vmware 10.0.1、ubuntu-14.04.5和hadoop2.8.5 搭建hadoop小集群
说明:用的工具和软件如下(我的宿主机为win7 64位):
vmware 10.0.1、ubuntu-14.04.5-desktop-amd64.iso(桌面版)、hadoop2.8.5
环境:我在宿主机上用vmware创建了两台主机,主机都安装ubuntu-14.04.5桌面版操作系统,且主机都安装hadoop,只是主、从机器的hadoop配置文件不一样,配置文件主要区别在于ip地址的不同
(至于怎么用vm安装ubuntu,这篇文章不再讨论,可参考网上其他文章)
目录:
一、安装java(省略,可参考其他网上文章)
二、下载hadoop
三、安装hadoop
四、配置hadoop集群
五、安装ssh
六、运行hadoop
步骤:
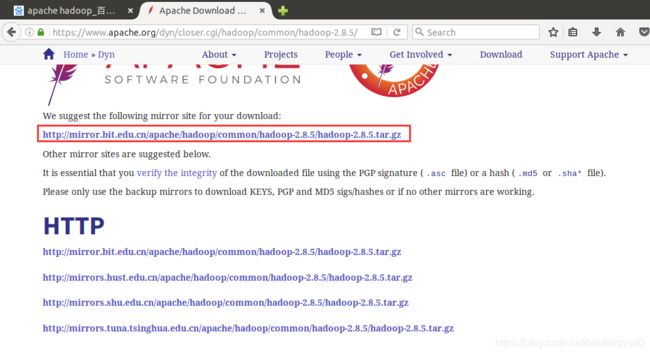
二、下载hadoop
可以到官网下载



三、安装hadoop
1)解压hadoop安装包到opt目录下
sudo tar zxvf hadoop-2.8.5.tar.gz -C /opt
2)创建软链接
sudo ln -snf /opt/hadoop-2.8.5 /opt/hadoop

3)配置环境变量
在/etc/profile文件中加入以下内容:
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
验证环境变量是否生效
![]()
4)使用hadoop version命令测试是否配置成功

四、配置hadoop集群
说明:我搭建的这个集群很简单(由于笔记本电脑性能不佳,只能开两个虚拟主机)
192.168.2.160 主
192.168.2.161 从
1、分别在虚拟主机上修改hadoop-env.sh
这个文件在/opt/hadoop-2.8.5/etc/hadoop目录下面(请根据实际安装目录查找)
将文件中的
export JAVA_HOME=${JAVA_HOME}
改为下图所示(java的安装目录)
![]()
附:在ubuntu中怎么查找java的安装目录
进入相应的目录
cd /usr/bin查看java的链接
ls -l java![]()
再进入到相应的目录
cd /etc/alternatives执行
ls -l java
从上图可知,java的安装目录为/usr/lib/jvm/java-8-oracle
2、修改core-site.xml文件
这几个文件都在/opt/hadoop-2.8.5/etc/hadoop目录下
将core-site.xml文件修改为如下
fs.defaultFS
hdfs://mip:9000
说明:mip:在主节点的mip就是自己的ip(例如:我的是192.168.2.160),而所有从节点的mip是主节点的ip(例如:我的是192.168.2.160)。
9000:主节点和从节点配置的端口都是9000
3、修改hdfs-site.xml文件
dfs.nameservices
hadoop-cluster
dfs.replication
1
dfs.namenode.name.dir
file:///data/hadoop/hdfs/nn
dfs.namenode.checkpoint.dir
file:///data/hadoop/hdfs/snn
dfs.namenode.checkpoint.edits.dir
file:///data/hadoop/hdfs/snn
dfs.datanode.data.dir
file:///data/hadoop/hdfs/dn
说明:dfs.nameservices:在一个全分布式集群大众集群当中这个的value要相同
dfs.replication:因为hadoop是具有可靠性的,它会备份多个文本,这里value就是指备份的数量(小于等于从节点的数量)
4、修改mapred-site.xml文件
注意:如果在刚解压之后,是没有这个文件的,需要将mapred-site.xml.template复制为mapred-site.xml。
mapreduce.framework.name
yarn
5、修改yarn-site.xml文件
yarn.resourcemanager.hostname
mip
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.local-dirs
file:///data/hadoop/yarn/nm
说明:mip:在主节点的mip就是自己的ip,而所有从节点的mip是主节点的ip。
6、创建上面配置的目录
sudo mkdir -p /data/hadoop/hdfs/nn
sudo mkdir -p /data/hadoop/hdfs/dn
sudo mkdir -p /data/hadoop/hdfs/snn
sudo mkdir -p /data/hadoop/yarn/nm一定要设置成:sudo chmod -R 777 /data
7、注意:我的hadoop解压完成后,在/opt/hadoop-2.8.5目录下面没有logs文件夹,如果不创建,启动hadoop会报错
所以,得创建logs文件夹,在该目录下执行
mkdir logs
提示,没有权限,然后用su命令,切换成root用户,创建成功
但是,启动还是报错,因为我用的是普通用户,没有权限读写root的logs文件夹
所以,需要再次进行授权
操作如下(在/opt/hadoop-2.8.5目录下,依次执行下面两个命令,目的:将logs的读写权限赋给当前用户):
chown -R 用户名:组名 logs
chmod 760 logs
chown命令说明:更改目录的所有者:
例如:chown -R john:build /tmp/src
结果:将目录 /tmp/src 中所有文件的所有者和组更改为用户 john 和组 build
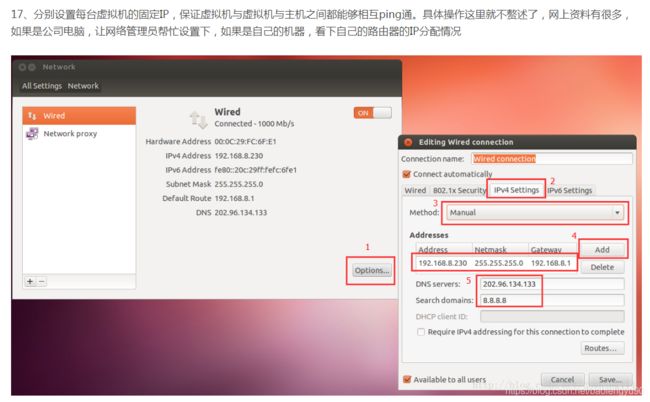
8、局域网-两台虚拟主机网络的设置
我选择的是桥接模式,即两个虚拟主机都是桥接模式


