【排序三】插入排序 (直接插入排序,二分插入排序,希尔排序)
转载
正文
回到顶部
0. 数据结构图文解析系列
| 数据结构系列文章 |
|---|
| 数据结构图文解析之:数组、单链表、双链表介绍及C++模板实现 |
| 数据结构图文解析之:栈的简介及C++模板实现 |
| 数据结构图文解析之:队列详解与C++模板实现 |
| 数据结构图文解析之:树的简介及二叉排序树C++模板实现. |
| 数据结构图文解析之:AVL树详解及C++模板实现 |
| 数据结构图文解析之:二叉堆详解及C++模板实现 |
| 数据结构图文解析之:哈夫曼树与哈夫曼编码详解及C++模板实现 |
| 数据结构图文解析之:直接插入排序及其优化(二分插入排序)解析及C++实现 |
| 数据结构图文解析之:二分查找及与其相关的几个问题解析 |
1. 插入排序简介
插入排序是一种简单直观的排序算法,它也是基于比较的排序算法。它的工作原理是通过不断扩张有序序列的范围,对于未排序的数据,在已排序中从后向前扫描,找到相应的位置并插入。插入排序在实现上通常采用就地排序,因而空间复杂度为O(1)。在从后向前扫描的过程中,需要反复把已排序元素逐步向后移动,为新元素提供插入空间,因此插入排序的时间复杂度为O(n^2);
回到顶部
2. 直接插入排序图解
一般来说,插入排序都采用在数组上就地排序实现。具体算法描述如下:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
假设我们要对数组{12,4,5,2,6,14}进行插入排序,排序过程为: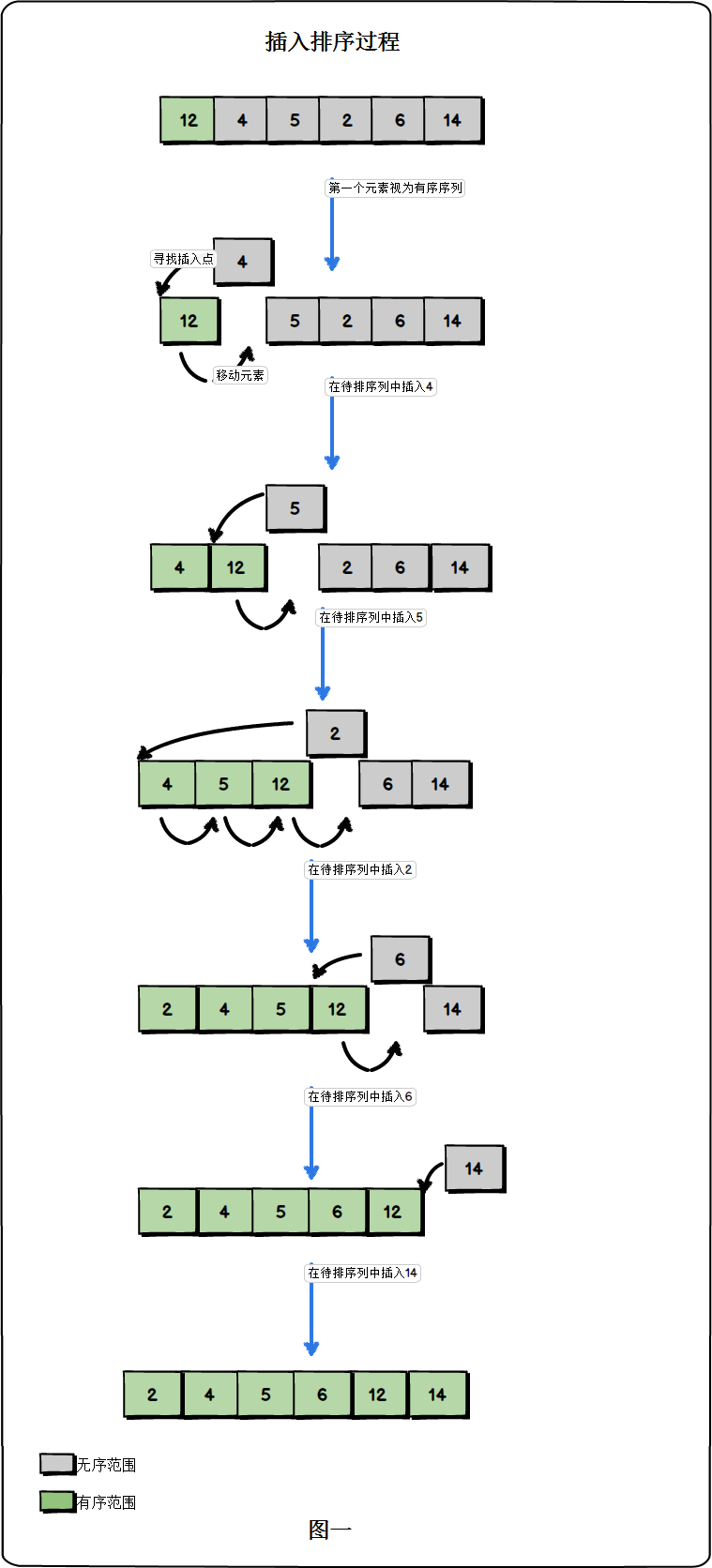
2.1. 代码实现
template
void InsertSort(T array[],int length)
{
if (array == nullptr || length < 0)
return;
int i, j;
for (i = 1; i < length; i++) //数组下标从0开始存储,第一个元素有序,所以从第二个开始处理
{
if (array[i]temp; j--) //元素后移
{
array[j + 1] = array[j];
}
array[j+1] = temp; //在合适的位置上出入元素
