InnoDB体系结构之日志篇
InnoDB体系结构之日志篇
首先我们看一下硬盘的的结构:
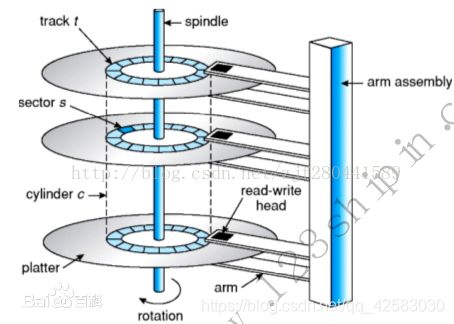
read-write head:磁头,读写数据的接口
platter:盘面
track:磁道
cylinder:柱面,由每个盘面上相同的磁道所组成
sector:扇区,磁盘的最小I/O单元
磁盘的容量就可以通过磁头数*2*柱面数*扇区数*512来计算
所以,我们读写磁盘上的数据的基本流程就是,通过arm assembly(机械臂杆)来控制磁头的移动,找到相应的磁道,然后再
磁道上以扇区为最小的I/O单元来读写数据。这里磁头找到相应的磁道所需要得时间就是寻道时间。对于随机数据页的写要不停
地通过移动磁头来寻找相应的磁道;那么对于顺序数据页的写,我们就可以减少寻道时间,顺序的将数据页写入磁盘。所以
Innodb就通过redo log将数据页的随机写转换成日志的顺序写;此外,如果有多个数据页同时更新,那么数据页的多次写也可以
通过日志的一次写来完成。以上两点就是日志系统对数据库I/O能力的主要影响。下面就具体说明一下innodb的日志系统:
Innodb采用WAL(write-ahead logging)机制,即数据页刷到磁盘前先写日志的原则。这样主线程只需要保证顺序的将日志写入
磁盘,事务就可以提交。后续只需要后台线程在相应的时机来将数据页刷进磁盘,这样就大大提高了数据库的事务处理能力。
下面看一下MySQL里一个事务(一条sql或者一组sql)的大概执行流程:
1,MySQL Server层会对这条或者这组sql进行解析
2,Innodb存储引擎上写undo log
3,Innodb存储引擎上写redo log
4,undo log刷入磁盘
5,redo log刷入磁盘
6,事务提交
这里的undo log其实就是对原数据页的拷贝,由于innodb的crash recovery以及MVCC都要用到原始的数据页,所以innodb要对
修改的数据页保留其原始版本。Innod在写redo之前会将其对undo的操作也记录到redo中去来保证undo的
完整性。redo log里真正记录的过程如下:
记录1:
记录2:
记录3:
记录4:
记录5:
记录6:
Innodb的redo log是一种物理的逻辑日志。比如一个插入操作,要写一条回滚段日志和具体插入页面的操作,更糟糕的是插入一
个页面的操作可能会出现页分裂的情况,那这时候一个插入操作又要分为对两个页面的操作,为了保证这每次的物理操作的完整
性,Innodb采用MTR(最小的物理事务)来保证每个物理的操作的完整性,所以对于每个事物的redo log就是由若干个mtr的日
志块来组成的。完整的流程如下图所示:
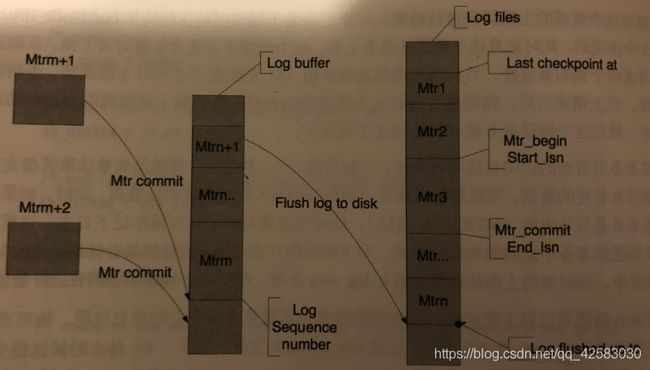 (摘自MySQL运维内参)
(摘自MySQL运维内参)
一个事务就是以mtr为单位写入log buffer中,然后从log buffer在写入log文件。Innodb通过innodb_flush_logs_at_trx_commit来控
制log写人磁盘的时机:
innodb_flush_logs_at_trx_commit=0:表示事务提交时,redo log只写入到log buffer中,然后等待主线程每秒将其刷出,写入log
文件中。这样的风险是最高的,如果MySQL异常宕机那么log buffer中所对应的日志就会丢失。
innodb_flush_logs_at_trx_commit=1:表示事务提交,redo log就要写入log文件中。这是最安全的设置。
