Keras: 多输入及混合数据输入的神经网络模型
目录
摘要
正文
什么是混合数据?
Keras如何接受多个输入?
房价数据集
获取房价数据集
项目结构
加载数值和分类数据
加载图像数据集
定义多层感知器(MLP)和卷积神经网络(CNN)
使用Keras的多个输入
多输入和混合数据结果
总结
翻译自:Keras: Multiple Inputs and Mixed Data, by Adrian Rosebrock.
摘要
点击此处下载源代码:https://jbox.sjtu.edu.cn/l/NHfFZu
以回归预测房价作为背景。房价数据集不仅包括数值和类别数据,同样也包括图像数据,称之为多种类型的混合数据。模型需要能够接受多种类型的混合数据输入,并且计算得出回归问题的输出值。
在本教程的其余部分,您将学习如何:
- 定义一个Keras模型,该模型能够同时接受多个类型的输入数据,包括数值、类别和图像等类型的数据。
- 在混合数据输入上训练端到端的Keras模型。
- 使用多个输入来评估我们的模型。
正文
在本教程的第一部分中,我们将简要回顾混合数据的概念以及Keras如何接受多个类型输入数据。
什么是混合数据?
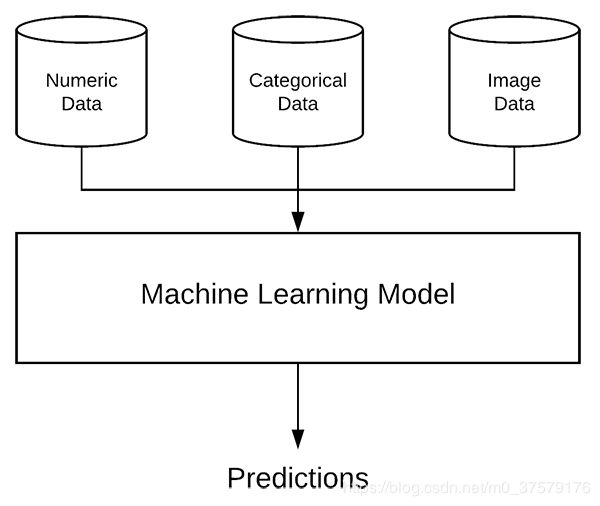
图1:使用灵活的Keras深度学习框架,可以定义一个多输入模型,其分别包括CNN和MLP分支来分别处理混合数据。
混合数据指的是同时使用不同数据类型的输入数据。
例如,假设我们是在一家医院工作的机器学习工程师,要开发一个能够对病人的健康状况进行分类的系统。
我们拥有一个病人的多种类型的输入数据,包括:
- 数值/连续值,如年龄、心率、血压
- 类别值,包括性别和种族
- 图像数据,如MRI、x片等。
我们的机器学习模型必须能够将这些**“混合数据”**,并对病人的健康状况做出(准确的)预测。
开发能够处理混合数据的机器学习系统非常具有挑战性,因为每种数据类型可能需要单独的预处理步骤,包括缩放、标准化和特征工程(feature engineering)。
处理混合数据仍然是一个非常开放的研究领域,并且常常严重依赖于特定的任务/目标。
Keras如何接受多个输入?
