自动化测试(转)
实力推荐:基于Python的互联网软件测试开发
一、自动化基本技术原理
1 概述
在之前的文章里面提到过:做自动化的首要本领就是要会 透过现象看本质 ,落实到实际的IT工作中就是 透过界面看数据。
掌握上面的这样的本领可不是容易的事情,必须要有扎实的计算机理论基础,才能看到深层次的本质东西。
PS:
本文已经收入合集:《基于python的互联网软件测试开发(自动化测试)-全集合》,欢迎访问的查看:
基于Python的互联网软件测试开发
2 应用软件逻辑结构
数据库应用系统 可能是最典型的网络应用程序了,关于它的软件架构如下:
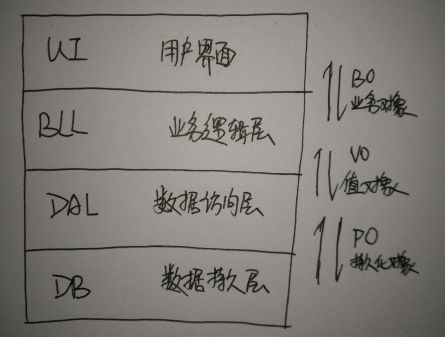
一般在逻辑上分为4层:
-
用户界面层 UI
为终端用户提供交互的人机界面
-
业务逻辑层 BLL
将数据库抽象出来的对象进行拼接成具体的业务逻辑对象,并对之进行流程组织
-
数据访问层 DAL
对DB层做的ORM,让上层应用程序以对象的方式操控数据库
-
数据持久层 DB
存储数据,对数据进行持久化,不同的客户端进行数据共享
在传统的 C/S 架构下应用程序(例如,Windows下的客户端应用程序),一般都是一台中央数据库服务器( DB ),然后对应N台客户端(DAL-BLL-UI )。
对于 初级测试人员 来说,可能对软件的理解只能停留在 UI 层,于是在测试时候能做到的事情就是:日复一日,年复一年地用鼠标 点点点了。
3 互联网软件架构
在前一部分里面提到的应用软件的基本架构,虽然是在 “C/S” 时代提出来的,但是后面却一直延续到现在 。直到今天最普遍的 “ABC/S” 模式:
- App/Server
- Browser/Server
- Client/Server
其实本质上就把UI这一层放在客户端,把UI以下放在Server端。
客户端在不同的平台下面有不同的表现形式,就形成了现在流行的所谓的 “ABC/S” 模式的架构,这个基本上已经成为目前的互联网产品的标配了。具体的架构如下:
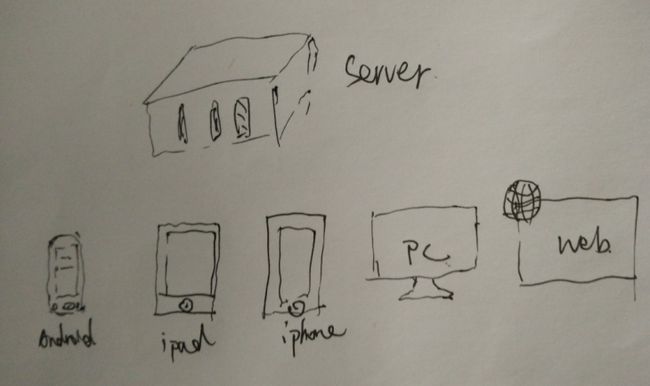
服务器端和客户端之间采用 Http/Https 的通讯协议,数据交换的格式为 Xml/Json 格式。
基于以上模式之后,软件测试的方法论就发生了一些变化:
- 有了 性价比 最高的“基于于通讯编码格式的接口测试”,属于花20%就能解决80%的工作
- 接口测试完全可以进行自动化,而且不必强制和开发项目使用相同的语言,可以统一使用效率较高的脚本语言
- 接口 天然就具有稳定性的需求,所以自动化测试项目不会存在反复折腾的现象
- 接口测试人员成为了众多平台之间的 裁判员
- 接口规范来自设计文档,可以实行 设计产生测试,测试驱动开发 的规范模式
有了抽象成数据的能力之后,那么很多看到的东西就可以进行合理的等价转换了:
-
web页面背景的是红色
等价于:背景元素的background的颜色属性是 #FF0000
-
按钮上显示的字为"Submit"
等价于:按钮元素的value值为 Submit
-
用户执行一次充值活动充了20块钱,他的账号上就多了20元
等价于:以20为参数调用充值接口,再对比前后两次调用账号查询的接口,相差刚好是充值的参数值
在数据层次编程进行比较就变得很容易了,因为这些都是计算机擅长处理的领域了,自动化也很自然地实现了。
4 更底层的原理
前面讲到了对把软件项目从看到的具体的界面往底层一点抽象成数据的方法。其实还有一些更底层,更绝的,对软件的数据还可以更底层一点和物理世界建立关联(这已经不好用“抽象”或者“具象”来描述了)。
本部分的内容,已经和应用软件的测试的话题有点扯远了,纯粹就当科普吧。