innodb_flush_logs_at_trx_commit=2:表示事务提交时,log buffer中的日志会刷新到redo文件的OS cache中,等待操作系统每
秒进行刷盘。这种情况下,只要操作系统不挂,日志也不会丢失。
如果不是对数据安全性要求非常高的系统中,可以将innodb_flush_logs_at_trx_commit设置为2,能很大的提升服务器的性能
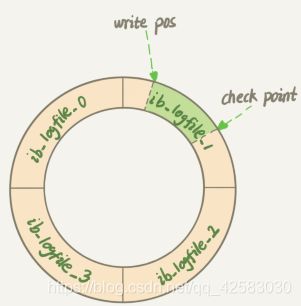 (摘自极客时间《MySQL 45讲》)
(摘自极客时间《MySQL 45讲》)
redo log文件的大小和个数有参数innodb_log_file_size和innodb_log_files_in_group来控制。redo log的空间是循环使用的,如上
图所示先从ib_logfile0开始一次写ib_logfile1、ib_logfile2、ib_logfile3,当ib_logfile3用完的时候就重新开始往ib_logfile0中里写,
然后依次循环使用。由于redo log文件是循环使用的,那么就要保证被重新使用的日志空间所对应的日志要失效,也就是这部分
日志对应的脏数据页要被刷到磁盘上去,但是又不能等到所有的日志文件写满了的时候再去做这些操作,因为这时redo log文件
已经变得很大,这时候再去刷盘或者innodb恢复的时候就会很慢,为了解决这些问题innodb引入了Checkpoint机制,也就是定期
的使一部分日志失效,保证log文件的高效使用。下面总结一下innodb的Checkpoint的分类:
一,Sharp Checkpoint(完全检查点)
在数据库关闭的时候,innodb会将buffer pool中所有的脏页刷到磁盘,进行sharp checkpoint。由参数innodb_fast_shutdown=1
来控制,Innodb的默认值。
二,Fuzzy Checkpoint(模糊检查点)
1,master thread会每秒或每十秒将一定比例的脏页刷到磁盘,做一次checkpoint;
2,每个redo log文件切换的时候,做一次checkpoint;
3,如果buffer pool中没有足够的空闲页的话,首先就要从LRU list上面摘取最后一定数量的数据页,摘取多少由参数
innodb_lru_scan_depth来决定,默认是1024个page,如果摘下来的数据页有脏页的话,就要刷盘做checkpoint;
4,如果buffer pool中的脏页比例到达所设定的数值时,也要进行刷脏页checkpoint。由参数innodb_max_dirty_pages_pct来决
定。这个值尽量设置在50%以下。
在上上个图中,其实有个关键点Log Sequence Number,也就是我们常说的LSN,日志的系列号,代表了目前最新写入的日志
总量。比较一下下面四个参数:
Log sequence number:代表目前最新写入日志的位置,也许只在log buffer中还没写入log文件
Log flushed up to:代表目前已经刷到日志文件中的位置
Page flushed up to:代表脏页已经刷新到的位置
Last checkpoint at:上一次检查点的位置
这四个值是从大到小的顺序,可以相等。
最后,说明一点就是,redo文件所对应的磁盘空间是在数据库初始化的时候就应分配好的连续一段空间,这也是保证了redo log
顺序写的效率。如果不这样处理的话,那么就会变成一段一段随机的物理位置,这样redo的顺序写效率也会降低。