Keras能够通过它的函数API处理多个输入(甚至多个输出)。
您以前肯定通过Sequential 类使用过顺序式API,函数式API与之相反相反,可用于定义非顺序的复杂得多的模型,包括:
- 多输入模型
- 多输出模型
- 模型包括多个输入和多个输出
- 有向无环图
- 具有共享层的模型
例如,我们可以将一个简单的序列神经网络定义为:
model = Sequential()
model.add(Dense(8, input_shape=(10,), activation="relu"))
model.add(Dense(4, activation="relu"))
model.add(Dense(1, activation="linear"))该网络是一个简单的前馈神经网络,有10个输入,第一个隐层有8个节点,第二个隐层有4个节点,最后一个输出层用于回归。
我们可以使用functional API定义样本神经网络:
inputs = Input(shape=(10,))
x = Dense(8, activation="relu")(inputs)
x = Dense(4, activation="relu")(x)
x = Dense(1, activation="linear")(x)
model = Model(inputs, x)
# define two sets of inputs
inputA = Input(shape=(32,))
inputB = Input(shape=(128,))
# the first branch operates on the first input
x = Dense(8, activation="relu")(inputA)
x = Dense(4, activation="relu")(x)
x = Model(inputs=inputA, outputs=x)
# the second branch opreates on the second input
y = Dense(64, activation="relu")(inputB)
y = Dense(32, activation="relu")(y)
y = Dense(4, activation="relu")(y)
y = Model(inputs=inputB, outputs=y)
# combine the output of the two branches
combined = concatenate([x.output, y.output])
# apply a FC layer and then a regression prediction on the
# combined outputs
z = Dense(2, activation="relu")(combined)
z = Dense(1, activation="linear")(z)
# our model will accept the inputs of the two branches and
# then output a single value
model = Model(inputs=[x.input, y.input], outputs=z)可以看到我们定义了Keras神经网络的两个输入:
- inputA: 32维
- inputB: 128维
可视化模型架构为:
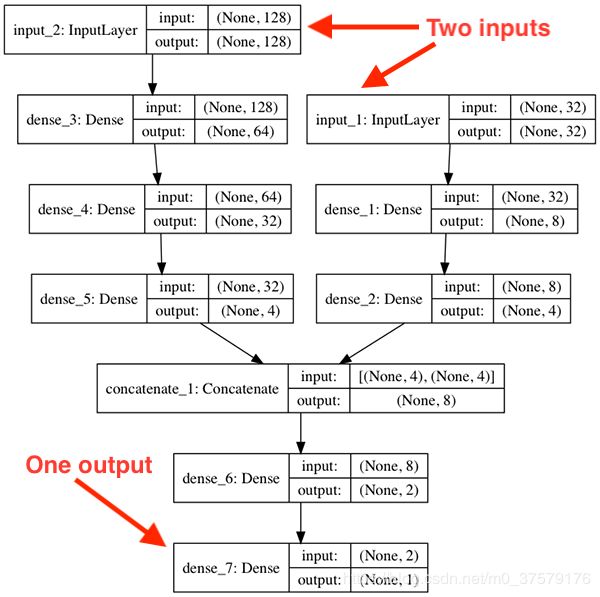
图2:这个模型有两个输入分支,它们最终合并并产生一个输出。Keras函数API允许这种类型的体系结构,你也可以构建任何其他您可以想象的架构。
注意我们的模型有两个不同的分支。
第一个分支接受128维输入,而第二个分支接受32维输入。这些分支在连接之前彼此独立运行,连接之后输出一个值。
在本教程的其余部分中,您将学习如何使用Keras创建多输入的网络。
房价数据集

图4:房价数据集包括数值数据,类别数据和图像数据。使用Keras,我们将构建一个支持多种输入和混合数据类型的模型,并且通过这个回归模型预测房屋的价值。
在这一系列文章中,我们使用了Ahmed和Mustafa在2016年发表的论文《从视觉和文本特征估计房价》(House price estimate from visual and text features)中的房价数据集。
这个数据集包括535个示例房屋的数值数据,类别数据以及图像数据。
数值属性和分类属性包括:
- 数量的卧室
- 数量的浴室
- 区域(面积)
- 邮政编码
每栋房子一共提供了四幅图片:
- 卧室
- 浴室
- 厨房
- 房子的正面
在本系列的第一篇文章中,您学习了如何根据数值和分类数据训练Keras回归网络。
在本系列的第二篇文章中,您学习了如何使用Keras CNN进行回归。
今天我们将使用Keras处理多个输入和混合数据。
我们将接受数值数据,类别数据和图像数据,通过定义网络的两个分支来处理每种类型的数据,最后将这些分支合并起来,得到我们最终的房价预测。通过这种方式,我们将能够利用Keras处理多个输入和混合数据。
获取房价数据集
点击此处下载源代码:https://jbox.sjtu.edu.cn/l/NHfFZu
房价数据集应该在keras-multi-input目录中,这是我们在这个项目中使用的目录。
项目结构
$ tree --dirsfirst --filelimit 10
.
