Spark -- Spark的smote算法,非平衡数据处理示例
向导
- 介绍
- 代码
- github参考代码
- 修改后代码
- 结果
- 根据我司需求的一个完整代码
- 测试数据
- 完整代码
- 结果
- 当前问题
- 改正
- 代码
- 结果
介绍
相关的理论,和代码可以参考:https://www.cnblogs.com/little-horse/p/11241168.html,这个参考代码我看了感觉有点偏老和偏复杂,于是找了另外一个版本。
spark的issues:https://issues.apache.org/jira/browse/SPARK-18441,其中有一个示例:https://gist.github.com/hhbyyh/346467373014943a7f20df208caeb19b,该网址需要,如果需要可以往下看。
代码
先说明下k和n的意义,k是指欧氏距离最近的k近邻,但只随机取其中一个近邻,以此为基准,在这条线上选取n个新样本。
在引入下面代码后会报错,org.apache.spark.ml.linalg.BLAS是private,不能被直接访问,我这里直接新建了org.apache.spark.ml.linalg文件夹,新建BLAS类,全部复制过来去掉private就可以了。
github参考代码
spark issues的解答中的示例代码如下:
package org.apache.spark.ml.feature
import org.apache.spark.ml.linalg.BLAS.axpy
import org.apache.spark.ml.linalg._
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import scala.util.Random
/**
* Created by yuhao on 12/1/16.
*/
object SmoteSampler {
def generateSamples(data: RDD[(Long, Vector)], k: Int, N: Int): RDD[Vector] = {
val knei = data.cartesian(data).map { case ((id1, vec1), (id2, vec2)) =>
(id1, vec1, vec2)
}.groupBy(_._1)
.map { case (id, iter) =>
val arr = iter.toArray
(arr(0)._2, arr.sortBy(t => Vectors.sqdist(t._2, t._3)).take(k + 1).tail.map(_._3))
}
knei.foreach(t => println(t._1 + "\t" + t._2.mkString(", ")))
knei.flatMap { case (vec, neighbours) =>
(1 to N).map { i =>
val rn = neighbours(Random.nextInt(k))
val diff = rn.copy
axpy(-1.0, vec, diff)
val newVec = vec.copy
axpy(Random.nextDouble(), diff, newVec)
newVec
}.iterator
}
}
}
// put it in another file.
package org.apache.spark.ml.feature
import org.apache.spark.ml.linalg.BLAS.axpy
import org.apache.spark.ml.linalg._
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import scala.util.Random
object SmoteTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local[2]")
.appName("smote example")
.getOrCreate()
// $example on$
val df = spark.createDataFrame(Seq(
(0L, Vectors.dense(1, 2)),
(1L, Vectors.dense(3, 4)),
(2L, Vectors.dense(5, 6))
)).toDF("id", "features")
val k = 2
val N = 3
val data = df.rdd.map(r => (r.getLong(0), r.getAs[Vector](1)))
val newSamples = SmoteSampler.generateSamples(data, k, N)
newSamples.collect().foreach(println)
spark.stop()
}
}
但是使用过后发现几个问题如下:
- 代码中使用了rdd的笛卡尔积,数据稍微多一点点,笛卡尔积都是一个很大的值,我本地以5000样本测试,笛卡尔积就达到5000*5000=25000000,本地已经跑不出来结果了。
- 上面的测试数据每个样本只给出了一个样本值,如果给出多个,例如给出多个label是0的,则上面的groupby,sort后取take和tail都会有问题。
修改后代码
根据上面的问题,我首先对笛卡尔积那里做了修改,不再生成笛卡尔积了,而是在groupby之后对map中每个向量生成笛卡尔积,这样因为是分区操作而且是真正的操作数据,非常之快。并且对于同样label的多样本的排序和take都是没问题的。
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local[2]")
.appName("smote example")
.getOrCreate()
// $example on$
val df = spark.createDataFrame(Seq(
(0L, Vectors.dense(1, 2)),
(0L, Vectors.dense(3, 4)),
(0L, Vectors.dense(11, 12)),
(1L, Vectors.dense(5, 6)),
(1L, Vectors.dense(7, 8)),
(1L, Vectors.dense(9, 10))
)).toDF("id", "features")
val k = 2
val N = 3
val data = df.rdd.map(r => (r.getLong(0), r.getAs[Vector](1)))
val newSamples = generateSamples1(data, k, N)
newSamples.collect().foreach(println)
spark.stop()
}
def generateSamples1(data: RDD[(Long, Vector)], k: Int, N: Int): RDD[Vector] = {
val groupedRDD = data.groupBy(_._1)
val vecAndNeis: RDD[(Vector, Array[Vector])] = groupedRDD.flatMap { case (id, iter) =>
val vecArr = iter.toArray.map(_._2)
//对每个vector产生笛卡尔积
val cartesianArr: Array[(Vector, Vector)] = vecArr.flatMap(vec1 => {
vecArr.map(vec2 => (vec1, vec2))
}).filter(tuple => tuple._1 != tuple._2)
cartesianArr.groupBy(_._1).map { case (vec, vecArr) => {
(vec, vecArr.sortBy(x => Vectors.sqdist(x._1, x._2)).take(k).map(_._2))
}
}
}
//1.从这k个近邻中随机挑选一个样本,以该随机样本为基准生成N个新样本
val vecRDD = vecAndNeis.flatMap { case (vec, neighbours) =>
(1 to N).map { i =>
val rn = neighbours(Random.nextInt(k))
val diff = rn.copy
axpy(-1.0, vec, diff)
val newVec = vec.copy
axpy(Random.nextDouble(), diff, newVec)
newVec
}.iterator
}
vecRDD
}
可以看到产生结果是很快的,即使换上稍微大些数据也是很快的,而且同一个label多个样本也是没问题的,如果将第二个代码的测试数据拿到第一个测试,不是报错就是取的近邻有问题。
结果
根据我司需求的一个完整代码
需求说明:只对指定的label值作为需要平衡的样本,对这些的每个样本选取k个近邻,取其中随机一个近邻为基准,生成n个新样本,最后合并到原数据中,并标识哪些是新增的,哪些是原有数据。
测试数据
http://archive.ics.uci.edu/ml/machine-learning-databases/00275/Bike-Sharing-Dataset.zip
hour.csv和day.csv都有如下属性,除了hour.csv文件中没有hr属性以外
- instant: 记录ID
- dteday : 时间日期
- season : 季节 (1:春季, 2:夏季, 3:秋季, 4:冬季)
- yr : 年份 (0: 2011, 1:2012)
- mnth : 月份 ( 1 to 12)
- hr : 当天时刻 (0 to 23)
- holiday : 当天是否是节假日(extracted from http://dchr.dc.gov/page/holiday-schedule)
- weekday : 周几
- workingday : 工作日 is 1, 其他 is 0.