从更广泛的角度来看一个计算机系统,它给人的体验上本质上是做了如下的处理:

人的所有的直观体验都是来自于对模拟量(物理量)的体验,人的交互输入也是来自于模拟量的输入。
人敲击键盘向计算机系统输入文字,键盘将不同一键位产生的脉冲电流传入计算机系统,计算机系统通过芯片和驱动,将这些电流信号转化成数字信号,然后交付数字芯片处理。这样人就完成了 信息的输入 。
计算机系统对这些数据进行计算,存储,传输等等,最后在LCD显示器上通过点亮不同位置的点阵,以形成光学的模拟量输出,传送到人的眼睛里面,人就完成了 信息的获取 。
以上的例子可以简化为:力学物理量产生电学物理量进行输入,计算机数字系统处理后,光学物理量进行输出。
对于计算机系统,输入和输出都是多样的:
-
输入装置
各种传感器都可以作为输入的主力,比如现在蓬勃发展的智能硬件,以及炒得火热的 物联网。
-
输出装置
除了光学的LCD显示器,还有声学的扩音器,还有滚动的轮式机械力学,还有人形走路的机械手臂力学设备。
这些东西都已经是现在互联网行业很流行的元素了。
由于电子技术和通讯领域往往检测的都是物理量,肉眼是很难量化的,所以测试门槛会很高,但是各种检测仪器反而发展得相当好,自动化程度相当高。反观IT行业的上层的应用软件层,人却都过多的依赖于人工去操作,肉眼去观察了,反而忽视了自动化,导致测试行业一直人员素质不高,技术实力太弱,这显然是很不可取的,至少是很不符合目前软件工程行业的时代需求的。
5 小结
本文对应用软件进行了逻辑上的分层,来阐述了软件自动化测试和基本原理,在文章的后半部分对目前流行的 智能硬件 所涉及的电子技术的自动化测试也进行了简单的探讨,希望能够给从来 自动化测试的人也有一点启发。
后面的系列文章将从技术层次来落地这些理论。
总结起来,对于想入这行而且想有深入发展的人,有如下几个结论和建议:
- 软件的本质不是界面而是数据
- 要了解软件的本质,必须必须要有良好的计算机基础
- 从事互联网行业的人可以熟悉linux,尽早建立这种 软件即数据 的世界观
- 接口做自动化测试是最投入回报比最高的(来自Google的工程师的观点)
- 要想做好自动化测试,必须有软件开发能力和系统的设计能力
写到这里,最后容我 “安利” 一下 Linux ,因为相比 MacOS 和 Windows 系统,Linux 在界面这一块做得不太好,但是却有强大的CLI交互,支持强大的脚本编写,对于实现自动化是很有帮助的。
二、自动化框架及工具
1 概述
手续的关于测试的方法论,都是建立在之前的文章里面提到的观点:
- 功能测试不建议做自动化
- 接口测试性价比最高
- 接口测试可以做自动化
后面所谈到的 测试自动化 也将围绕着 接口自动化 来介绍。
本系列选择的测试语言是 python 脚本语言。由于其官方文档已经对原理有了比较清楚的解释,本文就不做一些多余的翻译工作了。偏向于实战部分,而且为了偏向实战,也会结合 IDE 工具和项目组织来进行讲解。
理由如下:
- 脚本语言,开发和迭代的效率极高
- 第三方的扩展库极多,有很我现成的工具可以使用
在正式进入到 自动化测试 的领域之前,先要建立这样的价值观。在Google内部工程师发布的软件测试的出版物里面提到:
“软件的自动化测试是有成本的,而且成本不低,基本上相当于在原有的 功能开发工程 的基础上再建立一个平行的 测试开发工程 ”。
也就是说,如果你对自动化测试有你的期望值,那么就肯定是要付出相应的代价和精力的。好的东西也是需要优秀的人花大量的时间去完成的。
本文已经收入合集:《基于python的互联网软件测试开发(自动化测试)-全集合》,欢迎访问的查看:
基于Python的互联网软件测试开发
