zookeeper集群搭建及选举模式
1. zk集群搭建
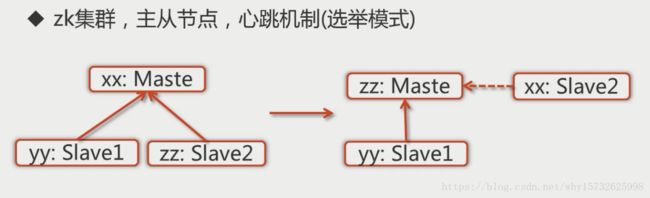
1.1 zk集群,主从节点,心跳机制(选举模式)
1.2 zk集群搭建注意点
- 配置数据文件 myid 1/2/3 对应server.1/2/3
- 通过 ./zkCli.sh -server [ip]:[port]检测集群是否配置成功
1.3 zookeeper真实环境集群搭建
- 需要注意:环境变量的配置,ip配置不同,端口号可以相同
- 复制3分zookeeper到3台不同的环境中
- 配置zoo.cfg
server.1 = 192.158.1.112:2888:3888
server.2 = 192.158.1.113:2888:3888
server.3 = 192.158.1.114:2888:3888- 配置myid文件
- 启动3个zookeeper
- 测试数据
- 选举测试
2.Leader选举
2.1 集群角色
通常在分布式系统中,构成一个集群的每一台及其都有自己的角色,最典型的集群模式就是Master/Slave模式(主备模式)。在这种模式中,我们把能够处理所有写操作的机器称为Master机器,把所有通过异步复制方式获取最新数据,并提供该服务的及其称为Slave机器。
而在Zookeeper中,这些概念被颠覆了。没有沿用传统的Master/Slave概念,而是引入了Leader、Follower和Observer三种角色。Zookeeper集群中的所有机器通过一个Leader选举过程来选定一台被称为“Leader”的机器,Leader服务器为客户端提供读和写服务,除Leader外,其他机器包括Follower和Observer。Follower和Observer都能够提供读服务,唯一的区别在于,Observer机器不参与Leader选举过程,也不参与写操作的“过半写成功”策略,因此Observer可以在不影响写性能的情况下提升集群的读性能。
2.1.1 Leader
Leader服务器是整个ZooKeeper集群工作机制中的核心,其主要工作有以下两个
- 事务请求的唯一调度和处理者,保证集群事务处理的顺序性
- 集群内部各服务器的调度者
2.1.2 Follower
Follower服务器是ZooKeeper集群状态的跟随者,其主要工作有以下三个
- 处理客户端非事务请求,转发事务请求给Leader服务器
- 参与事务请求Proposal的投票
- 参与Leader选举投票
2.1.3 Observer
Observer是Zookeeper自3.3.0版本开始引入的一个全新的服务器角色。从字面意思看,该服务器充当了一个观察者的角色—其观察Zookeeper集群的最新状态变化并将这些状态变更同步过来。Observer服务器在工作原理上和Follower基本一致,对于非事务请求,都可以进行独立的处理,而对于事务请求,则会转发给Leader服务器进行处理。和Follower唯一的区别在于,Observer不参与任何形式的投票,包括事务请求Proposal的投票和Leader选举投票。简单讲,Observer服务器只提供非事务服务,通常用于在不影响集群事务处理能力的前提下提升集群的非事务处理能力。
2.2 Leader选举概述
Leader选举是ZooKeeper中最重要的技术之一,也是保证分布式数据一致性的关键所在。
2.2.1 服务器启动时期的Leader选举
Leader选举的时候,需要注意的是,隐式条件便是ZooKeeper的集群规模至少是2台机器,这里我们以3台机器组成的服务器集群为例。在服务器集群初始化阶段,当有一台服务器(我们假设这台机器的myid为1,因此称其为Server1)启动的时候,它是无法完成Leader选举的。当第二胎机器(同样,我们假设这台服务器的myid是2,称其为Server2)也启动后,此时这两台机器已经能够进行互相通信,每台机器都试图找到一个Leader,于是便进入了Leader选举流程。
1. 每个Server会发出一个投票,由于是初始情况,因此对于Server1和Server2来说,都会将自己作为Leader服务器来进行投票,每次投票包含最基本的元素有:所推举的服务器的myid和ZXID,我们以(myid,ZXID)的形式来表示。因为是初始化阶段,因此无论是Server1还是Server2,都会投给自己,即Server1的投票为(1,0),Server2的投票为(2,0),然后各自将这个投票发给集群中其他所有机器。
2. 接收来自各个服务器的投票,每个服务器都会接收来自其他服务器的投票。集群中的每个服务器在接收到投票后,首先会判断该投票的有效性,包括检查是否是本轮投票,是否来自LOOKING状态的服务器。
3. 处理投票,在接收到来自其他服务器的投票后,针对每一个投票,服务器都需要将别人的投票和自己的投票进行PK,PK的规则如下:
1. 优先检查ZXID,ZXID比较大的服务器优先作为Leader