}
}
} 2.2. 复杂度分析
- 插入排序的最好情况是数组已经有序,此时只需要进行n-1次比较,时间复杂度为O(n);
- 最坏情况是数组逆序排序,此时需要进行n(n-1)/2次比较以及n-1次赋值操作(插入);
- 平均来说插入排序算法的复杂度为O(n^2)。
总结:
- 插入排序不适合对大量数据进行排序应用,但排序数量级小于千时插入排序的效率还不错,可以考虑使用。插入排序在STL的sort算法和stdlib的qsort算法中,都将插入排序作为快速排序的补充,用于少量元素的排序(通常为8个或以下)。
- 直接插入排序适合基本有序的情况
直接插入排序采用就地排序,空间复杂度为O(1).
2.3. 稳定性
直接插入排序是稳定的,不会改变相同元素的相对顺序。
回到顶部
3. 二分查找插入排序
上面的插入排序实现中,为了找到元素的合适的插入位置,我们采用从后到前遍历的顺序查找进行比较,为了减少比较的次数,我们可以换种查找策略:采用二分查找。
我们定义一个二分查找函数,函数返回插入位置的下标:
/*二分查找函数,返回插入下标*/
int BinarySearch(int *a, int start, int end, int key)
{
while (start <= end)
{
int mid = (start + end) / 2;
if (key= 0 && j >= insertIndex; j--)
{
srcArray[j + 1] = srcArray[j];
}
srcArray[j + 1] = temp;
}
} 3.2. 复杂度分析
我们这个二分查找的算法并不会因为等于某一个值而停止查找,它将查找整个序列直到start<=end条件不满足而得到插入的位置,所以对于长度为n的数组来说,比较次数为log2n ,时间复杂度为O(log2n)。二分插入排序的主要操作为比较+后移赋值,则:
- 最坏情况:每次都在有序序列的起始位置插入,则整个有序序列的元素需要后移,时间复杂度为O(n^2)
- 最好情况:待排序数组本身就是正序的,每个元素所在位置即为它的插入位置,此时时间复杂度仅为比较时的时间复杂度,为O(log2n)
- 平均情况:O(n^2)
空间复杂度上, 二分插入排序也是就地排序算法,它的空间复杂度为O(1).
