Hadoop Web项目--Mahout0.10 MR算法集锦
1. 涉及技术及下载
项目开发使用到的软件有:Myeclipse2014,JDK1.8,Hadoop2.6,MySQL5.6,EasyUI1.3.6,jQuery2.0,Spring4.1.3,Hibernate4.3.1,Struts2.3.1,Maven3.2.1,Mahout0.10。
项目下载地址:https://github.com/fansy1990/mahout1.0,项目部署参考:http://blog.csdn.net/fansy1990/article/details/46481409 。
2. 项目介绍
此项目是在Hadoop Web项目–Friend Find系统 基础之上整理Mahout0.10版本中MR程序的调用测试而成,重点演示如何调用Mahout0.10的MR算法、如何把MR算法嵌入到Web项目中,附带数据生成及数据查看、MR 任务监控等功能。
Mahout0.10的MR算法主要参考下面的文件: 
此文档里面含有了覆盖常用工具类、聚类算法、分类算法、推荐算法等的MR调用mahout命令以及其对应的实现类。
此篇博客接下来将按照下面的内容进行编写:
- 项目部署及运行;
- 项目实现原理;
- 如何进行项目二次开发;
- 项目目前功能简单介绍;
- 总结;
3. 项目部署及运行
3.1 下载、部署
- 下载工程,参考上面的连接https://github.com/fansy1990/mahout1.0,并参考http://blog.csdn.net/fansy1990/article/details/46481409把它部署到Tomcat上;
- (默认,在上面步骤中已经配置好了mysql数据库,数据库的配置参考src/main/resources/db.properties文件)这里直接在Tomcat上运行项目,即可初始化好mysql对应的数据表(这里只有一个,即Hadoop集群配置表),打开浏览器在左边导航栏访问Hadoop集群配置表页面,进行配置(配置自己的集群);或直接在mysql数据库中进行配置即可。配置项包括(这里默认是使用node101机器的配置):
mapreduce.app-submission.cross-platform=true
fs.defaultFS=hdfs://node101:8020
mapreduce.framework.name=yarn
yarn.resourcemanager.address=node101:8032
yarn.resourcemanager.scheduler.address=node101:8030
mapreduce.jobhistory.address=node101:10020
3.2 注意事项
- 设置Hadoop云平台系统linux的时间和运行tomcat的机器的时间一样,因为在云平台任务监控的时候使用了时间作为监控停止的信号。否则,监控模块将会有问题。
- 此项目中并没有开发任何MR程序,所以不需要拷贝源码到Hadoop的lib目录(如果在进行二次开发时,开发了相关的MR,则需要拷贝);
项目部署好后,访问项目url,即可看到下面的界面:
4. 实现原理
项目组织架构: 
4.1 页面框架
页面采用html+jQuery+easyUI开发,整个页面使用easyUI的layout标签,左边导航栏使用easyUI的tree标签,其数据使用json格式存储在src\main\webapp\tree_data.json文件中。
针对某个页面,其json配置如下:
{
“id”:152,
“text”:”fkmeans+”,
“attributes”:{
“folder”:”0”,
“url”:”clustering/fuzzykmeans.jsp”
}
}
这样在点击左边导航栏fkmeans+导航时,即可在右边弹出clustering/fuzzykmeans.jsp页面。其js代码如下:
$('#navid').tree({
onClick: function(node){
// alert(node.text+","+node.url); // alert node text property when clicked
console.info("click:"+node.text);
if(node.attributes.folder=='1'){
return ;
}
console.info("open url:"+node.attributes.url)
var url;
if (node.attributes.url) {
url = node.attributes.url;
} else {
url = '404.jsp';
}
console.info("open "+url);
layout_center_addTabFun({
title : node.text,
closable : true,
iconCls : node.iconCls,
href : url
});
}
}); 其中 layout_center_addTabFun函数如下:
function layout_center_addTabFun(opts) {
var t = $(‘#layout_center_tabs’);
if (t.tabs(‘exists’, opts.title)) {
t.tabs(‘select’, opts.title);
} else {
t.tabs(‘add’, opts);
}
console.info(“打开页面:”+opts.title);
}
