线性回归,损失的定义,损失函数与优化方法,用统计学习方法来理解线性回归、损失函数和优化方法,Sklearn使用方法
目录
1.线性回归
一元线性关系
多元线性关系
2.损失:评估预测结果与真实值的偏差程度
误差累积的结果
总损失计算公式:
损失函数:最小二乘法
3.损失函数的优化方法
4.用统计学习方法来理解线性回归、损失函数和优化方法
5.Sklearn API接口与使用方式
波士顿房价预测案例
参考文档
1.线性回归
线性回归的定义:线性回归是一种通过自变量(一个或多个特征值)与因变量(目标值)之间的关系来进行建模的回归分析。
线性回归根据变量的数量可分为两种回归:
- 一元线性回归,涉及到的变量只有一个
- 多元线性回归:涉及到的变量在两个或两个之上
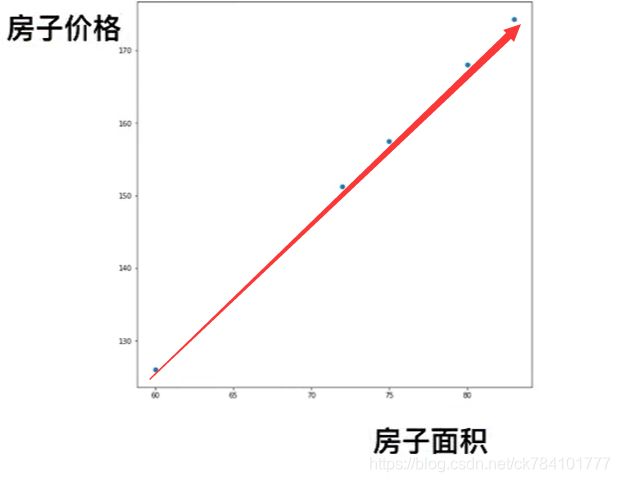
一元线性关系
典型的例子是预测房屋价格,假设我们的房屋价格作为目标值,特征为房子面积,通过分析房子面积与房子价格,可得到一种线性关系,我们将这种关系定义为:
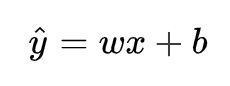
- w的符号决定线是上升还是下降,w值决定上升或下降的快慢。
- b为偏置,为了使线性模型更加通用
多元线性关系
一个通过特征的的线性组合来进行预测的函数
通用公式:
![]()
θ1和x1可看做一个样本,样本下有n个特征,θ0-θn为每个特征的权重,θ与x的乘积为一个样本的目标值
如有一组x1={1 2 3 4}
一组θ1={1
2
3
4}
根据矩阵乘法,有:
目标值=θ1*x1=1*1+2*2+3*3+4*4=30
2.损失:评估预测结果与真实值的偏差程度
看到一元线性关系,假设红圈所示为预测样本的真实值,箭头所示指向的直线上的一点为预测值,此时真实值与预测值存在偏差,称为损失。

以下是多元函数的损失情况:
误差累积的结果
以一元线性关系为例,我们知道,过两点确定一条直线
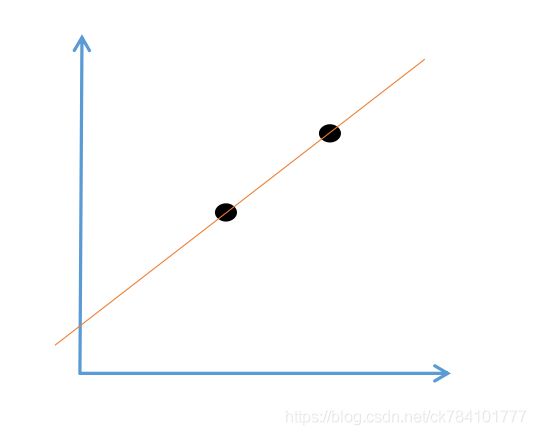
那么过三点呢,仅当第三点恰好满足直线方程时,它才可能在直线上。当第三点不在直线上时,就会存在偏差,假设黑点所在为真实值,红点所在为预测值,它们之间的差值就是损失
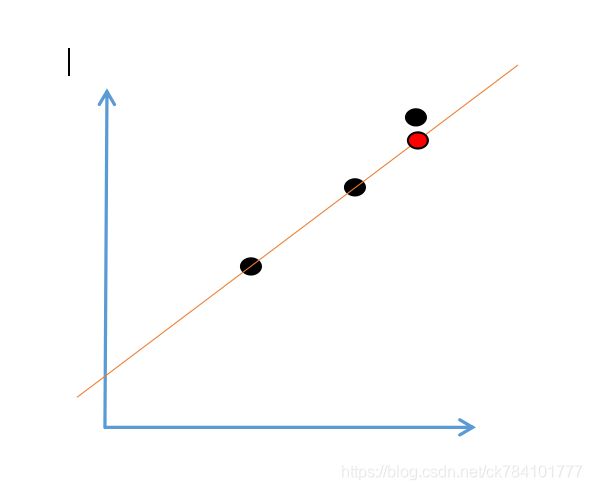
当这样的点增多后,虽然直线方程被不断拟合,但任有部分点在线外,随着点的数量不断增多,误差不断累积扩大,当计算完所有点的误差后,我们可以对当前线性回归的结果做一个评估,误差和越小,线性回归的结果就越好。

总损失计算公式:
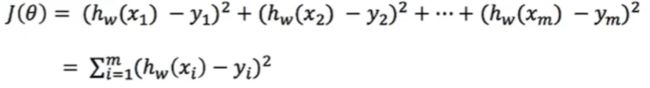
- 设yi为第i个训练样本的真实值
- hw(xi)为第i个训练样本特征值组合预测函数
损失函数:最小二乘法
