【hadoop入门实战】Mac上安装hadoop,并运行程序(1)
安装hadoop
参考:http://blog.csdn.net/ksgt00016758/article/details/23625007
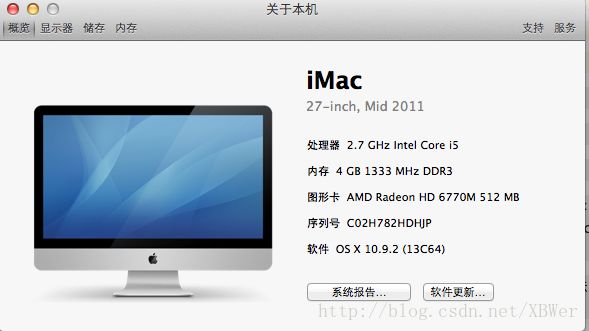
系统版本:
————————————————————————————————————————————————————————————————————————————
1.安装JAVA——之后会运行jar包,肯定需要java的运行环境
查看java版本:
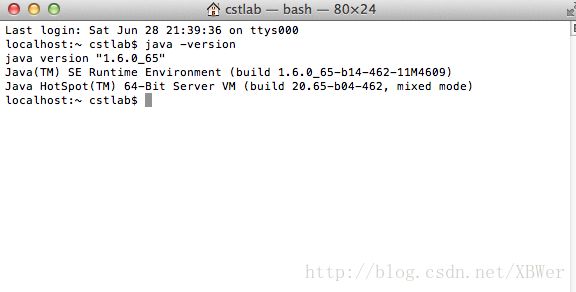
java -version
————————————————————————————————————————————————————————————————————————————
2.下载hadoop
地址:http://hadoop.apache.org/releases.html

然后看到

我没有选版本太高的,因为不会用

存放的路径可以看到:/Users/hadoop
配置mac os 自身环境
这个主要是配置ssh环境。先在terminal里面输入
不过这里面还有一个麻烦,就是每次都会要求输入用户密码。《Hadoop实战》提供了一种免登陆的方法。首先,输入
这个主要是配置ssh环境。先在terminal里面输入
ssh localhost不过这里面还有一个麻烦,就是每次都会要求输入用户密码。《Hadoop实战》提供了一种免登陆的方法。首先,输入
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
————————————————————————————————————————————————————————————————————————————
3设置环境变量
在实际启动Hadoop之前,有三个文件需要进行配置。
但在这之前,我们需要设置一下几个类似Windows的环境变量,方便以后在命令行敲命令。
export HADOOP_HOME=/Users/hadoop/hadoop-1.2.1 (根据你自己的目录进行设定)
export PATH=$PATH:$HADOOP_HOME/bin
但在这之前,我们需要设置一下几个类似Windows的环境变量,方便以后在命令行敲命令。
export HADOOP_HOME=/Users/hadoop/hadoop-1.2.1 (根据你自己的目录进行设定)
export PATH=$PATH:$HADOOP_HOME/bin
注明:export设置只对当前的bash登录session有效。这是存在内存里面的。如果你嫌麻烦,就直接写入etc中的profile文件里面就好。
————————————————————————————————————————————————————————————————————————————
4.配置hadoop-env.sh
在Hadoop->conf目录下,找到hadoop-env.sh,打开编辑进行如下设置:
export JAVA_HOME=/System/Library/Frameworks/JavaVM.framework/Versions/1.6.0/Home (去掉注释)
export HADOOP_HEAPSIZE=2000(去掉注释)
export HADOOP_OPTS="-Djava.security.krb5.realm=OX.AC.UK -Djava.security.krb5.kdc=kdc0.ox.ac.uk:kdc1.ox.ac.uk"(去掉注释)
注意第三个配置在OS X上最好进行配置,否则会报“Unable to load realm info from SCDynamicStore”。
在Hadoop->conf目录下,找到hadoop-env.sh,打开编辑进行如下设置:
export JAVA_HOME=/System/Library/Frameworks/JavaVM.framework/Versions/1.6.0/Home (去掉注释)
export HADOOP_HEAPSIZE=2000(去掉注释)
export HADOOP_OPTS="-Djava.security.krb5.realm=OX.AC.UK -Djava.security.krb5.kdc=kdc0.ox.ac.uk:kdc1.ox.ac.uk"(去掉注释)
注意第三个配置在OS X上最好进行配置,否则会报“Unable to load realm info from SCDynamicStore”。
————————————————————————————————————————————————————————————————————————————
5.配置core-site.xml——指定了NameNode的主机名与端口
hadoop.tmp.dir
hdfs://localhost:9000
A base for other temporary directories.
fs.default.name
hdfs://localhost:8020
————————————————————————————————————————————————————————————————————————————
6.配置hdfs-site.xml——指定了HDFS的默认参数副本数,因为仅运行在一个节点上,所以这里的副本数为1
dfs.replication
1
————————————————————————————————————————————————————————————————————————————
7.配置mapred-site.xml——指定了JobTracker的主机名与端口
mapred.job.tracker
hdfs://localhost:9001/value>
mapred.tasktracker.map.tasks.maximum
2
mapred.tasktracker.reduce.tasks.maximum
2
————————————————————————————————————————————————————————————————————————————
8.安装HDFS
经过以上的配置,就可以进行HDFS的安装了。
$HADOOP_HOME/bin/hadoop namenode -format如果出现以下结果:
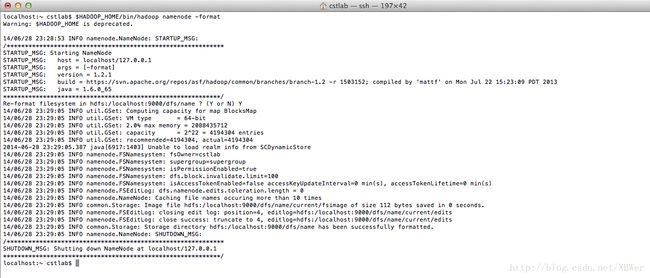
就说明你的HDFS已经安装成功了。
————————————————————————————————————————————————————————————————————————————
9.启动Hadoop
很简单,一条命令搞定。
很简单,一条命令搞定。
$HADOOP_HOME/bin/start-all.sh
到这里,hadoop单机伪分布式的环境就算搭建好了。
下一篇,用最简单的程序来看下效果。