这个函数主要是判断右边窗口是否有名字为给定title的页面,如果没有,则打开这个页面。
js全部代码如下: 
其中basic.js是首页的js文件,包含一些公共的js函数等;hconstants.js主要是针对Hadoop配置表进行的操作;jquery*.js对应的两个文件为jQuery的必须文件;mr*.js对应则是MR不同类别算法对应的js处理文件;preprocess.js为数据构造、数据查看的js处理;
4.2 请求提交逻辑
请求提交主要包括:MR算法任务提交,非MR算法任务提交,其他请求提交。这里都采用统一的提交逻辑,如下: 
4.2.1 页面提交
这里所有页面提交都直接使用easyUI的< a > 标签,同时在js里面绑定其提交的点击触发函数。在函数里面需要首先获取页面参考(如果是MR监控任务,则需要先判断是否已经有监控页面,需要提示关闭当前监控页面),接着弹出框提示正在执行,最后统一提交到公共函数callByAJax中。这里列举三种提交的典型js代码:
1. 提交MR任务个数固定的MR任务
//evaluateFactorization---
$('#evaluateFactorization_submit').bind('click', function(){
// 检查是否有“MR监控页面”,如果有,则退出,并提示关闭
if(exitsMRmonitor()){
return ;
}
var input=$('#evaluateFactorization_input').val();
var output=$('#evaluateFactorization_output').val();
var userFeatures=$('#evaluateFactorization_userFeatures').val();
var itemFeatures=$('#evaluateFactorization_itemFeatures').val();
// 弹出进度框
popupProgressbar('推荐MR','evaluateFactorization任务提交中...',1000);
// ajax 异步提交任务
callByAJax('cloud/cloud_submitJob.action',{algorithm:"EvaluateFactorizationRunnable",jobnums:'1', arg1:input,arg2:output,arg3:userFeatures,arg4:itemFeatures});
});
// ------evaluateFactorization2 提交MR个数不固定的MR任务
// kmeans---
$('#kmeans_submit').bind('click', function(){
// 检查是否有“MR监控页面”,如果有,则退出,并提示关闭
if(exitsMRmonitor()){
return ;
}
var input=$('#kmeans_input').val();//
var output=$('#kmeans_output').val();//
var clusters=$('#kmeans_clusters').val();//
var k=$('#kmeans_k').val();
var convergenceDelta=$('#kmeans_convergenceDelta').val();
var maxIter=$('#kmeans_maxIter').val();
var clustering=$('#kmeans_clustering').combobox("getValue");
var distanceMeasure=$('#kmeans_distanceMeasure').combobox("getValue");
var jobnums_=parseInt(k); // 一共的MR个数
if("true"==clustering){
jobnums_=jobnums_+1;
}
jobnums_=jobnums_+"";
// 弹出进度框
popupProgressbar('聚类MR','kmeans任务提交中...',1000);
// ajax 异步提交任务
callByAJax('cloud/cloud_submitIterMR.action',{algorithm:"KMeansDriverRunnable",jobnums:jobnums_,
arg1:input,arg2:output,arg3:clusters,arg4:k,
arg5:convergenceDelta,arg6:maxIter,arg7:clustering,arg8:distanceMeasure});
});
// ------kmeans这里把不定MR个数的任务和定MR个数的任务区分开来了,其实是可以不用区分的,因为在返回结果都是一个Map,根据map结果来进行操作的。不过需要在不同的实现中设置标志位(具体参考下面的实现分析)
3 提交非MR任务
$('#upload_submit').bind('click', function(){
var input=$('#upload_input').val();
var output=$('#upload_output').val();
// 弹出进度框
popupProgressbar('数据上传','数据上传中...',1000);
// ajax 异步提交任务
callByAJax('cloud/cloud_submitJobNotMR.action',{algorithm:'Upload',