2 PyUnit测试框架
使用 python 作为自动化编程语言,那么就自然的使用 pyunit 作为自动化测试框架了。
如下部分的内容主要来自于 pyunit 的官方文档,本文仅仅做了一些翻译和结构上的简单调整。这部分属于测试框架的基本原理和概念部分,在进行代码编写前,有必要进行了解。
python的单元测试框架 PyUnit,可以认为是 Java 语言下的单元测试框架 JUnit 的 Python 语言实现版本,甚至其作者之一 Kent Beck 就是 JUnit 的作者。
unittest要达到如下目标:
- 支持自动化测试
- 让所有的测试脚本共享 开启(setup) 和 关闭(shutdown) 的代码
- 可以通过集合(collections)的方式来组织测试用例脚本
- 将所有的测试脚本从测试报告框架中独立出来
为了达到以上目标,unittest支持如下几个重要概念:
-
测试装置(test fixture)
为一个或者多个测试用例做一些准备工作,例如:连接一个数据库,创建一个目录,或者开启一个进程
-
测试用例(test case)
测试用例是测试行为的最小单元,通过对一些输入输出值的对比来进行测试检查
-
测试套件(test suite)
将 测试用例 或者 测试用例集合 聚合组织起来的集合。可以批量执行一个测试套件内所有的测试用例
-
测试执行器(test runner)
组织安排测试脚本执行活动的组件。测试执行器通过一些图形界面,文本界面或者返回一些特殊的值来展示测试脚本的测试结果。主要用于生成测试报告
3 基本示例
如下示例也来自于官方文档 basic_demo.py:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|
虽然官方文档里面介绍了几种组织测试用例脚本的方式:
- 独立测试函数
- 单用例测试类
- 多用例测试类
不同的编写形态,会有不同的组织方式,具体的可以看官方文档。本文作者研究过官方文档后,最喜欢第三种方式 多用例测试类,也就是上面基本示例的方式,这种方式具有如下特点:
- 测试类 继承于 unittest.TestCase
- 一个测试类可以管理多个 测试脚本函数
- 测试脚本函数名称需要以 test_ 开头
- 一个测试类里面的所有的测试函数共享 setUp和tearDown函数
在控制台中运行此程序:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
前面的基本例子的 main 函数采用的最简单的方式,直接运行所有的测试用例,并生成默认的文本报告。其实只需要对调用函数做一些简单的修改,可以将这些测试用例进行合理组织,并获取其实有用的数据信息,以便和信息系统进行集成,形成较好的扩展。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
运行后生成的输出为:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
|
显然上面的输入结果已经将测试的结果进行了统计,这些数据都是一次测试活动中的重要指标,这些数据可以入库,和测试信息管理系统集成,后期生成仪表盘或者统计报表,形成稳定和产品测试线路图,这些都是和开发相关的了,在此不再多叙述了。
结合上面的具体例子,我们也可以找到上一节的理论部分对应的具体实现对象:
-
测试装置(test fixture)
由setUp函数来做初始化工作,由tearDown做销毁工作
-
测试用例(test case)
对应TestCase类,或者更细化的对应里面的测试脚本函数
-