计算完总损失后,可进一步求出总损失的平均值。求平均值的意义在与:当样本数不同的两个训练集进行对比时,总损失无法准确评估(样本数有差异),此时需要对总损失求平均值,该方法又称为最小二乘法。
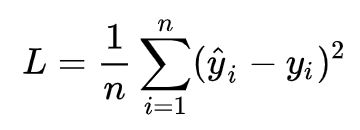
3.损失函数的优化方法
看到这里稍微梳理一下:由于回归是一种不断迭代的算法,通过不断的训练数据进行迭代优化,而优化的目的就是降低损失,使损失函数的值尽可能小,而试图降低损失的过程,就是一个优化过程,下面是两只常用的优化方法.
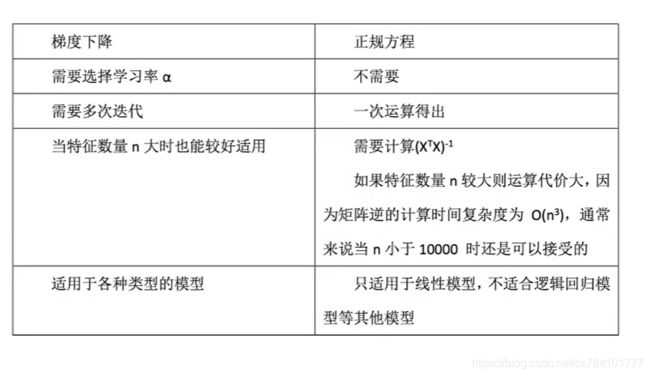
优化方法1:正规方程
正规方程实际上是对最小二乘法进行方程式推导得出的结果,其目的在于求最小θ,解算出最终方程后,带值进行运算(只需要一次运算),最终公式为(具体的推导式见文章最下方):
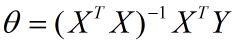
- X^T为X的转置矩阵
- X^-1为矩阵的逆
- Y为目标值
正规方程的的缺点在于:需要计算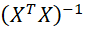 如果特征数量n较大则运算代价大,因为矩阵逆的计算时间复杂度为
如果特征数量n较大则运算代价大,因为矩阵逆的计算时间复杂度为  ,通常来说当n小于10000 时还是可以接受的。
,通常来说当n小于10000 时还是可以接受的。
优化方法2:梯度下降
我们以单变量(特征值为1)的例子来例假梯度下降的过程,假设有w1,w0两个变量,其中,w0和w1分别为
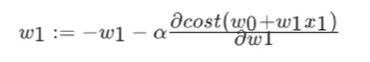
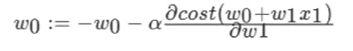
其中α被称作为学习率或者步长,意味着我们可以通过α来控制每一步走的距离, 表示下降方向,沿着这个函数向下找,最后就能找到最低点,而这个最低点,就是损失函数的最小值
表示下降方向,沿着这个函数向下找,最后就能找到最低点,而这个最低点,就是损失函数的最小值
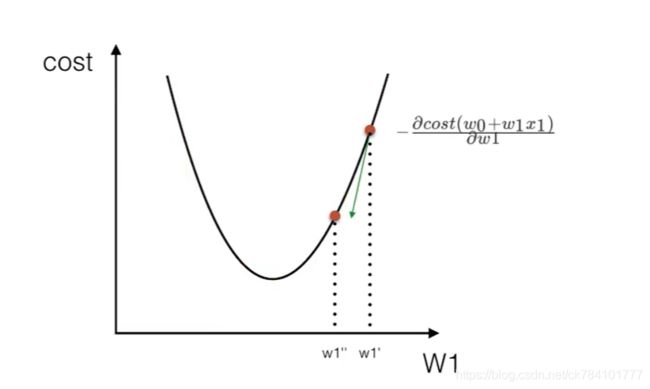
梯度下降和正规方法的对比:
4.用统计学习方法来理解线性回归、损失函数和优化方法
用统计学习方法来总结上文,首先我们需要明确算法,这里使用的是线性回归算法,线性回归算法需要不断迭代来优化线性方程,而评估优化结果的策略就是求解损失函数的最小值,如何求得最小值就是在求优化的过程,优化方法又分为正规方程(直接求解)和梯度下降(分步求解)。所以,统计学习方法的基本要素分为:算法,策略和优化过程。
| 算法 | 策略(损失函数) | 优化 |
| 线性回归 | 最小二乘法 | 正规方程/梯度下降 |
5.Sklearn API接口与使用方式
使用sklearn的优点是函数封装好,建立模型简单,易使用。但是算法的过程和参数都在算法API内部被固化,想要调参或优化算法需要改源码