├── Houses-dataset
│ ├── Houses\ Dataset [2141 entries]
│ └── README.md
├── pyimagesearch
│ ├── __init__.py
│ ├── datasets.py
│ └── models.py
└── mixed_training.py
3 directories, 5 filesHouses-dataset文件夹包含我们在本系列中使用的房价数据集。当我们准备好运行mixed_training.py脚本时,您只需要提供一个路径作为数据集的命令行参数(我将在结果部分向您详细说明这是如何完成的)。
今天我们将回顾三个Python脚本:
-
pyimagesearch/datasets.py: 加载和预处理我们的数字数据,类别数据以及图像数据。
-
pyimagesearch/models.py: 包含多层感知器(MLP)和卷积神经网络(CNN)。这些组件是我们的多输入混合数据模型的输入分支。
-
mixed_training.py: 首先我们的训练脚本将使用
pyimagesearch模块来加载和分割训练数据集,添加数据头,并将两个分支连接到我们的网络。然后对模型进行培训和评估。
加载数值和分类数据
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
import numpy as np
import glob
import cv2
import os
def load_house_attributes(inputPath):
# initialize the list of column names in the CSV file and then
# load it using Pandas
cols = ["bedrooms", "bathrooms", "area", "zipcode", "price"]
df = pd.read_csv(inputPath, sep=" ", header=None, names=cols)
# determine (1) the unique zip codes and (2) the number of data
# points with each zip code
zipcodes = df["zipcode"].value_counts().keys().tolist()
counts = df["zipcode"].value_counts().tolist()
# loop over each of the unique zip codes and their corresponding
# count
for (zipcode, count) in zip(zipcodes, counts):
# the zip code counts for our housing dataset is *extremely*
# unbalanced (some only having 1 or 2 houses per zip code)
# so let's sanitize our data by removing any houses with less
# than 25 houses per zip code
if count < 25:
idxs = df[df["zipcode"] == zipcode].index
df.drop(idxs, inplace=True)
# return the data frame
return dfload_house_attributes函数。该函数通过panda的pd以CSV文件的形式从房价数据集中读取数值和类别数据。
原始数据需要经过过滤以适应样本分布的不均匀性。如有些邮编仅由1或2所房子表示,因此我们要删除(第23-30行)来自邮编少于25所房子的任何记录。这样邮编样本数量分布不均匀的问题可以得到缓解,这样做的结果是得到一个更精确的模型。
定义process_house_attributes函数:
def process_house_attributes(df, train, test):
# initialize the column names of the continuous data
continuous = ["bedrooms", "bathrooms", "area"]
# performin min-max scaling each continuous feature column to
# the range [0, 1]
cs = MinMaxScaler()
trainContinuous = cs.fit_transform(train[continuous])
testContinuous = cs.transform(test[continuous])
# one-hot encode the zip code categorical data (by definition of
# one-hot encoding, all output features are now in the range [0, 1])
zipBinarizer = LabelBinarizer().fit(df["zipcode"])
trainCategorical = zipBinarizer.transform(train["zipcode"])
testCategorical = zipBinarizer.transform(test["zipcode"])
# construct our training and testing data points by concatenating
# the categorical features with the continuous features
trainX = np.hstack([trainCategorical, trainContinuous])
testX = np.hstack([testCategorical, testContinuous])