arg1:input,arg2:output});
});这里要注意MR任务和非MR任务是需要区分的,因为非MR任务使用的是同步模式(这里同步模式不是指aJax的同步,而是指实现方式),即用户点击后,会一直弹出正在处理的提示,然后等后台处理完成,返回结果才会关闭弹窗,同时把结果直接展现在原网页。但是MR的任务会启动多线程,当多线程成功启动后,直接关闭提示框,同时打开MR任务监控页面,开启页面定时刷新任务,向后台获取任务执行情况信息。
callByAJax函数如下:
// 调用ajax异步提交
// 任务返回成功,则提示成功,否则提示失败的信息
function callByAJax(url,data_){
$.ajax({
url : url,
data: data_,
async:true,
dataType:"json",
context : document.body,
success : function(data) {
closeProgressbar();
console.info("close the progressbar,flag:"+data.flag);
var retMsg;
if("true"==data.flag){
retMsg='操作成功!';
if(typeof data.return_show !="undefined"){// 读取文件
var return_id = "#"+data.return_show+"";
// var obj=document.getElementById(data.return_show);
$(return_id).html(data.return_txt);
console.info('defined:'+data.return_show);
}
}else{
retMsg='操作失败!';
if(typeof data.return_show !="undefined"){// 读取文件
var return_id = "#"+data.return_show+"";
$(return_id).html(data.msg);
}
}
$.messager.show({
title : '提示',
msg : retMsg
});
if("true"==data.flag&&"true"==data.monitor){// 添加监控页面
// 使用单独Tab的方式
layout_center_addTabFun({
title : 'MR算法监控',
closable : true,
href : 'monitor/monitor.jsp'
});
}
}
});
}4.2.2 MR实现
所有的MR任务提交到Action后,都会启动一个线程来专门运行MR任务,这样就可以直接返回前台页面,提示任务已经成功提交。
Action中对应的代码如下:
/**
* 提交变jobnum的任务,暂未添加
*
*/
public void submitIterMR(){
Map map = new HashMap();
try {
//提交一个Hadoop MR任务的基本流程
// 1. 设置提交时间阈值,并设置这组job的个数
//使用当前时间即可,当前时间往前10s,以防服务器和云平台时间相差
HUtils.setJobStartTime(System.currentTimeMillis()-10000);//
// 由于不知道循环多少次完成,所以这里设置为最大值,
// 当所有MR完成的时候,在监控代码处重新设置JOBNUM;
HUtils.setALLJOBSFINISHED(false);
HUtils.JOBNUM=Integer.parseInt(jobnums);
// 2. 使用Thread的方式启动一组MR任务
// 2.1 生成Runnable接口
RunnableWithArgs runJob = (RunnableWithArgs) Utils.getClassByName(
Utils.THREADPACKAGES+algorithm);
// 2.2 设置参数
runJob.setArgs(new String[]{arg1,arg2,arg3,arg4,arg5,arg6,arg7,arg8,arg9,arg10,arg11});
// 2.3 启动Thread
new Thread(runJob).start();
// 3. 启动成功后,直接返回到监控,同时监控定时向后台获取数据,并在前台展示;
map.put("flag", "true");
map.put("monitor", "true");
} catch (Exception e) {
e.printStackTrace();
map.put("flag", "false");
map.put("monitor", "false");
map.put("msg", "任务启动失败!");
}
Utils.write2PrintWriter(JSON.toJSONString(map));
} 这里采用统一接口把所有的提交都整合到一个函数中,算法参数采用匿名的方式,不管前台传送了多少个,都用所有的参数来接收。然后使用Java反射来生成实际执行任务的类,并启动多线程。最后返回的map数据根据需要需要设置监控的flag为true(和callByAJax函数中的标识对应)。
所有MR任务都必须实现下面的接口:
/**
* 带有参数的Runnable接口
* @author fansy
* @date 2015-8-4
*/
public interface RunnableWithArgs extends Runnable {
