谈谈我的首个开源项目WeiboSpider(0)——WeiboSpider的总体架构
为什么是微博爬虫?
WeiboSpider,顾名思义就是一个微博的爬虫。去年(2012年)年中的刚开始学习python的时候,我同时在看一本关于自然语言识别的书。对自然语言识别有兴趣是因为看了吴军博士的《数学之美》,而且随着数据挖掘、大数据的兴起,自然语言处理在互联网中会有越来越多的应用。
但学习自然语言处理是需要语料的,特别我感兴趣的是统计的识别方法而不是基于规则的识别方法,这就需要大量的语料训练程序,才能达到好的识别效果。虽然搜狗、百度都有把他们研究用的语料库公开出来,但由于语料库过于庞大,网络传输的可能性不大(所以这两家公司都要求想获取语料库的人邮寄一个1T的硬盘给他们)。
所以我最终选择自己写爬虫获取语料。和大公司提供的语料库不一样,我希望抓取的是微博上的内容。尽管微博上的内容“噪声”很多,对程序的训练会造成很大困难。但是微博的内容更符合一般人日常书写的习惯,特别是SNS网络中的书写习惯,并且微博的内容都是公开的,所以最终选择了开发微博的爬虫。
这是一个纯Python的程序
选择Python作为开发语言其实纯粹是个人喜好,因为那段时间刚好初学Python,想找一个项目练练手。另外是看中了Python较为简洁的语言设计,能稍微减少一点开发时间(毕竟平时工作还是很忙的)。公平地说,这种程序使用不用编程语言编写的差别不见得很大,而且在处理大量数据的情况下,Python并不是一门效率很高的语言,所以真如一开始所说的,选择Python真的仅仅是个人喜好而已。
WeiboSpider总体架构
爬虫是一个要复杂可以像一个无底洞,但要简单也可以很简单的系统。由于是个人学习所用,WeiboSpider指实现了一些爬虫最基本的功能。下图为总体的架构图:
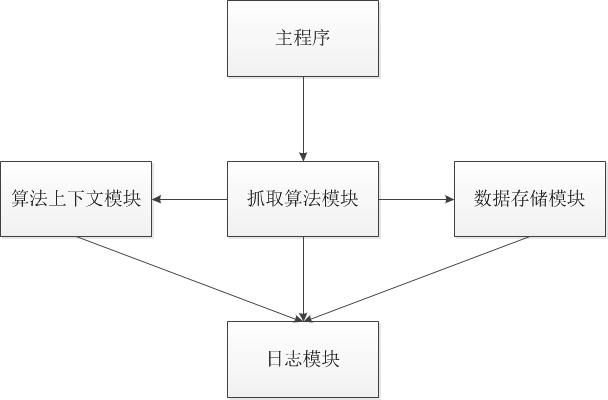
可以看到,WeiboSpider暂时只由4个模块组成(主程序就算了,这仅仅是做调用和一些必要的初始化):
抓取算法模块:这个模块主要实现爬虫的抓取算法,本质上就是一个图的遍历算法,WeiboSpider这个版本采用的是广度优先算法。由于算法模块是一个独立的模块,要切换或优化算法都可以减少对其他模块的影响。
数据存储模块:负责把数据持久化的模块。
算法上下文模块:无论采用何种抓取算法,上下文信息是必不可少的。在上一个版本的WeiboSpider中,没有把上下文的实现独立出来,导致了修改上下文实现非常困难,这个在下面会详细说。
模块间的交互
WeiboSpider模块间的交互大部分都不采用直接交互的方式,比如如下代码:
class SinaWeiboAPI(object):
def __init__(self, weiboAPIModule, virtualBrowser, appKey, appSecret, RedirectUri, userName, password):
self._apiClient = weiboAPIModule.APIClient(app_key=appKey, app_secret=appSecret, redirect_uri=RedirectUri)
sinaWeiboAutoAuth(self._apiClient, userName, password, virtualBrowser)所有与SinaWeiboAPI类交互模块(访问微博的API)和对象(virtualBrowser对象)都在构造函数中通过参数的形式传入到对象内部。这样能有效避免这个类与某个模块的具体实现间的耦合,如果WeiSpider某个模块需要更换,比如某天我发现我现在用的虚拟浏览器(virtualBrowser)性能不行,并且找到了更好的,我可以轻易地把这个模块替换掉,而不需要更改SinaWeiboAPI类的代码,需要修改的仅仅是创建SinaWeiboAPI对象的代码(通常是主程序)。
这种交互方式还有一个好处就是能方便单元测试。根据单元测试的要求,被测模块是不应该与其他模块有交互的,因为这样会增加测试的复杂性,和设计测试用例的难度。如果被测模块必须与其他模块交互才能正常运行,那么交互的模块就应当由桩程序或mock程序代替。说到这里这种设计对单元测试的好处估计已经呼之欲出了。(P.S. 当然对于Python来说,这并不是注入桩程序和mock程序唯一的方法,但这是一种较为简单和常用的单元测试友好的设计,无论动态语言还是静态语言都适用。关于单元测试,将来再写一篇文章来说吧)。
实现这种设计的时候,Python众生皆对象的特性给了我很大的方便。不管是包、模块、对象还是仅仅只是一个函数,都能作为参数传入到构造函数,这让我可以控制到任意粒度的耦合,这对于很多静态语言都是很难做到的。
让关系型数据库见鬼去吧
对于爬虫程序这种大数据量的数据存储,然后后续我还需要读取进行分析的程序,应该不会有人建议我用文件作为持久化存储方式吧?但这次做这个程序之初我就没有考虑到用关系型数据库。首先,作为学习目的开发的程序,能新技术当然不会再用自己熟悉的技术了,哪怕开发效率和质量都可能无法保证;其次,WeiboSpider对于数据间的关联关系和事务要求都并不高,但却有相当高频率的读写操作,这就使得我用关系型数据库理由并不是很强烈,而NoSQL数据库的高效率读写,高扩展性,轻量级等特性都让我更有理由选择它。
第一个版本的WeiboSpider是使用MongoDB作为持久化数据库的。MongoDB作为文档型NoSQL数据库,更适合WeiboSpider这种数据量较大的应用程序的。但第二版本的WeiboSpider改用了Redis作为持久化数据库,因为在做第一版本WeiboSpider的以后,我意识到我需要一个有一定持久化能力,且可以分布式访问的缓存系统用作上下文管理。这时候Redis进入了我的视野。Redis的数据无论读写都是在内存中进行的,这保证了比一般数据库更高的读写效率,并且通过后台方式定期把数据持久化到硬盘中,做到数据的持久化,可以说是一个既能用作分布式缓存,也能作为一般数据库使用的NoSQL数据库。
所以我最终选择了使用Redis作为第二个版本的WeiboSpider的上下文管理载体+数据库。当然Redis在这个场景下不是作为数据库最好的选择,或许某一天我还是会把数据库换回到MongoDB吧。
总 结
WeiboSpider实际上还在开发当中,还不算是一个能运行的程序。写博客记录仅仅是因为想把想法记录下来以免自己忘记了,因为发现几个月不写这个程序的代码,突然又继续开始写的时候,自己要相当长时间的warm up才能想起来该怎么写。
既然这个是开源项目,也希望看到这篇博客的,而且又有兴趣的人也参与这个项目中,Github上的地址:https://github.com/phospher/WeiboSpider