# return the concatenated training and testing data
return (trainX, testX)这个函数通过scikit-learn的MinMaxScaler(第41-43行)对连续特性应用最小-最大缩放。
然后,通过scikit-learn的LabelBinarizer(第47-49行)计算分类特征的one-hot编码。
然后将连续的和分类的特性连接起来并返回
加载图像数据集

图6:我们模型的一个分支接受一个图像——来自房屋的四个图像的拼合图像。利用拼合图像结合数字,类别数据,输入到另一个分支,然后我们的模型使用Keras框架回归与预测住宅的价值。
下一步是定义一个helper函数来加载输入图像。同样,打开data .py文件并插入以下代码:
def load_house_images(df, inputPath):
# initialize our images array (i.e., the house images themselves)
images = []
# loop over the indexes of the houses
for i in df.index.values:
# find the four images for the house and sort the file paths,
# ensuring the four are always in the *same order*
basePath = os.path.sep.join([inputPath, "{}_*".format(i + 1)])
housePaths = sorted(list(glob.glob(basePath)))load_house_images函数有三个功能:
- 从房价数据集中加载所有照片。回想一下,我们每个房子有四张照片(图6)。
- 从四张照片生成一个单一的拼合图像。拼合图像总是按照你在图中看到的那样顺序排列。
- 将所有这些主蒙版添加到列表/数组中并返回到调用函数。
继续:
- 初始化图像列表(第61行)并将用我们创建的所有拼合图像填充这个列表。
- 循环遍历数据帧中的房屋(第64行)以获取当前住宅的四张照片的路径
循环内部:
# initialize our list of input images along with the output image
# after *combining* the four input images
inputImages = []
outputImage = np.zeros((64, 64, 3), dtype="uint8")
# loop over the input house paths
for housePath in housePaths:
# load the input image, resize it to be 32 32, and then
# update the list of input images
image = cv2.imread(housePath)
image = cv2.resize(image, (32, 32))
inputImages.append(image)
# tile the four input images in the output image such the first
# image goes in the top-right corner, the second image in the
# top-left corner, the third image in the bottom-right corner,
# and the final image in the bottom-left corner
outputImage[0:32, 0:32] = inputImages[0]
outputImage[0:32, 32:64] = inputImages[1]
outputImage[32:64, 32:64] = inputImages[2]
outputImage[32:64, 0:32] = inputImages[3]
# add the tiled image to our set of images the network will be
# trained on
images.append(outputImage)
# return our set of images
return np.array(images)到目前为止,代码已经完成了上面讨论的第一个目标(每个房子抓取四个图像)。
-
在循环中,我们:
-
执行初始化(第72行和第73行)。我们的
inputImages将以列表的形式包含每条记录的四张照片。我们的inputImages将是照片的拼接图像(如图6所示)。 -
循环4张照片(第76行):
- 加载、调整大小并将每张照片附加到
inputImages中(第79-81行)。
- 加载、调整大小并将每张照片附加到
-
为四个房子的图片(第87-90行)创建平铺(拼接图像):
- 左上方的浴室图片。
- 右上角的卧室图片。
- 右下角的正面视图。
- 厨房在左下角。
-
添加拼接
outputImage到images(第94行)。
-
-
跳出循环,我们以NumPy数组的形式返回所有图像(第97行)。
定义多层感知器(MLP)和卷积神经网络(CNN)
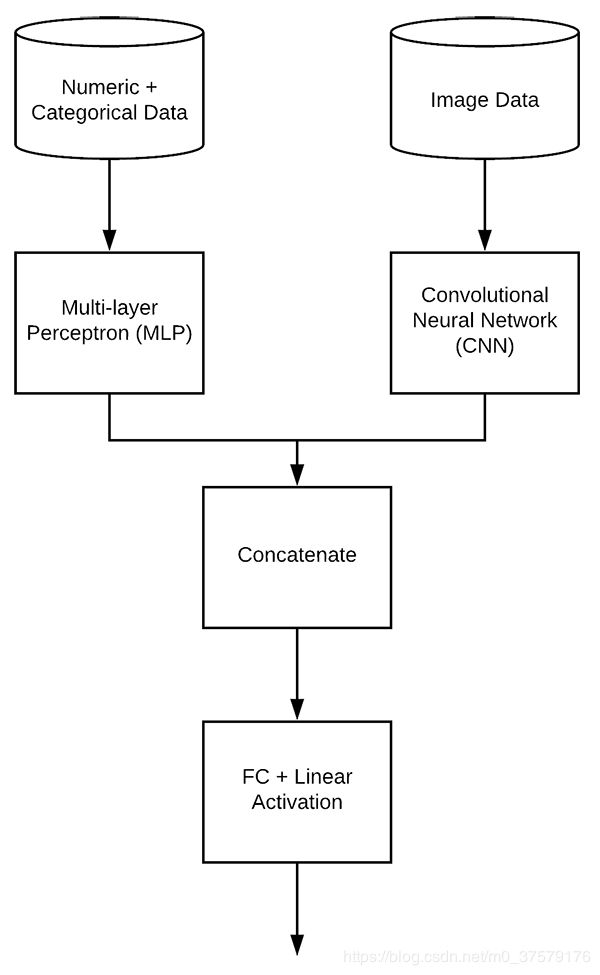
图7:Keras多输入(混合数据)模型有一个分支接受数字/类别数据(左),另一个分支接受4张照片拼接形式的图像数据(右)。
到目前为止,我们已经使用了多个库对数据进行了仔细的处理:panda、scikit-learn、OpenCV和NumPy。
我们已经通过datasets.py对数据集的两种模式进行了组织和预处理。
- 数字和分类数据
- 图像数据
为了实现这一点,我们所使用的技能是通过经验和实践一点点调试开发出来的。请不要忽视我们到目前为止所讨论和使用的数据处理技巧,因为它是我们项目成功的关键。
让我们换个话题,讨论一下我们将如何使用Keras的函数API构建的多输入和混合数据网络。
