itext 根据模板 生成pdf 多行数据
前言:基于 html + ccs + itext + 字符串替换完成的。简单,依赖的 jar 少...
根据 pdf模板 生成 pdf ,
1. 不能有循环的数据(可能有,但我并没有找到);
2. table 中的文字无法自适应(可能有,但我并没有找到)。
废话完毕了, 先看预览效果吧。
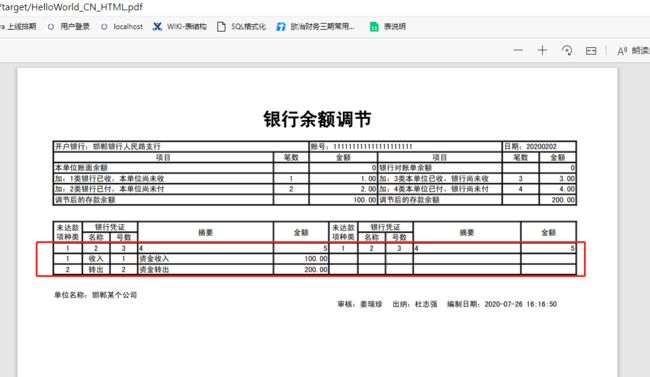
红框中的内容,就是 list 数据,长度不固定,无法用 PDF 模板生成。
下面是代码:
pom.xml文件
com.itextpdf
itextpdf
5.5.10
com.itextpdf.tool
xmlworker
5.5.6
java 文件
package org.duzq;
import com.itextpdf.text.Document;
import com.itextpdf.text.DocumentException;
import com.itextpdf.text.Image;
import com.itextpdf.text.pdf.PdfWriter;
import com.itextpdf.tool.xml.XMLWorkerFontProvider;
import com.itextpdf.tool.xml.XMLWorkerHelper;
import java.io.*;
import java.nio.charset.Charset;
/**
* 关于这里的异常及文件流
* 1. 异常: 根据自身的业务,补货处理一下;
* 2. 流:一定要在 [ try - catch - finally ] finally 中关闭流,不然啥时候出现 OOM 的时候,你明白的...
* @author duzq
* @date 2020-7-26 16:44:54
*/
public class HtmlPdf {
private static final String DEST = "target/HelloWorld_CN_HTML.pdf";
private static final String HTML = "src/main/resources/template.html";
private static final String HTML_TEMP = "src/main/resources/templateTemp.html";
private static final String FONT = "src/main/resources/simhei.ttf";
public static void main(String[] args) throws IOException, DocumentException {
// 1. 读取html文件
FileInputStream fileInputStream = new FileInputStream(HTML);
StringBuilder stringBuilder = new StringBuilder();
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(fileInputStream,"utf8"));
String line = null;
while((line = bufferedReader.readLine()) != null) {
// 文字换行显示 stringBuilder.append(System.getProperty("line.separator"));
stringBuilder.append(line);
}
System.out.println(stringBuilder.toString());
// 2. 替换html中的关键字
String htmlStr = stringBuilder.toString();
htmlStr = htmlStr.replaceAll("#bankName#", "邯郸银行人民路支行");
htmlStr = htmlStr.replaceAll("#bankNo#", "111111111111111111111");
htmlStr = htmlStr.replaceAll("#periodCode#", "20200202");
htmlStr = htmlStr.replaceAll("#number1#", "1");
htmlStr = htmlStr.replaceAll("#money1#", "1.00");
htmlStr = htmlStr.replaceAll("#number2#", "2");
htmlStr = htmlStr.replaceAll("#money2#", "2.00");
htmlStr = htmlStr.replaceAll("#number3#", "3");
htmlStr = htmlStr.replaceAll("#money3#", "3.00");
htmlStr = htmlStr.replaceAll("#number4#", "4");
htmlStr = htmlStr.replaceAll("#money4#", "4.00");
htmlStr = htmlStr.replaceAll("#moneyCount1#", "100.00");
htmlStr = htmlStr.replaceAll("#moneyCount2#", "200.00");
htmlStr = htmlStr.replaceAll("#companyName#", "邯郸某个公司");
htmlStr = htmlStr.replaceAll("#auditUser#", "姜瑞珍");
htmlStr = htmlStr.replaceAll("#cashierName#", "杜志强");
htmlStr = htmlStr.replaceAll("#createDate#", "2020-07-26 16:16:50");
// 3. 可以替换成list中的数据, 后续将生成的html格式的字符串,加入到上面读取到的字符串中
String trList = "\n" +
" \n" +
" 1 " +
" 收入 " +
" 1 " +
" 资金收入 " +
" 100.00 " +
" ";
trList += "\n" +
" \n" +
" 2 " +
" 转出 " +
" 2 " +
" 资金转出 " +
" 200.00 " +
" ";
// 4. 将list中的数据替换到html中
htmlStr = htmlStr.replaceAll("#trList#", trList);
// 5. 生成临时文件 [PS: 文件名称是固定的,当碰到并发时,会出现问题,可以将html文件名称替换成 UUID]
File file = new File(HTML_TEMP);
FileOutputStream fop = new FileOutputStream(file);
if (!file.exists()) {
file.createNewFile();
}
byte[] contentInBytes = htmlStr.getBytes();
fop.write(contentInBytes);
fop.flush();
fop.close();
// 6. 开始生成pdf
Document document = new Document();
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(DEST));
document.open();
// 插入图片 , 具体怎么用,没有去琢磨...本次需求不涉及图片操作...
// 想法: 在上面的步骤,文件主题已经完成,在最后部分,通过 itext 的 api,将图片放到 pdf文件流中
// 将图片转换成 baset64 字符串的方式,试过了,不好用,才有了当前的这个想法,图片试过了,可以用。
// Image img = Image.getInstance(LOGO_PATH);
// img.setTop(100);
// img.setLeft(50);
// img.setAbsolutePosition(100,100);
// document.add(img);
// 7. 根据 html 模板转换成pdf文件
XMLWorkerFontProvider fontImp = new XMLWorkerFontProvider(XMLWorkerFontProvider.DONTLOOKFORFONTS);
fontImp.register(FONT);
XMLWorkerHelper.getInstance().parseXHtml(writer, document,
new FileInputStream(HTML_TEMP), null, Charset.forName("UTF-8"), fontImp);
document.close();
}
}
html 模板
Title
银行余额调节
开户银行:#bankName#
账号:#bankNo#
日期:#periodCode#
项目
笔数
金额
项目
笔数
金额
本单位账面余额
0
银行对账单余额
0
加:1类银行已收,本单位尚未收
#number1#
#money1#
加:3类本单位已收,银行尚未收
#number3#
#money3#
加:2类银行已付,本单位尚未付
#number2#
#money2#
加:4类本单位已付,银行尚未付
#number4#
#money4#
调节后的存款余额
#moneyCount1#
调节后的存款余额
#moneyCount2#
未达款项种类
银行凭证
摘要
金额
未达款项种类
银行凭证
摘要
金额
名称
号数
名称
号数
1
2
3
4
5
1
2
3
4
5
#trList#
单位名称:#companyName#
审核:#auditUser#
出纳:#cashierName#
编制日期:#createDate#
https://blog.csdn.net/weixin_44499394/article/details/90206391
https://www.cnblogs.com/yunfeiyang-88/p/10984740.html
感谢以上二位博主,感谢他们的分享,让我想到了这种解决方式。
Demo 代码地址:https://gitee.com/jin_0611/itextPdfTest