日为在当年二月底增加一闰日,年平均长度为365.25日。由于实际使用过程中累积的误差随着时间越来越大,1582年教皇格里高利十三世颁布、推行了以儒略历为基础改善而来的格里历,即沿用至今的公历。
WEB服务器、应用程序服务器、HTTP服务器区别:https://www.cnblogs.com/zhaoyl/archive/2012/10/10/2718575.html
自己电脑上开的服务器即属于web服务器又属于应用程序服务器,用的是TCP协议(协议用的最多的就是TCP协议,基本都是用TCP协议)
链接==URL
在Windows下,进入E:\apache\Apache24\cgi-bin目录过程:(第一次进入e盘不要加cd)(windows下按Tab键补全文件名即提示作用,dir命令是列出目录下的文件)
Python换行符问题:\n和\r的区别
同样都有换行的功能。不同的是光标的位置:\n在下一行开头,\r在本行的开头
cookie解释:(一个浏览器每一个页面都会存有一个cookie) 注:用户注册时会将用户名和密码一起写入后台服务器数据库中
后台服务器会发送一个cookie(Cookie信息存储在CGI的环境变量HTTP_COOKIE中)给客户端浏览器,这个客户端浏览器的cookie等待用户登录或者其他操作,此时cookie获取到用户的一些隐私信息(eg:用户名和密码),其作用一是用来保护用户隐私信息(将用户隐私信息进行加密,而不是明文存放,且不可解密),二是方便用户/简化客户端操作(联想校园联网操作,输入202.113.5.133后,用户进入登录页面,点击用户名的框,会有一系列用过的用户名,这是cookie的记忆作用,后台服务器会实时获取cookie中的信息,当用户选中其中一个用户名并填入密码点击登录时,后台服务器会筛选出cookie中这次提交的用户信息并与后台服务器数据库中的用户信息进行比对,如果相等允许登录;对于记住密码操作,是浏览器插件起的作用,会将你的密码进行保存,下次登录填入用户名后会自动填充相应密码,一般情况下密码的自动填充与cookie无关)。
如果开启一个新的页面,并进入到登录页面,与上述过程相同
cookie有到期时间,可以自己设定,例如,可以设定如果关掉浏览器,cookie的值会清零;或者将cookie的时间延长:关机后cookie的值会清零(注:关机后cookie的值还未清零,说明已将cookie的值写入用户硬盘中);还可以再延长:几天或者几周后cookie的值清零(即使写入了用户硬盘中,到期依然清零)
在cookie未清零之前,再次打开登录页面,或者有用户用过的所有用户名信息,或者直接是已登录状态(应该是还未关机的情况)。
get和post:(get:明文传送数据信息;post:不是明文的,更安全,不能直接从url中获取用户数据信息)
注:post可以用表单形式传送用户信息(eg:用户名和密码)给后台服务器数据库,也可以使用json格式将用户信息传给后台数据库
一、用表单形式:(网址:http://www.runoob.com/python3/python3-cgi-programming.html)
二、用json形式:(网址:http://blog.csdn.net/xukai871105/article/details/33800935)包
一般与ajax一起使用:使用Jquery中的ajax方法post传递JSON数据(是前台代码) -> 前台和js/jquery一起用,将用户提交的信息以json格式传给后台服务器,后台服务器有专门的ajax代码处理用户数据,并将处理结果仍已json格式返回给用户。即后台和前台交互ajax的时候需要有专门的代码 。
(django视频教学Model的设计和使用)中出现问题解决方案:
1、所有的models.ForeignKey()里面加上on_delete=models.CASCAD,且放在第二位置上
2、注意localhost不要写成localcost,用户名密码正确
3、每次创建表/修改表时在终端依次使用(在pycharm的Terminal中输入,而不是在![]() 这个中使用以下命令)
这个中使用以下命令)
python manage.py makemigrations [blog](根据models.py创建脚本0001_initial.py)
python manage.py migrate(将脚本0001_initial.py同步/迁移到数据库,即生成对应的model/表)
syncdb是同步用的,但是django1.8开始这个syncdb命令被移除了,用上述同步命令即可