测试套件(test suite)
对应TestSuite类
-
测试执行器(test runner)
对应TextTestRunner类
4 IDE工具
既然需要开发代码的生产力,那么就需要介绍一款IDE工具-- Pycharm。不可否认,它是目前最专注/专业的 Python 语言的 IDE 了。在对Pyunit 也有比较好的支持。
主要支持如下:
-
可视化的编程开发(这是IDE的基本特点)
-
对测试结果进行可视化的展示
-
导出生成HTML的测试报告
-
可视化控制用例执行(这个在开发调试阶段很方便,可以方便控制指定代码单元运行)
- 让一个目录下的所有用命执行
- 让单个文件内所有用例执行
- 让单个文件内的单个用命执行
4.1 运行和调试
Pycharm 对测试脚本提供了灵活的运行和调试支持。
通过pycharm,开发人员可以不用编写main函数,就可以实现如下功能:
- 运行一个文件下所有的测试类
- 运行一个测试类的所有测试脚本
- 运行一个测试类的某个测试脚本
其中 "运行一个测试类的某个测试脚本" 比较有用,适合在开发阶段快速地对单个脚本进行开发和运行调试。
使用方法:
- 将光标移动到测试函数内部
- 按下运行快捷键 ctrl+shift+F10 (Eclipse快捷键方案)
如果要断点调试,则使用Debug模式,即可对单个函数运行和断点调试了。
当然,也可以不必借用IDE,而通过对testSuit操作,也可以实现以上功能,但是IDE却提供了更灵活直接的选择。这只是一些IDE使用技巧,也不多述了。
4.2 结果可视化
对于前面提到的例子,如果选择在IDE中运行此程序,会看到如下效果:
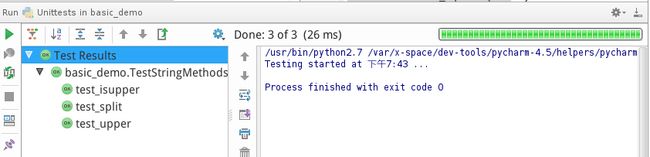
可以看到全部运行通过。如果刻意将其中一个弄成不通过的,则会显示如下的结果:
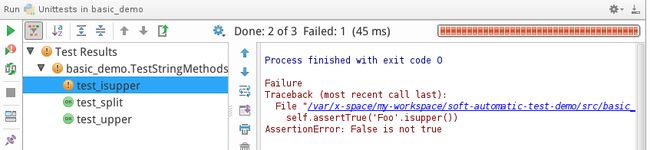
4.3 生成测试报告
Pycharm也提供了测试结果报告的导出功能,在测试结果显示框上的一个功能按钮上。

导出结果如下:
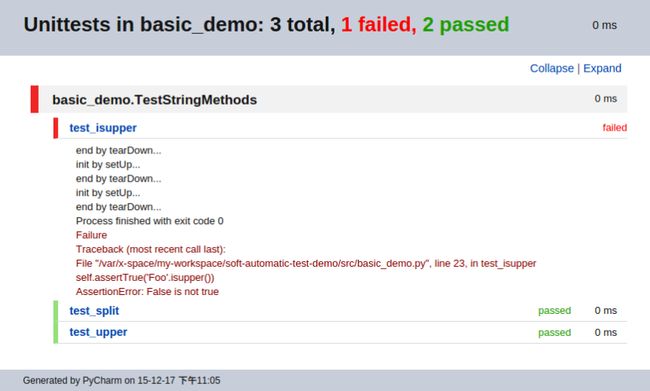
当然,如果不考虑和信息系统集成,不考虑后续的仪表盘和测试统计工作,仅仅只是要生成报告,这个功能已经足够了。
一般情况下,做自动化测试和开发,上面的那些那些技能已经完全能够满足要求了,接下来要做的事情就是利用各种计算机基本知识,面对不断增加的业务需求,而不断地增加测试用例脚本了。
功能开发项目,原理都很简单,但是随着量的增加,都会形成规模,测试开发工程也是一样。
5 项目组织
之前对测试用例的 开发调试态 的工具进行了介绍。但是如果真正的要纳入到 持续集成 的自动化体系,就显然不能依赖于 IDE 了。而是使用python 语言的组织和调用方式了,比如:要有 __main__ 函数来作为执行入口,等等。
详细的技术实现细节,在后面有机会,将再会写相应的文章进行介绍。
通过脱离IDE的项目组织方式,有如下优点:
- 可以通过事件触发来执行所有脚本(能够成为 持续集成 流水线的一环节)
- 可以将数据全部提出并进行自定义加工和处理(和测试信息系统集成,为质量分析系统提供数据源)
6 测试平台
关于如何自动化生成测试报告这个测试产物,现在有一些平台能够提供接口调用及报告展示和分享功能,详情参考:
http://www.jianshu.com/p/c5fa76cf87db

7 小结
本小部分的内容,主要是讲基于 python 语言的 自动化测试框架 pyunit的一些设计思想和基本使用示例。其实工具的使用方法很简单,但是如何利用好这些工具来进行软件生产,则需要其它的计算机技能了,在后续的文章中将会从工程方面和技术方面来对此框架的应用进行深入的扩展。