推荐一个进阶工具:tensorflow,tensorflow需自行定义算法,数据处理过程,提供了很大的自由度
正规方程
from sklearn.linear_model import LinearRegression
梯度下降
from sklearn.linear_model import SGDRegressor
波士顿房价预测案例
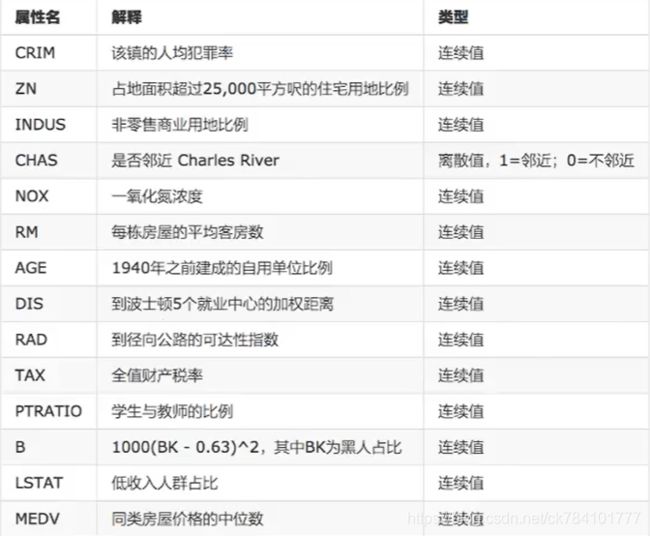
该实例的特征为
分析流程
- 1.获取波士顿地区房价数据
- 2. 对数据进行分割,训练集与测试集
- 3.对训练集与测试集做标准化处理,消除异常值影响
- 4.使用正规方程LinearRegression或梯度下降SGDRegressor对房价进行预测
程序
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
def fun():
#获取数据
boston=load_boston()
#分隔数据集合训练集
x_train,x_test,y_train,y_test=train_test_split(boston.data,boston.target,test_size=0.25)
#对特征值和目标值进行标准化处理
#目的:消除异常值影响
std=StandardScaler()
#特征值
x_train=std.fit_transform(x_train)
x_test=std.transform(x_test)
#目标值,不能共用一个预估器,所以需要另外实例化
std_y=StandardScaler()
#特别注意:由于这里的目标值是一维数组sklearn 0.19版本以上的预估器仅支持二维数组的输入格式,所以需要对一维数组转二维数组
#由于不知道目标值的个数,所以填-1,目标值对于每个样本只有一个,所以填1列
y_train=std_y.fit_transform(y_train.reshape(-1,1))
y_test=std_y.transform(y_test.reshape(-1,1))
#正规方程求解
lr=LinearRegression()
lr.fit(x_train,y_train)
#打印权重参数,可以看到每个特征的权重值
# print("权重结果:",lr.coef_)
#打印预测结果,注意需要反标准化
y_predict=std_y.inverse_transform(lr.predict(x_test))
# print("对于测试集的预测结果:",y_predict)
#打印均方误差
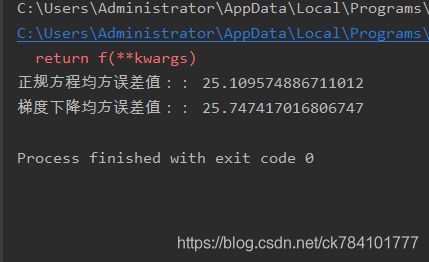
print("正规方程均方误差值::", mean_squared_error(std_y.inverse_transform(y_test),y_predict))
#梯度下降求解
sgd=SGDRegressor()