public abstract void setArgs(String[] args);
}该接口有两点需要注意,其一,它继承了Runnable接口;其二,它自定义了一个setArgs函数;
下面来看一个实现,以kmeans算法的调用为例:
/**
* @author fansy
* @date 2015-8-4
*/
public class KMeansDriverRunnable implements RunnableWithArgs {
private String input;
private String output;
private String clusters;
private String k;
private String convergenceDelta;
private String maxIter;
private String clustering;
private String distanceMeasure;
@Override
public void run() {
String[] args=null;
if("true".equals(clustering)){
args=new String[17];
args[16]="-cl";
}else{
args= new String[16];
}
args[0]="-i";
args[1]=input;
args[2]="-o";
args[3]=output;
args[4]="-c";
args[5]=clusters;
args[6]="-k";
args[7]=k;
args[8]="-cd";
args[9]=convergenceDelta;
args[10]="-x";
args[11]=maxIter;
args[12]="-dm";
args[13]=distanceMeasure;
args[14]="--tempDir";
args[15]="temp";
Utils.printStringArr(args);
try {
HUtils.delete(output);
HUtils.delete("temp");
HUtils.delete(clusters);
int ret = ToolRunner.run(HUtils.getConf() ,new KMeansDriver() , args);
if(ret==0){// 所有任务运行完成
HUtils.setALLJOBSFINISHED(true);
}
} catch (Exception e) {
e.printStackTrace();
// 任务中,报错,需要在任务监控界面体现出来
HUtils.setRUNNINGJOBERROR(true);
Utils.simpleLog("KMeansDriver任务错误!");
}
}
@Override
public void setArgs(String[] args) {
this.input=args[0];
this.output=args[1];
this.clusters=args[2];
this.k=args[3];
this.convergenceDelta=args[4];
this.maxIter=args[5];
this.clustering=args[6];
this.distanceMeasure=args[7];
}
}首先,这里需要实现setArgs函数,这个函数就是把匿名的算法参数全部实名化(实际上,这里可以不用这一步操作的,但是为了代码的可读性,还是建议这样做)。接着,在run函数中,根据传进来的算法参数构造MR算法需要使用的算法参数,然后直接提交MR任务即可。
这里需要注意:
1. 当任务运行出错时需要设置标志位,方便在任务监控时,前台向后台获取任务状态信息时,提示错误;
2. 固定个数的MR任务和非固定个数的MR任务的不同点是当非固定个数的MR提前运行完成(比如kmeans算法如果设置了循环次数为10,那么假如当循环次数达到了8次时,其阈值满足条件,退出了循环),那么就要实时更改MR任务的次数(非固定个数MR任务最开始设置任务全部个数是按照最大值来设置的),并设置相关标识,即不用再进行监控。
4.2.3 非MR实现
与MR实现类似,非MR实现的Action函数如下:
/**
* 提交非MR的任务
* 算法具体参数意思对照jsp页面理解,每个实体类会把arg1~arg11 转换为实际的意思
* @throws ClassNotFoundException
* @throws IllegalAccessException
* @throws InstantiationException
*/
public void submitJobNotMR() throws InstantiationException, IllegalAccessException, ClassNotFoundException{
Map map = new HashMap();
INotMRJob runJob = (INotMRJob) Utils.getClassByName(
Utils.THREADNOTPACKAGES+algorithm);
// 2.2 设置参数
runJob.setArgs(new String[]{arg1,arg2,arg3,arg4,arg5,arg6,arg7,arg8,arg9,arg10,arg11});
map= runJob.runJob();
Utils.write2PrintWriter(JSON.toJSONString(map));
