Python学习笔记之七(爬虫初识)
Python学习笔记之七(爬虫初识)
2019-07-17 15:13:06 星期三
1.爬虫初识
本课概要
- 如何查看模块功能以及如何安装模块
- 网络爬虫是什么?
- 网络爬虫能做什么事情?
如何了解一个模块的功能
很多朋友问到,当接触到一个新模块的时候,如何了解这个模块的功能。主要方法有:
1、help()-输入对应模块名
2、阅读该模块的文档,一些大型的模块都有,比如scrapy等。
3、查看模块的源代码,分析各方法的作用,当然也可以从名字进行相应的分析。
有些朋友在安装模块的时候,经常会出现超时然后自动断掉的问题,解决这种问题,我们可以这样做:
1、使用VPN(推荐)
2、多试几次
3、使用本地whl文件来安装(推荐)实战讲解。
http:/www.lfd.uciedu/~gohlke/pythonlibs/

网络爬虫是什么
简单来说,网络爬虫就是自动从互联网中定向或不定向地采集信息的一种程序。 #过滤信息
网络爬虫有很多种类型,常用的有**通用网络爬虫(搜索引擎)聚焦网络爬虫(定向采集信息)**等。
网络爬虫的功能
网络爬虫可以做很多事情,比如通用网络爬虫可以应用在搜索引擎中,聚焦网络爬虫可以从互联网中自动采集信息并代替我们筛选出相关的数据出来。具体来说,网络爬电经常可以应用在以下方面:
1、搜索引擎
2、采集金融数据
3、采集商品数据
4、自动过滤广告
5、采集竞争对手的客户数据
6、采集行业相关数据,进行数据分析
本地安装

2.网络爬虫运行原理

通用爬虫:从当前页面爬取,再从当前页面链接继续爬取。不存在采集和目的性。
聚焦网络爬虫:定义一个目标,将以爬取的页面放在列表中,再过滤,再把剩下的URL放入队列中,继续爬取。
3.正则表达式实战
本课概要
- 什么是正则表达式
- 原子
- 元字符
- 模式修正符
- 贪婪模式与懒惰模式
- 正则表达式函数
- 常见正则实例
- 简单的爬虫
- 从网页中提取出qq群
- 作业:提取出版社信息并写入文件中
什么是正则表达式
世界上信息非常多,而我们关注的信息有限。假如我们希望只提取出关注的数据,此时可以通过一些表达式进行提取,正则表达式就是其中一种进行数据筛选的表达式。
原子
原子是正则表达式中最基本的组成单位,每个正则表达式中至少要包含一个原子。常见的原子类型有:
a普通字符作为原子
b非打印字符作为原子!
c通用字符作为原子!
d原子表
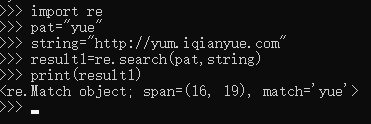
\w 匹配任意字母,数字,下划线
\d 匹配任意十进制数
\s 匹配任意空白字符
\W 匹配任意除了字母,数字,下划线以外的任何字符
\D 匹配任意除了十进制数以外的字符
\S 匹配任意除了空白字符以外的字符
原子表

元字符
所谓的元字符,就是正则表达式中具有一些特殊含义的字符,比如重复N次前面的字符等。
. 匹配任意字符
^ 匹配待搜索字符串的开始位置
$ 匹配字符串的结束位置
- 匹配1次以及多次出现的字符
? 匹配0次或者1次出现的字符
-
匹配0次或者多次出现的字符
t{6,}代表t至少出现6次
s{2,3}代表至少出现2次之多出现3次
例子:#元字符
pat=".python…"
string=“sdasdsadpythonasdsadcdvsdv”
rst=re.search(pat,string)
print(rst)
pat=“python|php”
string=“sadsajdphphjk3wek343k2nrpythonwernjk423n”
rst=re.search(pat,string)
print(rst)
模式修正符
所谓的模式修正符,即可以在不改变正则表达式的情况下,通过模式修正符改变正则表达式的含义,从而实现一些匹配结果的调整等功能。
I 匹配时忽略大小写
M 多行匹配
L 本地化识别匹配
U 根据unique字符解析字符
S 让"."匹配换行符
例子
#模式修正符
pat1="python"
pat2="python"
string="csajhbcijsadhcbjncjidsncuPythonisdnaiczxkcnjkdsnjcnzjkxc"
rst1=re.search(pat1,string)
rst2=re.search(pat2,string,re.I)#不区分大小写
print(rst1)
print(rst2)
None
贪婪模式与懒惰模式
贪婪模式的核心点就是尽可能多的匹配,而懒惰模式的核心点就是尽可能少的匹配。
#贪婪模式
pat1="p.*y"
pat2="p.*?y"
string="adcaisociuerbpythondfsafsdvcd"
rst1=re.search(pat1,string)
print(rst1)
#懒惰模式
pat1="p.*y"#0次 1次 多次
pat2="p.*?y"#0次 1次
string="adcaisociuerbpythondfsafsdpyvcd"
rst2=re.search(pat2,string)
print(rst2)
正则表达式函数
正则表达式函数有re.match()函数、re.search()函数、全局匹配函数、re.sub()函数
string="phssncayiewnianjiazncjasnjckjasmnckjansm"
rst=re.match(pat1,string)#match从头开始搜索
print(rst)
import re
pat1="p.*?y"
string="jcnapsjcnjhkxzncjkxzpyhjzxcjkxcpjsdahi"
rst=re.search(pat1,string)
print(rst)
import re
pat1="p.*y"
pat2="p.*?y"
string="pypdsfdbyjcnapsjcpvxcvxcypynjhkxzncjkxzpyhjzxcjpykxcpjsdahi"
rst2=re.compile(pat1).findall(string)
print(rst2)
[‘py’, ‘pdsfdby’, ‘psjcpvxcvxcy’, ‘py’, ‘py’, ‘py’]
import re
pat1="p.*y"
pat2="p.*?y"
string="pypdsfdbyjcnapsjcpvxcvxcypynjhkxzncjkxzpyhjzxcjpykxcpjsdahi"
rst2=re.compile(pat1).findall(string)
print(rst2)
[‘pypdsfdbyjcnapsjcpvxcvxcypynjhkxzncjkxzpyhjzxcjpy’]
常见正则实例
# 常见正则实例
pat="[a-zA-Z]+://[^\s]*[.com|.cn]"
string='=re.compile(pat).findall(string)
print(rst)
[‘http://www.baidu.com’]
简单的爬虫
# 简单的爬虫
pat="5(.*?)
"
import urllib.request
data=urllib.request.urlopen("http://edu.csdn.net/huiyiCourse/detail/215").read()
result=re.compile(pat).findall(str(data))
print(result)
[‘21840835’]
pat="5.*?
"
import urllib.request
data=urllib.request.urlopen("http://edu.csdn.net/huiyiCourse/detail/215").read()
result=re.compile(pat).findall(str(data))
print(result)
[‘
521840835
’]