3.3. 稳定性
二分插入排序是稳定的。元素的相对顺序在排序后不会被改变。
4.希尔排序
参考:图解排序算法(二)之希尔排序
希尔排序是希尔(Donald Shell)于1959年提出的一种排序算法。希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序,同时该算法是冲破O(n2)的第一批算法之一。本文会以图解的方式详细介绍希尔排序的基本思想及其代码实现。
4.1. 基本思想
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
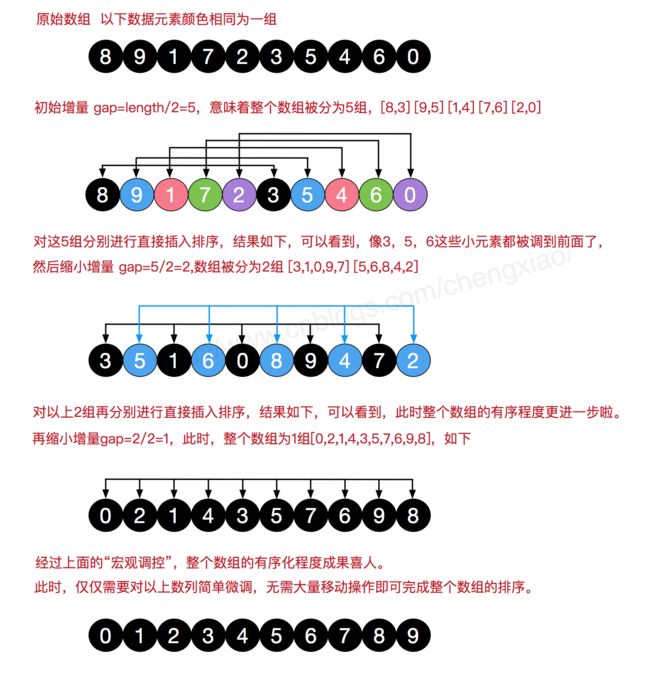
简单插入排序很循规蹈矩,不管数组分布是怎么样的,依然一步一步的对元素进行比较,移动,插入,比如[5,4,3,2,1,0]这种倒序序列,数组末端的0要回到首位置很是费劲,比较和移动元素均需n-1次。而希尔排序在数组中采用跳跃式分组的策略,通过某个增量将数组元素划分为若干组,然后分组进行插入排序,随后逐步缩小增量,继续按组进行插入排序操作,直至增量为1。希尔排序通过这种策略使得整个数组在初始阶段达到从宏观上看基本有序,小的基本在前,大的基本在后。然后缩小增量,到增量为1时,其实多数情况下只需微调即可,不会涉及过多的数据移动。
我们来看下希尔排序的基本步骤,在此我们选择增量gap=length/2,缩小增量继续以gap = gap/2的方式,这种增量选择我们可以用一个序列来表示,{n/2,(n/2)/2...1},称为增量序列。希尔排序的增量序列的选择与证明是个数学难题,我们选择的这个增量序列是比较常用的,也是希尔建议的增量,称为希尔增量,但其实这个增量序列不是最优的。此处我们做示例使用希尔增量。
4.2. 代码实现
在希尔排序的理解时,我们倾向于对于每一个分组,逐组进行处理,但在代码实现中,我们可以不用这么按部就班地处理完一组再调转回来处理下一组(这样还得加个for循环去处理分组)比如[5,4,3,2,1,0] ,首次增量设gap=length/2=3,则为3组[5,2] [4,1] [3,0],实现时不用循环按组处理,我们可以从第gap个元素开始,逐个跨组处理。同时,在插入数据时,可以采用元素交换法寻找最终位置,也可以采用数组元素移动法寻觅。希尔排序的代码比较简单,如下:
//希尔排序Shell Sort
//杨鑫
#include
#include
void ShellSort(int a[], int length)
{
int increment;
int i,j;
int temp;
for(increment = length/2; increment > 0; increment /= 2) //用来控制步长,最后递减到1
{
// i从第step开始排列,应为插入排序的第一个元素
// 可以先不动,从第二个开始排序
for(i = increment; i < length; i++)
{
temp = a[i];
for(j = i - increment; j >= 0 && temp < a[j]; j -= increment)
{
a[j + increment] = a[j];
}
a[j + increment] = temp; //将第一个位置填上
}
}
}
int main()
{
printf("==============希尔排序===============\n\n");
int i, j;
int a[] = {5, 18, 151, 138, 160, 63, 174, 169, 79, 200};
printf("待排序的序列是: \n");
for(i = 0; i < 10; i++)
{
printf("%d ", a[i]);
}
ShellSort(a, 10);
printf("\n排序后的序列是: \n");
for(j = 0; j < 10; j++)
{
printf("%d ", a[j]);
}
printf("\n");
return 0;
}
稳定性:不稳定