return ;
} 所有非MR任务都要实现INotMRJob接口,该接口定义如下:
/**
* 提交非MR任务的基类
* @author fansy
* @date 2015年8月5日
*/
public interface INotMRJob {
public void setArgs(String[] args);
public Map runJob();
} 两个函数分别对应RunnableWithArgs的两个函数。
一个读取HDFS文件的具体实现如下:
/**
* 读取HDFS txt文件
* @author fansy
* @date 2015年8月5日
*/
public class ReadTxt implements INotMRJob {
private String input;
private String lines;
@Override
public void setArgs(String[] args) {
this.input=args[0];
this.lines=args[1];
}
@Override
public Map runJob() {
Map map = new HashMap();
String txt =null;
map.put("return_show", "readtxt_return");
try{
txt = HUtils.readTxt(input, lines, "
");
txt ="文件的内容是:
"+txt;
map.put("flag", "true");
map.put("return_txt", txt);
}catch(Exception e){
e.printStackTrace();
map.put("flag", "false");
map.put("monitor", "false");
map.put("msg", input+"读取失败!");
}
return map;
}
} 4.2.4 结果返回
非MR任务结果返回直接在原网页展示,在callByAJax中判断相应的标志位如果不为空,那么就是需要展示在原网页的,原网页中必须有相应的组件来显示,比如下面的网页代码:
<div id="upload_return" style="padding-left: 30px;font-size: 20px;padding-top:10px;">div>MR的任务则会开启监控,在监控页面展现任务的执行情况。
5. 二次开发
二次开发实际就是在此版本的基础上添加自己的功能而已。一共包含下面几个步骤:
1. 编写测试函数
比如要添加一个fuzzykmeans的算法,那么就在src/test/java里面编写测试函数,如下: 
编写测试函数的主要目的是,研究算法的参数以及输入数据的格式等。
2. 添加json导航栏数据
在tree_data.json中添加对应的算法,如下: 
3. 编写页面
参考1.中的所有算法需要参数来编写jsp页面,如下图: 
4. 编写页面处理js
根据jsp页面中的按钮,来编写按钮的触发事件,如下: 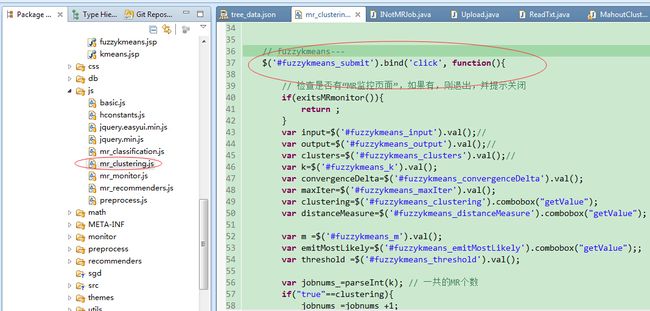
5. 实现请求提交接口实现
编写请求提交接口的实现分为两种,如果是MR任务则实现RunnableWithArgs接口,如果是非MR任务则实现INotMRJob接口即可。如下图所示: 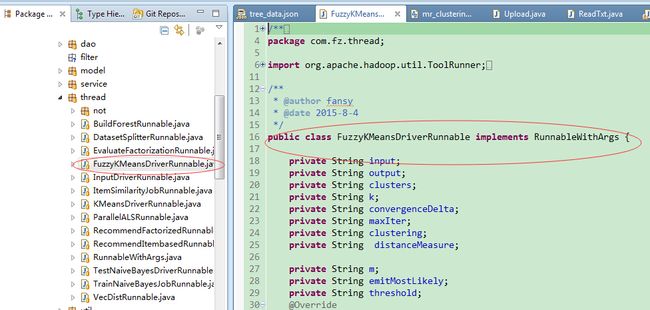
6. 运行项目并测试
打开浏览器,访问刚开发的功能,点击页面中的按钮进行测试,如下: 
6. 项目功能介绍
- Hadoop集群配置连接查看、修改

在这里可以进行集群参数的配置,主要是连接Hadoop集群的参数;
2. 数据构造和查看
文件上传界面如下: 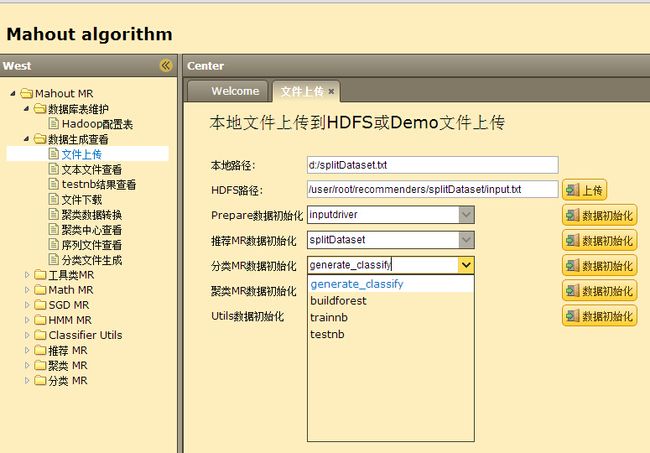
文件上传主要包括两个功能,其一就是把本地文件上传到HDFS文件;其二就是针对各个算法的数据初始化,这里的初始化基本都是把本地文件(这些文件在src/main/resources/data中已经存在)上传到HDFS指定目录,这里关于目录构造可以参考Upload.java文件:
/**
* 数据上传
* 统一命名:
上传本地文件:WEB-INF/classes/data//.
上传HDFS文件:/user/root///input.
* @author fansy
* @date 2015年8月5日
*/
其他的基本是数据查看之类的,最后一个分类数据生成,是针对输入数据需要是序列化的数据,所以这里直接生成序列化数据在HDFS指定的目录即可。
3. 相关Mahout算法
相关MR算法中,页面都有默认的参数,比如: 
这里的输入数据路径是根据前面Upload里面生成的路径是一致的,有些MR算法需要先运行其他MR算法,然后才能运行,这时其输入路径就是上一个MR算法对应的输出了。
7. 总结
- Mahout MR算法调用其实并不难,难在了解算法的输入数据格式、算法的参数设置等;
- 本篇在 MR调用上面其实并没有很多内容,较多的是js的处理以及ssh框架的应用;
- 在MR的监控上面实现的思路也是可以借鉴的;
- 可以git该项目,然后自己编程实现某个算法的全部过程,这样学习起来乐趣更多(建议实现TrainLogistic相关);
- Mahout MR算法已经不再更新,建议可以在Hadoop MR的基础上学习Spark。
分享,成长,快乐
脚踏实地,专注
转载请注明blog地址:http://blog.csdn.net/fansy1990