- weathersit : 天气
- 1: Clear, Few clouds, Partly cloudy, Partly cloudy
- 2: Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist
- 3: Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds
- 4: Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog
- temp : 气温 Normalized temperature in Celsius. The values are divided to 41 (max)
- atemp: 体感温度 Normalized feeling temperature in Celsius. The values are divided to 50 (max)
- hum: 湿度 Normalized humidity. The values are divided to 100 (max)
- windspeed: 风速Normalized wind speed. The values are divided to 67 (max)
- casual: 临时用户数count of casual users
- registered: 注册用户数count of registered users
- cnt: 目标变量,每小时的自行车的租用量,包括临时用户和注册用户count of total rental bikes including both casual and registered
完整代码
package com.bigblue.ml
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.linalg.BLAS.axpy
import org.apache.spark.ml.linalg._
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import scala.util.Random
/**
* Created By TheBigBlue on 2020/3/23
* Description :
*/
object ImbalancedDataProcess {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName("test-lightgbm").master("local[4]").getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val originalData: DataFrame = spark.read.option("header", "true") //第一行作为Schema
.option("inferSchema", "true") //推测schema类型
// .csv("/home/hdfs/hour.csv")
.csv("file:///F:\\Cache\\Program\\TestData\\lightgbm/hour.csv")
val kNei = 5
val nNei = 10
//少数样本值
val minSample = 0
//标签列
val labelCol = "workingday"
// 连续列
val vecCols: Array[String] = Array("temp", "atemp", "hum", "casual", "cnt")
import spark.implicits._
//原始数据只保留label和features列,追加一列sign标识为老数据
val inputDF = originalData.select(labelCol, vecCols: _*).withColumn("sign", lit("O"))
//需要对最小样本值的数据处理
val filteredDF = inputDF.filter($"$labelCol" === minSample)
//合并为label和向量列
val labelAndVecDF = new VectorAssembler().setInputCols(vecCols).setOutputCol("features")
.transform(filteredDF).select(labelCol, "features")
//转为rdd
val inputRDD = labelAndVecDF.rdd.map(row => (row.get(0).toString.toLong, row.getAs[Vector](1)))
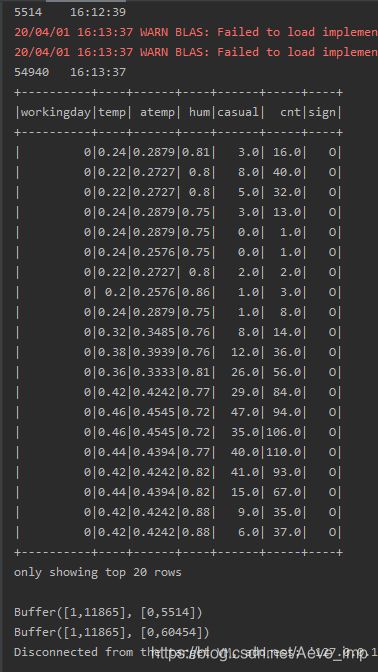
println(inputRDD.count() + "\t" + new SimpleDateFormat("HH:mm:ss").format(new Date()))
//smote算法
val vecRDD: RDD[Vector] = smote(inputRDD, kNei, nNei)
println(vecRDD.count() + "\t" + new SimpleDateFormat("HH:mm:ss").format(new Date()))
//以下是公司要求的和之前数据合并
//生成dataframe,将向量列展开,追加一列sign标识为新数据
val vecDF: DataFrame = vecRDD.map(vec => (0, vec.toArray)).toDF(labelCol, "features")
val newCols = (0 until vecCols.size).map(i => $"features".getItem(i).alias(vecCols(i)))