最好在启动虚拟机启动之前将这个设置好,如下图

系统启动成功后,开始设置静态ip地址
我尝试了通过修改/etc/network/interfaces文件进行设置
如下图的这种方式没有成功,暂时不清楚原因

查看/var/log/syslog的系统日志文件,也没看出来为啥获取不到ip地址
后来,终于找到下面道友的方法,按照这种方式就行了
友情链接:https://blog.csdn.net/downing114/article/details/60956979
后来,又出点问题,网络还是不通,直接用命令方式:
sudo ifconfig eth0 192.168.2.161 netmask 255.255.255.0
sudo route add default gw 192.168.2.1
网络通了(怎么检查,1、检查能否pin通网关2、能否pin通其他主机):

五、安装ssh
1、先查看是否运行了ssh,执行如下命令
ps -ef|grep ssh
如果未显示sshd这个进程,则说明未运行
这是运行的效果:

2、查看是否安装
可以到这个目录检查有没有这些文件
/etc/init.d/ssh
3、安装ssh
sudo apt-get install openssh-server
然后重启SSH服务:
sudo /etc/init.d/ssh restart
六,运行hadoop
在/opt/hadoop/sbin目录下面,执行
start-all.sh 命令
如下:

当时报这个错误Read from socket failed: Connection reset by peer(见上图最后一行)
查看/var/log/auth.log日志:

找了很长时间,没解决
最后,在/etc/ssh目录下除moduli、ssh_config两个文件删除后,再次生成密钥居然可以了
sudo ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
sudo ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
sudo ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key
密钥参考文章:https://linux.cn/article-4226-1.html
再次执行开启hadoop命令:start-all.sh
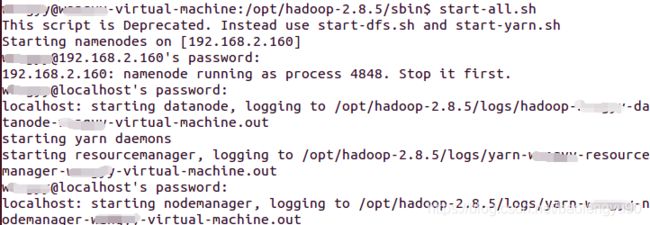
应该是成功启动了
再输入jps命令

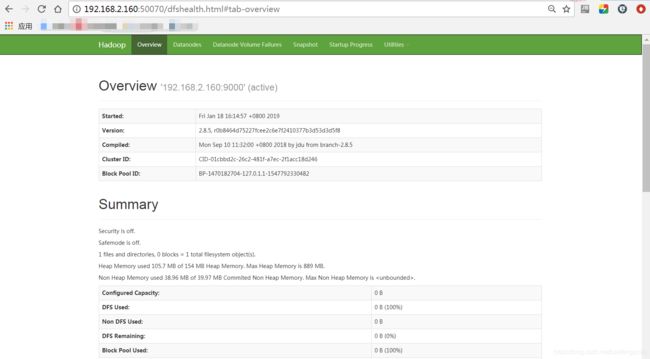
访问这个地址:
http://192.168.2.160:8088/

http://192.168.2.160:50070

hadoop环境的搭建,主要参考这篇文章,感谢https://www.cnblogs.com/zhangyinhua/p/7652686.html,不过参考的这篇文章中有两个配置文件有语法错误,导致启动报错,我在自己写的这篇文章中,配置文件已经改正。推荐大佬的hadoop系列文章https://www.cnblogs.com/zhangyinhua/tag/%E8%B5%B7%E8%88%AAHadoop/
链接:
Hadoop:启动与停止命令https://blog.csdn.net/jinwufeiyang/article/details/71156678
理解 VMWare的3种网络模型 zhttps://www.cnblogs.com/zeroone/p/4773728.html