本文主要讨论如何使用 Alink 的 Kafka 连接组件(Kafka011SourceStreamOp 和 Kafka011SinkStreamOp)读取写入数据。如何你需要一个本地的 Kafka 数据源进行实验,可以参考我另外一篇文章,详细介绍了搭建 Kafka 及建立 Topic 的过程。
- 在 MacOS 上搭建 Kafka
https://zhuanlan.zhihu.com/p/... - 在 Windows 上搭建 Kafka
https://zhuanlan.zhihu.com/p/...
首先,我们演示如何将流式数据写入 Kafka。
假设已经有一个 Kafka 的数据源(譬如:本地 Kafka 数据源,端口为 9092),并且 Kafka 中已经有一个 topic,名称为 iris,则 Kafka 写入组件 Kafka011SinkStreamOp 可以如下设置:
sink = Kafka011SinkStreamOp()\
.setBootstrapServers("localhost:9092")\
.setDataFormat("json")\
.setTopic("iris")注意:Kafka 写入的数据只能为字符串,需要设置每条记录转化为字符串的方式,这里我们使用 Json 格式。
我们还需要构造一个获取流式数据的方式,最简单的方式是使用 CsvSourceStreamOp 组件,将 csv 数据(alink-release.oss-cn-beijing.aliyuncs.com)以流的方式读入。然后,再连接 Kafka 写入组件,开始执行流式操作。完整代码如下:
URL = "https://alink-release.oss-cn-beijing.aliyuncs.com/data-files/iris.csv"
SCHEMA_STR = "sepal_length double, sepal_width double, petal_length double, petal_width double, category string"
data = CsvSourceStreamOp().setFilePath(URL).setSchemaStr(SCHEMA_STR)
sink = Kafka011SinkStreamOp()\
.setBootstrapServers("localhost:9092")\
.setDataFormat("json")\
.setTopic("iris")
data.link(sink)
StreamOperator.execute()由于 CSV 文件中数据有限,当读取完最后一条时,流式任务会结束。
接下来,我们可以使用 Alink 的 Kafka011SourceStreamOp 组件读取数据,并设置其消费者组 ID,读取模式为从头开始,具体代码如下:
source = Kafka011SourceStreamOp()\
.setBootstrapServers("localhost:9092")\
.setTopic("iris")\
.setStartupMode("EARLIEST")\
.setGroupId("alink_group")
source.print(key='kafka_iris', refreshInterval=1, maxLimit=500)
StreamOperator.execute()执行显示结果如下,PyAlink 对于流式数据的打印,是按一定的时间间隔,每次显示若干条(默认是100)。
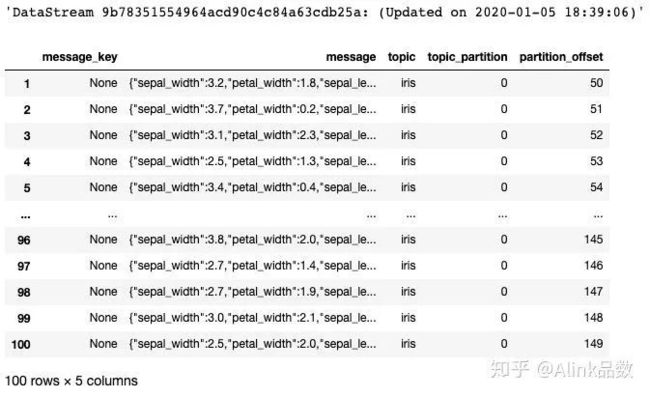
message 列显示的每条数据的信息,可以看到直接从 Kafka 中获取的每条数据都是 Json 格式的字符串。
我们在看到流式数据的同时,也注意到,连接 Kafka 的流式任务一直没有退出,需要我们点击菜单栏上的“中断”按钮,强行结束任务。

中断任务后,显示:

注意:之后,还需要点击 Restart 按钮,重启整个引擎,才能继续后面的操作。
接下来,我们需要对字符串里面的数据进行提取。推荐使用 JsonValueStreamOp,通过设置需要提取内容的 JsonPath,提取出各列数据。详细代码如下:
source = Kafka011SourceStreamOp()\
.setBootstrapServers("localhost:9092")\
.setTopic("iris")\
.setStartupMode("EARLIEST")\
.setGroupId("alink_group")
data = source.link(
JsonValueStreamOp()\
.setSelectedCol("message")
.setReservedCols([])
.setOutputCols(["sepal_length", "sepal_width", "petal_length", "petal_width", "category"])
.setJsonPath(["$.sepal_length", "$.sepal_width", "$.petal_length", "$.petal_width","$.category"])
)
data.getColTypes()关于结果数据的 Schema 打印为:
[object, object, object, object, object]可以看出 JsonValueStreamOp 提取出来的结果都是 object 类型的。我们可以使用Flink SQL 的 cast 方法,在代码实现上,只需在连接 JsonValueStreamOp 之后,再连接 SelectStreamOp 并设置其 SQL 语句参数,具体代码如下:
source = Kafka011SourceStreamOp()\
.setBootstrapServers("localhost:9092")\
.setTopic("iris")\
.setStartupMode("EARLIEST")\
.setGroupId("alink_group")
data = source.link(
JsonValueStreamOp()\
.setSelectedCol("message")
.setReservedCols([])
.setOutputCols(["sepal_length", "sepal_width", "petal_length", "petal_width", "category"])
.setJsonPath(["$.sepal_length", "$.sepal_width", "$.petal_length", "$.petal_width","$.category"])
).link(
SelectStreamOp()\
.setClause("CAST(sepal_length AS DOUBLE) AS sepal_length, "\
+ "CAST(sepal_width AS DOUBLE) AS sepal_width, "\
+ "CAST(petal_length AS DOUBLE) AS petal_length, "\
+ "CAST(petal_width AS DOUBLE) AS petal_width, category")
)
data.getColTypes()执行结果为:
[numpy.float64, numpy.float64, numpy.float64, numpy.float64, object]即,每列数据都转化为相应的类型。
下面,我们再对 data 进行打印,并开始执行流式任务,具体代码如下:
data.print()
StreamOperator.execute()流式数据打印显示如下图所示:
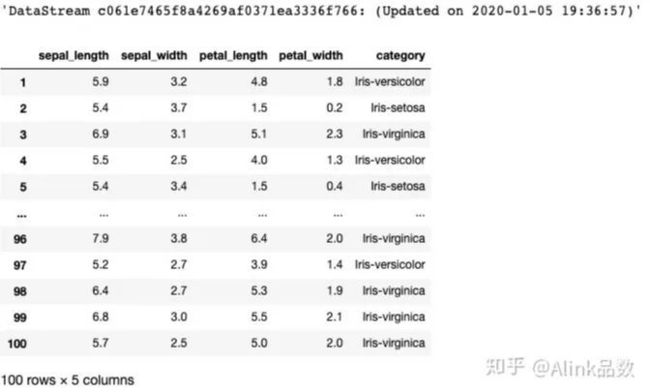
可以看出,配合使用 Alink 的相关组件,可以完整地从 Kafka 上读取、写入数据。后面,可通过 Alink 的各算法组件进行深入计算。
以上。Alink 是基于 Flink 的机器学习算法平台,欢迎访问 Alink 的 GitHub 链接获取更多信息。也欢迎加入 Alink 开源用户群进行交流~
Alink GitHub 链接:
https://github.com/alibaba/Alink
▼ 钉钉扫码加入 Alink 技术交流群 ▼