2. 如果ZXID相同的话,那么就比较myid。myid比较大的服务器作为Leader服务器- ==统计投票==,每次投票后,服务器都会统计所有投票,判断是否已经有过半的及其接收到相同的投票信息。对于Server1和Server2服务器来说,都统计出集群中已经有两台机器接受了(2,0)这个投票信息。这里我们需要对“过半”的概念做一个简单的介绍。所有“过半”就是指大于集群机器数量的一半,即大于或等于(n/2+1)。对于这里由3台机器构成的集群,大于等于2台即为达到“过半”要求。
- ==改变服务器状态==,一旦确定Leader,每个服务器就会更新自己的状态。如果是Follower,那么就变更为FOLLOWING,如果是Leader,那么就变更为LEADING。
2.2.1 服务器运行时期的Leader选举
在Zookeeper集群正常运行过程中,一旦选出一个Leader,那么所有服务器的集群角色一般不会再发生变化,也就是说,Leader服务器将一直作为集群的Leader,即使集群中有非Leader挂了或有新机器加入集群也不会影响Leader。但是一旦Leader所在机器挂了,那么整个集群将暂时无法对外提供服务,而是进入新一轮的Leader选举。服务器运行期间的Leader选举和启动时期的Leader选举基本过程一致的。
2.3 Leader选举的算法分析

2.3.1 术语解释
首先我们对ZooKeeper的Leader选举算法中出现的专有术语进行简单介绍:
SID:服务器ID
SID是一个数字,用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid的值一致。
ZXID:事务ID
ZXID是一个事务ID,用来唯一标识一次服务器状态的变更。在某一时刻,集群中每台机器的ZXID值不一定全都一致,这和ZooKeeper服务器对于客户端“更新请求”的处理逻辑有关
Vote:投票
Leader选举,就是通过投票来实现,当集群中的机器发现自己无法检测到Leader机器的时候,就会开始尝试进行投票。
Quorum:过半机器数
这个是整合Leader选举算法中最重要的一个术语,我们可以理解为一个量词,指的是ZooKeeper集群中过半的机器数,公式为==quorum=(n/2+1)==。例如:如果集群机器总数为3,那么quorum就是2
2.3.2 进入Leader选举
当ZooKeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举
- 服务器初始化启动
- 服务器运行期间无法和Leader保持连接
而当一台机器进入leader选举流程时,当前集群也可能会处于以下两个状态
- 集群中本来就存在一个Leader(这种情况,当新加入的机器试图选取Leader的时候,会被告知当前服务器的Leader信息,对于该机器,仅仅需要和Leader建立连接,并进行状态通过(数据同步))
- 集群中确定不存在Leader
2.3.3 当Leader不存在,进行第一次投票
通常两种情况导致集群中不存在Leader
- 整个服务器刚刚初始化启动时,此时尚未产生Leader
- 另一种情况是运行期间Leader服务器挂了
无论哪种情况,此时集群中的所有机器都处于一种试图选举出Leader的状态,称为“LOOKING”,意思是正在找Leader。当一台服务器处于LOOKING状态的时候,那么他就会向集群中所有机器发送消息,这个消息就称为“投票”。
消息包含两个最基本信息,所推举服务器的SID和ZXID,举例来说,如果推举的服务器SID为1,ZXID为8,则表示为(1,8)。
2.3.4 变更投票
集群中的每台机器发出自己的投票后,也会接受来自集群中其他机器的投票。每台机器会根据我们上面提到的规则进行投票,并以此来决定是否需要变更自己的投票。这个规则也成了整个Leader选举算法的核心所在。
- vote_sid:接收到投票中所推举的Leader服务器的SID
- vote_zxid:接收到投票中所推举的Leader服务器的ZXID
- self_sid:当前服务器自己的SID
- self_zxid:当前服务器自己的ZXID
每次对于受到的投票的处理,都是一个对(vote_sid,vote_zxid)和(self_sid,self_zxid)对比的过程。
- 规则1:如果vote_zxid大于self_zxid,就认可当前受到的投票,并两次将该投票发送出去
- 规则2:如果vote_zxid小于self_zxid,那么就坚持自己的投票,不做任何变更
- 规则3;如果vote_zxid等于self_zixd,那么就对比SID,如果vote_sid大于self_sid,那么就认可当前接收到的投票,并再次将该投票发送出去
- 规则4:如果vote_zxid等于self_zxid,并且vote_sid小于self_sid,那么同样坚持自己的投票,不做变更
2.3.5 确定Leader
经过这第二次投票后,集群中的每台机器都会再次受到其他机器的投票,然后开始统计投票,如果一台机器收到了超过半数的相同的投票,那么这个投票对应的SID机器即为Leader。