为了建立我们的多输入网络,我们需要两个分支:
- 第一个分支是一个简单的多层感知器(MLP),用于处理数值输入。
- 第二个分支是卷积神经网络,用于对图像数据进行操作。
- 然后将这些分支连接在一起,形成最终的多输入Keras模型。
我们将在下一节中处理构建最终的连接多输入模型,我们当前的任务是定义这两个分支。
打开models.py文件,插入如下代码:
# import the necessary packages
from keras.models import Sequential
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Dropout
from keras.layers.core import Dense
from keras.layers import Flatten
from keras.layers import Input
from keras.models import Model
def create_mlp(dim, regress=False):
# define our MLP network
model = Sequential()
model.add(Dense(8, input_dim=dim, activation="relu"))
model.add(Dense(4, activation="relu"))
# check to see if the regression node should be added
if regress:
model.add(Dense(1, activation="linear"))
# return our model
return model我们的类别/数值数据将由一个简单的多层感知器(MLP)处理。
MLP由create_mlp定义。
我们的MLP很简单:
- 具有ReLU激活的完全连接(密集)输入层
- 一个完全连接的隐藏层,也带有ReLU激活
- 最后,一个线性激活的可选的回归输出
虽然我们在第一篇文章中使用了MLP的回归输出,但是在这个多输入混合数据网络中不会使用它。您很快就会看到,我们将显式地设置regress=False,即使它也是默认值。稍后将在整个多输入混合数据网络的头部执行回归。
根据图7,我们现在已经构建了网络的左上分支。
现在让我们来定义我们网络的右上角分支,CNN:
def create_cnn(width, height, depth, filters=(16, 32, 64), regress=False):
# initialize the input shape and channel dimension, assuming
# TensorFlow/channels-last ordering
inputShape = (height, width, depth)
chanDim = -1
# define the model input
inputs = Input(shape=inputShape)
# loop over the number of filters
for (i, f) in enumerate(filters):
# if this is the first CONV layer then set the input
# appropriately
if i == 0:
x = inputs
# CONV => RELU => BN => POOL
x = Conv2D(f, (3, 3), padding="same")(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = MaxPooling2D(pool_size=(2, 2))(x)create_cnn函数处理图像数据并接受五个参数:
- 宽度:输入图像的宽度,单位为像素。
- 高度:输入图像的高度,单位为像素。
- 深度:输入图像中的通道数。对于RGB彩色图像,它是3。
- 过滤器:一组逐渐变大的过滤器,使我们的网络可以学习更多的区分功能。
- 回归:一个布尔值,指示是否将一个完全连接的线性激活层添加到CNN以进行回归。
从这里开始,我们开始遍历过滤器并创建一组CONV => RELU > BN =>POOL 层。循环的每次迭代都会累加这些层。
让我们完成CNN网络分支的建设:
# flatten the volume, then FC => RELU => BN => DROPOUT
x = Flatten()(x)
x = Dense(16)(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
x = Dropout(0.5)(x)
# apply another FC layer, this one to match the number of nodes
# coming out of the MLP
x = Dense(4)(x)
x = Activation("relu")(x)
# check to see if the regression node should be added
if regress:
x = Dense(1, activation="linear")(x)
# construct the CNN
model = Model(inputs, x)
# return the CNN
return model我们将下一层压平,意味着我们将所有提取到的特征组成一维特征向量,然后添加一个带有BatchNormalization和Dropout的全连接层。
另一个全连接层用于匹配来自多层感知器的四个节点。匹配节点的数量不是必需的,但它确实有助于平衡分支。
检查是否添加回归节点,如果需要就相应地将其添加进来。实际上,我们不会在这个分支的末尾进行回归。回归将在多输入混合数据网络的头部执行(图7的最底部)。
最后,模型由我们的输入和组装在一起的所有层组成。我们可以将CNN分支返回到调用函数(第68行)。
现在我们已经定义了多输入Keras模型的两个分支,让我们学习如何组合它们!