sgd.fit(x_train,y_train)
# 打印权重参数,可以看到每个特征的权重值
# print("权重结果:",sgd.coef_)
# 打印预测结果,注意需要反标准化
y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test))
# print("对于测试集的预测结果:",y_predict)
# 打印均方误差
print("梯度下降均方误差值::", mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict))
if __name__=="__main__":
fun()
输出结果(每一次执行的结果不一定相同,主要原因是在做数据分隔使每次的训练集测试集分到的样本不同导致):
补充:
1.回归性能评估
使用均方误差MSE(Mean Squared Error)评价机制进行回归性能评估。MSE是真实值与预测值的差值的平方然后求和平均。
公式:
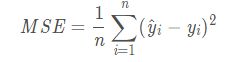
sklearn接口:
from sklearn.metrics import mean_squared_error
范围[0,+∞),当预测值与真实值完全相同时为0,误差越大,该值越大。
import numpy as np from sklearn import metrics y_true = np.array([1.0, 5.0, 4.0, 3.0, 2.0, 5.0, -3.0]) y_pred = np.array([1.0, 4.5, 3.5, 5.0, 8.0, 4.5, 1.0]) print(metrics.mean_squared_error(y_true, y_pred)) # 8.107142857142858
2.梯度下降学习率
sklearn设置了默认的超参数,可在实例化时修改
sgd=SGDRegressor(alpha=)
参考文档
正规方程 https://baike.baidu.com/item/%E6%AD%A3%E8%A7%84%E6%96%B9%E7%A8%8B/10001812
正规方程推到from吴恩达 https://blog.csdn.net/melon__/article/details/80589759
梯度下降算法原理讲解 https://blog.csdn.net/qq_41800366/article/details/86583789
什么是梯度下降 https://www.zhihu.com/question/305638940/answer/670034343
sklearn 和tensorflow的区别 https://blog.csdn.net/youhuakongzhi/article/details/94208335