三、使用第三方python库技术实现
1 概述
关于测试的方法论,都是建立在之前的文章里面提到的观点:
- 功能测试不建议做自动化
- 接口测试性价比最高
- 接口测试可以做自动化
- 做好接口自动化,一定要有透过界面看到数据本质的能力
后面所谈到的 测试自动化 也将围绕着 接口自动化 来介绍。
2 可测试架构
目前互联网行业流行的“一服务,多客户端”的架构是一种 可测试性好 的架构,架构图如下:
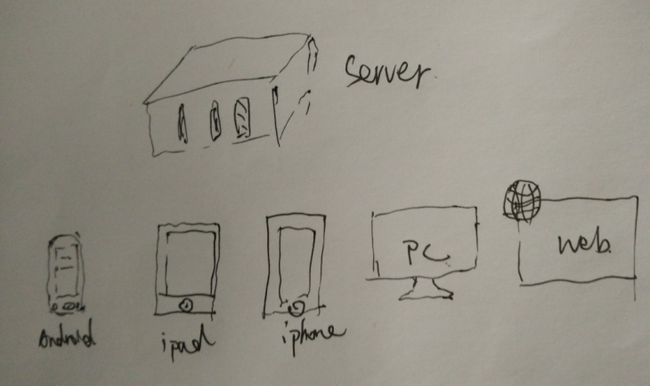
- 服务器和客户端采用Http(或者WebSocket)的方式进行通讯
- 数据交换的格式一般是Json(或者XML)
- 因为下游设备众多,所以服务端接口有很强的稳定性要求
3 自动化技术实现
基于如上特点,此系统的接口自动化测试简化表述,就是需要做如下事情:
- 使用脚本对接口进行Http请求
- 对返回值解析
- 按照设计文档进行判定
- 以项目的方式组织测试脚本形成自动化测试项目
当然,以上纯粹是从技术的角度来阐述问题,如果要和具体的项目结合起来 ,还需要设计不同的步骤和数据来满足不同的业务逻辑需求。
对于如上4个目的,有如下几个框架或者工具可以实现:
-
requests
一个Http请求库,号称是让Http的请求对人更友好,此框架也确实达到此目的了。
-
json
python提供的对json和python数据类型的转化库
-
pyunit
pyunit自动化框架提供了大量的assert断言方法来自动化进行数据逻辑判定
-
pycharm
作为一个强大的IDE,其在项目组织方面的表现也同样是极其出色的
关于 pyunit 和 pycharm 在本系列文章的上一节里面已经进行了介绍,此处不再重复介绍,本文的重点则是python的两个和http通讯及数据解析相关的库:requests库 和 json库 。
4 json
4.1 基本介绍
中文官方主页:
| 1 |
|
关于JSON的使用介绍,目前已经不言而喻。虽然在好多年前,曾经有XML和JSON在 数据编解码 领域平分秋色的说法,但是这么多年过去后,JSON的势头越来越好,而XML的声音则越来越小。
关于JSON的定义,引用官网的原文 [1]:
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。 易于人阅读和编写。同时也易于机器解析和生成。 它基于JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一个子集。 JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等)。 这些特性使JSON成为理想的数据交换语言。
目前JSON显然已经成为了互联网上字符型数据交换的标准编解码的中坚力量,作为互联网的开发人员,是很有必要了解它,运用它的。
JSON作为一种字符串的编码和解码规划,是和语言无关的,JSON官网 [1] 上有各种语言的。各种语言(Java/Php/C#/C/C++/Python/R/Ruby等等)都有自己的实现方式,这些也都可以参考
4.2 python库
本文的主打语言是Python语言,所展开的内容也是和Python语言相关,在JSON官网 [1] 上提供了如下几种Python语言的JSON库:
- The Python Standard Library.
- simplejson.
- pyson.
- Yajl-Py.
- ultrajson.
- metamagic.json.