使用Keras的多个输入
现在,我们准备构建最终的Keras模型,该模型能够处理多个输入和混合数据。这是分支聚集的地方——“魔法”发生的地方。
训练也将在这个脚本中进行。
创建一个名为mixed_training.py的新文件,打开它,并插入以下代码:
# import the necessary packages
from pyimagesearch import datasets
from pyimagesearch import models
from sklearn.model_selection import train_test_split
from keras.layers.core import Dense
from keras.models import Model
from keras.optimizers import Adam
from keras.layers import concatenate
import numpy as np
import argparse
import locale
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", type=str, required=True,
help="path to input dataset of house images")
args = vars(ap.parse_args())首先,让我们导入必要的模块并且解析命令行参数。
datasets: 我们的三个方便的功能,从房屋数据集加载/处理CSV数据和加载/预处理房屋照片。models: 我们的MLP和CNN输入分支,它们将作为我们的多输入混合数据服务。train_test_split: 一个scikit-learn函数,用于构造我们的训练/测试数据分割。concatenate: 一个特殊的Keras函数,它将接受多个输入。argparse: 处理解析命令行参数。
在第15-18行中,我们有一个命令行参数需要解析,即dataset,它是您下载房价数据集的路径。
接下来,让我们加载我们的数值/分类数据和图像数据:
# construct the path to the input .txt file that contains information
# on each house in the dataset and then load the dataset
print("[INFO] loading house attributes...")
inputPath = os.path.sep.join([args["dataset"], "HousesInfo.txt"])
df = datasets.load_house_attributes(inputPath)
# load the house images and then scale the pixel intensities to the
# range [0, 1]
print("[INFO] loading house images...")
images = datasets.load_house_images(df, args["dataset"])
images = images / 255.0在这里,我们将房价数据集加载为panda dataframe(第23行和第24行)。然后我们加载图像并将其缩放到 [0,1] (第29-30行)。
如果需要提醒您这些函数的底层功能,请务必查看上面的load_house_attributes和load_house_images函数。
现在我们的数据已经加载完毕,我们将构建我们的培训/测试分割,调整价格,并处理房屋属性:
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
print("[INFO] processing data...")
split = train_test_split(df, images, test_size=0.25, random_state=42)
(trainAttrX, testAttrX, trainImagesX, testImagesX) = split
# find the largest house price in the training set and use it to
# scale our house prices to the range [0, 1] (will lead to better
# training and convergence)
maxPrice = trainAttrX["price"].max()
trainY = trainAttrX["price"] / maxPrice
testY = testAttrX["price"] / maxPrice
# process the house attributes data by performing min-max scaling
# on continuous features, one-hot encoding on categorical features,
# and then finally concatenating them together
(trainAttrX, testAttrX) = datasets.process_house_attributes(df,
trainAttrX, testAttrX)我们的训练和测试是在第35行和第36行进行的。我们分配了75%的数据用于培训,25%的数据用于测试。
在此基础上,我们从培训集(第41行)中找到maxPrice,并相应地调整培训和测试数据(第42行和第43行)。将价值数据调整到[0,1]范围内,可以更好地训练和收敛。
最后,我们通过对连续特征执行最小-最大缩放和对分类特征执行一次热编码继续处理我们的房子属性。
process_house_attributes函数处理这些操作,并将连续的和分类的特性连接在一起,返回结果(第48行和第49行)。
准备好施魔法了吗?
好吧,我说谎了。在下一个代码块中实际上没有任何“魔力”!但我们将连接我们的网络分支,完成我们的多输入Keras网络:
# create the MLP and CNN models
mlp = models.create_mlp(trainAttrX.shape[1], regress=False)
cnn = models.create_cnn(64, 64, 3, regress=False)
# create the input to our final set of layers as the *output* of both
# the MLP and CNN
combinedInput = concatenate([mlp.output, cnn.output])
# our final FC layer head will have two dense layers, the final one
# being our regression head
x = Dense(4, activation="relu")(combinedInput)
x = Dense(1, activation="linear")(x)
# our final model will accept categorical/numerical data on the MLP
# input and images on the CNN input, outputting a single value (the
# predicted price of the house)
model = Model(inputs=[mlp.input, cnn.input], outputs=x)当您组织好代码和模型后,使用Keras处理多个输入是非常容易的。
在第52行和第53行,我们创建mlp和cnn模型。注意regress=False——我们的回归头出现在第62行后面。
然后我们将连接mlp输出和cnn输出如第57行所示。我将其称为我们的combinedInput,因为它是网络其余部分的输入(从图3中可以看到,这是concatenate_1,两个分支在一起)。
网络中最后一层的组合输入是基于MLP和CNN分支的 8-4-1 FC层的输出(因为这两个分支都输出4维 FC层,然后我们将它们连接起来创建一个8维向量)。
我们将一个由四个神经元组成的完全连接的层固定在combinedInput上(第61行)。然后我们添加“liner”activation回归头(第62行),其输出为预测价格。
让我们继续编译、培训和评估我们新形成的模型:
# compile the model using mean absolute percentage error as our loss,
# implying that we seek to minimize the absolute percentage difference
# between our price *predictions* and the *actual prices*
opt = Adam(lr=1e-3, decay=1e-3 / 200)
model.compile(loss="mean_absolute_percentage_error", optimizer=opt)
# train the model
print("[INFO] training model...")