//根据需求,新数据应该为样本量*n,当前测试数据label为0的样本量为5514,则会新增5514*10=55140
val newDF = vecDF.select(($"$labelCol" +: newCols): _*).withColumn("sign", lit("N"))
//和原数据合并
val finalDF = inputDF.union(newDF)
finalDF.show
import scala.collection.JavaConversions._
//查看原数据
val aggSeq: Seq[Row] = originalData.groupBy(labelCol).agg(count(labelCol).as("labelCount"))
.collectAsList().toSeq
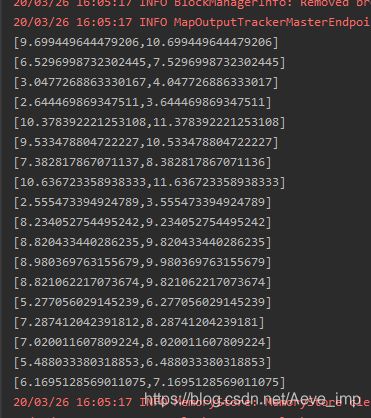
println(aggSeq)
//查看平衡后数据,根据需求,则最终合并后,label为0的样本为55140+5514=60654
val aggSeq1: Seq[Row] = finalDF.groupBy(labelCol).agg(count(labelCol).as("labelCount"))
.collectAsList().toSeq
println(aggSeq1)
}
//smote
def smote(data: RDD[(Long, Vector)], k: Int, N: Int): RDD[Vector] = {
val groupedRDD = data.groupBy(_._1)
val vecAndNeis: RDD[(Vector, Array[Vector])] = groupedRDD.flatMap { case (id, iter) =>
val vecArr = iter.toArray.map(_._2)
//对每个vector产生笛卡尔积
val cartesianArr: Array[(Vector, Vector)] = vecArr.flatMap(vec1 => {
vecArr.map(vec2 => (vec1, vec2))
}).filter(tuple => tuple._1 != tuple._2)
cartesianArr.groupBy(_._1).map { case (vec, vecArr) => {
(vec, vecArr.sortBy(x => Vectors.sqdist(x._1, x._2)).take(k).map(_._2))
}
}
}
//1.从这k个近邻中随机挑选一个样本,以该随机样本为基准生成N个新样本
val vecRDD = vecAndNeis.flatMap { case (vec, neighbours) =>
(1 to N).map { i =>
val rn = neighbours(Random.nextInt(k))
val diff = rn.copy
axpy(-1.0, vec, diff)
val newVec = vec.copy
axpy(Random.nextDouble(), diff, newVec)
newVec
}.iterator
}
vecRDD
}
}
结果
可以看出平衡后,追加了一列标识,label为0的样本也增加了10倍,并且运行很快,在样本为5500左右,本地运行不到一分钟就出结果了。
当前问题
根据我司需求,只需要对指定label值做smote,即在上述代码中通过filter过滤了只有label=固定值的数据,并且还根据该label列group by了,可想而知,filter过滤后的数据一定是label列都是一个固定值,然后groupby之后所有的数据因为label相同都会shuffle到一个分区中,而其他分区无数据。这样在shuffle read的时候因为只有一个分区有大数据量,导致其他task因为没数据很快就计算完了,但是有一个task因为数据量太大致使整个job耗时过长,或者直接内存不够而报错了。
改正
为了不影响计算效率,不让数据都落在一个分区,并且因为是只对一个label处理,那就不需要groupby了,而是用mapPartitions,对每个分区的数据计算k近邻,而不是把当前key所有数据都拉到一个分区再计算k近邻。
代码
package com.bigblue.ml
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.linalg.BLAS.axpy
import org.apache.spark.ml.linalg._
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import scala.util.Random
/**
* Created By TheBigBlue on 2020/3/23
* Description :
*/
object ImbalancedDataProcess {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName("test-lightgbm").master("local[4]").getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val originalData: DataFrame = spark.read.option("header", "true") //第一行作为Schema
.option("inferSchema", "true") //推测schema类型
// .csv("/home/hdfs/hour.csv")
.csv("file:///F:\\Cache\\Program\\TestData\\lightgbm/hour.csv")
val kNei = 5
val nNei = 10