一般情况下,都使用第一个: The Python Standard Library(Python标准库)
官方文档地址:
| 1 |
|
主要的功能就是:JSON编码和解码。
主要函数:
解码函数(装载):将字符流转化为json对象
- loads: 载入字符串变量
- load:载入文件流
编码函数(卸载):将json对象转化为字符流
- dumps:输出到字符串变量
- dump:输出到文件流
以上的几个接口容易混淆记忆,引处提供一个辨识技巧:后面带有s结尾(loads,dumps),都是对字符串变量 str 的处理。
一般情况下,loads,dumps使用得最多,因为大部分的程序运算都是内存运算,即主要是对字符串变量进行处理,以下是官网的示例。
字符串解码:
>>> import json
>>> json.loads('["foo", {"bar":["baz", null, 1.0, 2]}]')
[u'foo', {u'bar': [u'baz', None, 1.0, 2]}]
>>> json.loads('"\\"foo\\bar"')
u'"foo\x08ar'
字符串编码:

>>> import json
>>> json.dumps(['foo', {'bar': ('baz', None, 1.0, 2)}])
'["foo", {"bar": ["baz", null, 1.0, 2]}]'
>>> print json.dumps("\"foo\bar")
"\"foo\bar"
>>> print json.dumps(u'\u1234')
"\u1234"
关于python标准数据类型和Json的数据类型之间转化的对应关系请见官网 [2]
| [1] | (1, 2, 3) JSON官网 |
| [2] | Python的Json编码解码数据对应表 |
5 requests
5.1 基本介绍
官方主页:
| 1 |
|
requests库是一个专门封装的,对用户极其友好的一个Http请求库,其目的就是为了让python下面的Http请求变得更简单,而且它确实也达到它的目的了。
安装方法:
| 1 |
|
5.2 使用示例
目前的一般的Web应用程序都是基于get或者post请求,对于这两种Http请求,requests库都提供了十分优雅的解决方案。
最基本的get请求
# coding:utf-8
import requests
__author__ = 'harmo'
def get_demo():
"""
requests 的get方法演示,不带参数
by:Harmo
:return:
"""
url = 'http://www.baidu.com'
res = requests.get(url)
print res.url
print res.status_code
if __name__ == '__main__':
get_demo()
运行结果:
| 1 2 |
|
带参数的get请求:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.get('http://httpbin.org/get', params=payload)
带参数的post请求:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("http://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
6 综合示例
再结合一下pyunit的判断库,就可以根据如下流程,做一个最简单的接口自动化测试脚本:
- 根据文档准备好请求参数
- 对指定的http接口进行requests请求
- 对返回的字符串进行json解析
- 使用pyunit的assert函数进行判定
- 生成相应的测试报告,导出或者和信息系统对接
下面是对一个用户登录的接口进行测试,按照设计文档,此接口如果登录成功,则返回的字符格式是:
{
"code":200,
"msg":"",
"data":{
"token": "382998dafa5143fd8a38c535be0d1502"
}
}
如果登录失败,则返回如下值:
| 1 |
|
则相应的测试脚本代码为
def test_admin_user_login(self):
"""
测试用户登录
by:Harmo
:return:
"""
url = "%s%s" % (self.base_url, '/task/admin-user-login/')
params = dict(
user='admin',
password='222222',
)
res = requests.post(url, data=params)
print res.text
res_dict = json.loads(res.text)
self.assertEqual(res_dict['code'], 200)
运行结果:
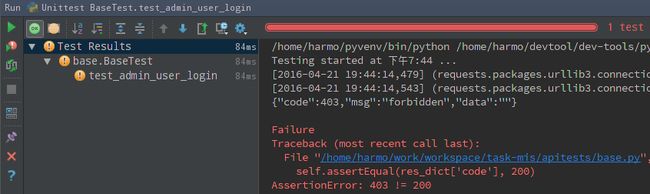
通过上面运行结果的提示,我们可以看出,指定的数据输入经过服务端接口后,并没有返回我们期望的值。这个时候,我们就可以排查是不是服务端的接口出问题了,或者是谁修改了测试数据,导致结果不符合预期。
7 小结
本小部分的内容,主要是讲如何利用 requests库 和 json库 来轻松构建Http接口自动化测试的项目。基本上如果掌握了如上技能,测试开发人员就具备了自动化脚本开发的能力了,后面主就是结合具体的项目需求来进行逻辑设计和数据准备了。
只需要这一步,你就迈入了自动化测试之门了,恭喜。
聚沙成塔,无数的上文提到的接口自动化测试脚本,就可以汇集成一个自动化化测试项目,而此自动化测试项目则是 持续集成,快速迭代必备条件,最后作为测试人员也能成为整个项目推进中很重要的一环了。
转载自:python自动化测试