model.fit(
[trainAttrX, trainImagesX], trainY,
validation_data=([testAttrX, testImagesX], testY),
epochs=200, batch_size=8)
# make predictions on the testing data
print("[INFO] predicting house prices...")
preds = model.predict([testAttrX, testImagesX])我们的模型是用“mean_absolute_percentage_error”损失和一个Adam优化器编译的,该优化器具有学习率衰减(第72行和第73行)。
训练在第77-80行开始。这就是所谓的模型拟合(也就是所有权重都由称为反向传播的过程进行调优的地方)。
通过对测试数据集调用model.predict(第84行)可以获取模型预测的房屋价值来评估我们的模型。
现在让我们进行评估:
# compute the difference between the *predicted* house prices and the
# *actual* house prices, then compute the percentage difference and
# the absolute percentage difference
diff = preds.flatten() - testY
percentDiff = (diff / testY) * 100
absPercentDiff = np.abs(percentDiff)
# compute the mean and standard deviation of the absolute percentage
# difference
mean = np.mean(absPercentDiff)
std = np.std(absPercentDiff)
# finally, show some statistics on our model
locale.setlocale(locale.LC_ALL, "en_US.UTF-8")
print("[INFO] avg. house price: {}, std house price: {}".format(
locale.currency(df["price"].mean(), grouping=True),
locale.currency(df["price"].std(), grouping=True)))
print("[INFO] mean: {:.2f}%, std: {:.2f}%".format(mean, std))为了评估我们的模型,我们计算了绝对百分比(第89-91行),并使用它得出了最终的度量标准(第95和96行)。
这些度量(价格平均值、价格标准差和绝对百分比的平均值以及标准差)将以合适的格式(第100-103行)打印到终端。
多输入和混合数据结果

图8:房地产价格预测是一项困难的任务,但是我们的Keras多输入和混合输入回归模型在我们有限的房价数据集上产生了比较好的结果。
最后,我们在混合数据上训练我们的多输入网络!
确保你准备好了:
- 根据本系列的第一个教程配置开发环境。
- 使用本教程的源代码。
- 使用上面“获取房价数据集”一节中的说明下载房价数据集。
在此基础上,打开终端,执行以下命令,开始网络训练:
$ python mixed_training.py --dataset Houses-dataset/Houses\ Dataset/我们的平均绝对百分比误差开始非常高,但在整个培训过程中不断下降。
在训练结束时,我们得到了22.41%的测试集绝对误差,这意味着我们的网络对房价的预测平均会下降22%左右。
我们将这个结果与本系列之前的两篇文章进行比较:
- 仅对数值/分类数据使用MLP: 26.01%
- 仅用CNN对图像数据:56.91%
- 使用混合数据:22.41%
如你所见,处理混合数据的方法如下:
- 结合我们的数字/l类别数据和图像数据
- 对混合数据进行多输入模型的训练。
- 带来了一个性能更好的模型!
总结
在本教程中,您学习了如何定义能够接受多个输入的Keras网络。
您还学习了如何使用Keras处理混合数据。
为了实现这些目标,我们定义了一个能够接受的多输入神经网络:
- 数值数据
- 分类数据
- 图像数据
在训练前,将数值数据的min-max缩放到[0,1]范围。我们的类别数据是one-hot编码的(确保得到的整数向量在[0,1]范围内)。
然后将数值和类别数据连接成一个特征向量,形成Keras网络的第一个输入。
我们的图像数据也被缩放到范围[0,1]——这些数据作为Keras网络的第二个输入。
模型的一个分支包含严格的全连通层(对于连接的数值和类别数据),而多输入模型的第二个分支本质上是一个小的卷积神经网络。
将两个分支的输出组合起来,定义一个输出(回归预测)。
通过这种方式,我们能够训练我们的多个输入网络端到端,从而获得比仅使用其中一个输入更好的准确性。