//少数样本值
val minSample = 0
//标签列
val labelCol = "workingday"
// 连续列
val vecCols: Array[String] = Array("temp", "atemp", "hum", "casual", "cnt")
import spark.implicits._
//原始数据只保留label和features列,追加一列sign标识为老数据
val inputDF = originalData.select(labelCol, vecCols: _*).withColumn("sign", lit("O"))
//需要对最小样本值的数据处理
val filteredDF = inputDF.filter($"$labelCol" === minSample)
//合并为label和向量列
val labelAndVecDF = new VectorAssembler().setInputCols(vecCols).setOutputCol("features")
.transform(filteredDF).select("features")
//转为rdd
val inputRDD = labelAndVecDF.rdd.map(_.getAs[Vector](0)).repartition(10)
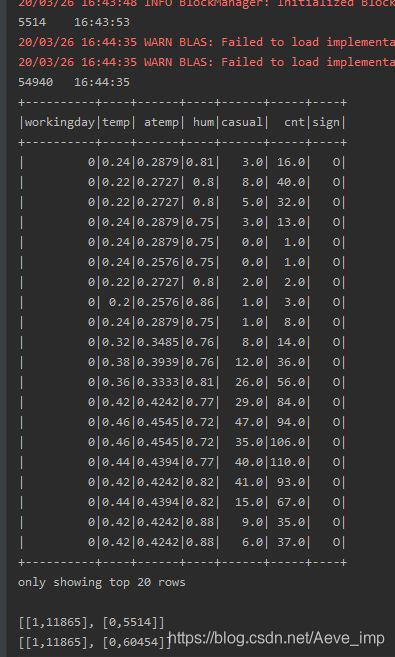
println(inputRDD.count() + "\t" + new SimpleDateFormat("HH:mm:ss").format(new Date()))
//smote算法
val vecRDD: RDD[Vector] = smote(inputRDD, kNei, nNei)
println(vecRDD.count() + "\t" + new SimpleDateFormat("HH:mm:ss").format(new Date()))
//以下是公司要求的和之前数据合并
//生成dataframe,将向量列展开,追加一列sign标识为新数据
val vecDF: DataFrame = vecRDD.map(vec => (0, vec.toArray)).toDF(labelCol, "features")
val newCols = (0 until vecCols.size).map(i => $"features".getItem(i).alias(vecCols(i)))
//根据需求,新数据应该为样本量*n,当前测试数据label为0的样本量为5514,则会新增5514*10=55140
val newDF = vecDF.select(($"$labelCol" +: newCols): _*).withColumn("sign", lit("N"))
//和原数据合并
val finalDF = inputDF.union(newDF)
finalDF.show
import scala.collection.JavaConversions._
//查看原数据
val aggSeq: Seq[Row] = originalData.groupBy(labelCol).agg(count(labelCol).as("labelCount"))
.collectAsList().toSeq
println(aggSeq)
//查看平衡后数据,根据需求,则最终合并后,label为0的样本为55140+5514=60654
val aggSeq1: Seq[Row] = finalDF.groupBy(labelCol).agg(count(labelCol).as("labelCount"))
.collectAsList().toSeq
println(aggSeq1)
}
//smote
def smote(data: RDD[Vector], k: Int, N: Int): RDD[Vector] = {
val vecAndNeis: RDD[(Vector, Array[Vector])] = data.mapPartitions(iter => {
val vecArr: Array[Vector] = iter.toArray
//对每个分区的每个vector产生笛卡尔积
val cartesianArr: Array[(Vector, Vector)] = vecArr.flatMap(vec1 => {
vecArr.map(vec2 => (vec1, vec2))
}).filter(tuple => tuple._1 != tuple._2)
cartesianArr.groupBy(_._1).map { case (vec, vecArr) => {
(vec, vecArr.sortBy(x => Vectors.sqdist(x._1, x._2)).take(k).map(_._2))
}
}.iterator
})
//1.从这k个近邻中随机挑选一个样本,以该随机样本为基准生成N个新样本
val vecRDD = vecAndNeis.flatMap { case (vec, neighbours) =>
(1 to N).map { i =>
val newK = if (k > neighbours.size) neighbours.size else k
val rn = neighbours(Random.nextInt(newK))
val diff = rn.copy
axpy(-1.0, vec, diff)
val newVec = vec.copy
axpy(Random.nextDouble(), diff, newVec)
newVec
}.iterator
}
vecRDD
}
}
结果
虽然在计算k近邻时减少了计算精度,但是因为对每个分区的数据计算k近邻而提高了运算速度和吞吐量,经测试,完全符合我们的需求需要。