4、python2有mysqldb,python3没有,python3使用pymysql,在__init__文件(blog下的与migrations同级的__init__文件)中写入:
import pymysql
pymysql.install_as_MySQLdb()
5、使用命令(在终端中输入)创建超级用户/管理员,在后台登录时用到:python manage.py createsuperuser
用户名:admin
密码:admin12345
6.https://stackoverflow.com/questions/38744285/django-urls-error-view-must-be-a-callable-or-a-list-tuple-in-the-case-of-includ/38744286
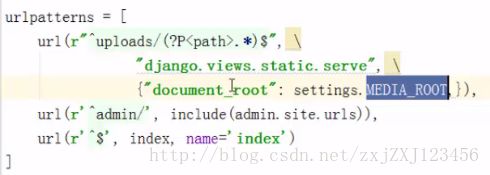
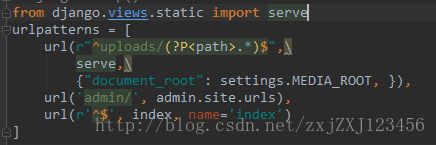
html页面跳转到另一个页面过程(base.html跳转到archive.html)(即主页面base.html文章归档跳转到归档文章)、:
由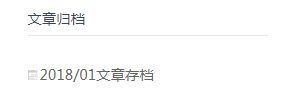 跳转到
跳转到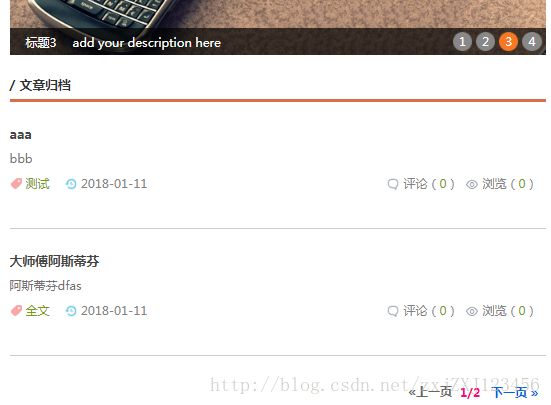
过程:
base.html中存在以下语句:想要跳转到archive.html页面(此跳转是get请求)
文章归档{% for archive in archive_list %}
class="tutime font-size-18">href='{% url "archive" %}?year={{ archive | slice:":4" }}&month={{ archive | slice:"5:7" }}'>{{ archive }}
{% endfor %}
首先要先访问到archive.html,需要配置 archive.html的路由(url路径),即在blog下的urls.py 中填写如下:
![]()
第一个参数 r'^archive/$' 代表对archieve.html页面配置的路由信息,但是进行跳转之前,需要先执行views.py中的archive方法(第二个参数),执行这个方法是为了将某一个月份中的所有文章读取出来,最后这个方法渲染出archive.html页面,并把读取出来的信息显示在这个页面中,而此时能够正常显示这个页面,因为已经填写好了这个页面的路由(即上面图中url方法中的第一个参数) 注:如果是do_login()方法,一定要先判断是单纯的页面跳转(get提交)还是表单提交(post提交),不同的提交方式在do_login()方法里执行的过程不一样,上面举的例子,在archive方法里只有一个get提交的处理方式,不涉及表单提交。
未解决问题:(第8节:admin的配置开始出现)用admin操作后台时,填写的内容不显示,而是显示object(1)...
(第13节:自定义Manager管理器-1开始出现 )用raw方法执行sql语句时,也是输出Article object(3)...而不是raw异常:Raw query must include the primary key
(第14节:{{ request.Get.year }}/{{ request.Get.month }}在archive.html中不能显示文章归档的日期)
(第15节中:在pagination.html中加入下面语句出现错误,未解决,但是不影响使用)(在后续执行中就一直有错,包括后面的评论排行执行中也有错,但不影响使用)
{% if request.GET.year %}&year={{ request.GET.year }}{% endif %}{% if request.GET.month %}&month={{ request.GET.month }}{% endif %})
(第17节中:评论表单没有出来)
用django做开发项目时,项目是跑在开发服务器上的,利用manage.py(一个开发服务器 - 效率低 - 不能在生成环境中使用-所以要进行部署)
{% if request.GET.year %}&year={{ request.GET.year }}{% endif %}{% if request.GET.month %}&month={{ request.GET.month }}{% endif %})