flink学习——DataStream的基本转换
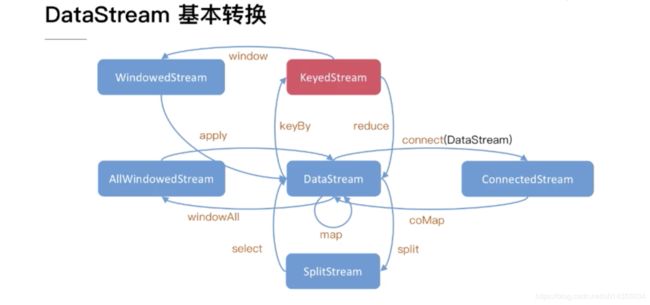
一、DataStream<->DataStream
DataStream到DataStream,常规的算子有map、filter、flatmap.这些算子和java8的stream相似,就不多描述,这里主要说union。
在官方文档中,对union的描述是:

说人话就是:两个或更多的流可以进行联合。创建出一个新的流,这个流包含所有的流的所有数据。如果一个流联合自己,那么数据会是双份的。
官方文档里没说的是,union操作时,流的类型一定是要相同的。
这个union算子,我觉得在数据同步的场景中,可以这么使用:在做数据同步的时候,多个相同结构的源,通过这个union变成一个流,然后执行process及sink。但是,这么做有什么好处?减少内存开销?我有点迷糊。
示例代码如下,从rocketMq两个topic接收canal解析的binlog数据,然后简单转成String后,合并成一个流
public class UnionDemo {
private static Logger logger = Logger.getLogger(UnionDemo.class);
public static void main(String[] args) {
try {
// 1.初始化两个数据源
StreamExecutionEnvironment env1 = StreamExecutionEnvironment.getExecutionEnvironment();
Properties consumerProps1 = new Properties();
consumerProps1.setProperty(RocketMQConfig.NAME_SERVER_ADDR, Constant.SOURCE_NAME_SERVER_ADDR);
consumerProps1.setProperty(RocketMQConfig.CONSUMER_GROUP, "flink_demo");
consumerProps1.setProperty(RocketMQConfig.CONSUMER_TOPIC, "BinLogFromCanal");
Properties consumerProps2 = new Properties();
consumerProps2.setProperty(RocketMQConfig.NAME_SERVER_ADDR, Constant.SOURCE_NAME_SERVER_ADDR);
consumerProps2.setProperty(RocketMQConfig.CONSUMER_GROUP, "flink_demo1");
consumerProps2.setProperty(RocketMQConfig.CONSUMER_TOPIC, "MsgFromOds");
// 2.初始化数据源,对数据源进行映射,过滤,根据表名分成多个侧数据流
DataStream dataStream1 = env1
.addSource(new RocketMQSource(
new SimpleKeyValueDeserializationSchema(Constant.MQ_CONSTANT_ID, Constant.MQ_CONSTANT_ADDRESS),
consumerProps1))
.name("source1").setParallelism(1)
.map(new MapFunction, String>() {
@Override
public String map(Map value) throws Exception {
StringBuffer str = new StringBuffer("source1:");
BinLogMsgEntity msgEntity = JSON.parseObject(value.get(Constant.MQ_CONSTANT_ADDRESS),
new TypeReference() {});
str.append(msgEntity.getDatabase());
return str.toString();
}
});
DataStream dataStream2 = env1
.addSource(new RocketMQSource(
new SimpleKeyValueDeserializationSchema(Constant.MQ_CONSTANT_ID, Constant.MQ_CONSTANT_ADDRESS),
consumerProps2))
.name("source2").setParallelism(1)
.map(new MapFunction, String>() {
@Override
public String map(Map value) throws Exception {
StringBuffer str = new StringBuffer("source2:");
BinLogMsgEntity msgEntity = JSON.parseObject(value.get(Constant.MQ_CONSTANT_ADDRESS),
new TypeReference() {});
str.append(msgEntity.getDatabase());
return str.toString();
}
});
dataStream2.print();
dataStream1.print();
//3.将两个数据流合并
DataStream unionStream = dataStream2.union(dataStream1).map(new MapFunction() {
@Override
public String map(String value) throws Exception {
String str = value.replaceAll("source1", "unionSource").replaceAll("source2", "unionSource");
return str;
}});
//4.打印
unionStream.print();
//执行数据流
env1.execute("geekplus_dws_etl_job1");
} catch (Exception e) {
e.printStackTrace();
logger.error("error:" + e.getMessage());
}
}
} 二、 DataStream<->KeyedStream
从图中可以看到,dataStream转keyedStream,是通过keyby算子,而KeyedStream转DataStream,则是通过reduce算子。除了这两个算子以外,还有fold算子和各种聚合算子(sum\min\max,minby\maxby。min是返回一个最小值,minby是返回最小值的对象)。
1.我们先说keyby算子。
官方文档里,是这么描述keyby的
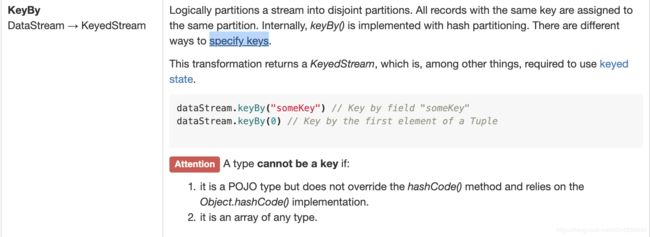
大概意思就是,在逻辑上,将流中具有不同密钥的数据划分到不同分区中,其中,相同密钥的数据在一个分区中。
我的理解就是这玩意就是一个groupby,直接将流的数据,根据某些关键值进行分组,应用场景比方说:对某个状态的数据进行分组,然后按时间窗口进行计数。
需要注意的是,keyby的key,不是是任何类型的数组,也不能是没重写hashcode方法并且依赖hashcode的POJO。
跟其他算子一样,keyby也有多种写法,可以参考官方举例
本人的demo代码如下,来自rocketmq的canal解析binlog消息,根据table名进行分组,然后设置窗口(这里简单写个窗口,后面对窗口单独拎出来讲),进行计数.
package com.qiunan.poseidon.dws.entity;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.annotation.JSONField;
import lombok.Data;
import java.io.Serializable;
import java.util.List;
@Data
public class BinLogMsgEntity implements Serializable {
/** **/
private static final long serialVersionUID = 1L;
@JSONField
private List data;
@JSONField
private String database;
@JSONField
private Long es;
@JSONField
private Long id;
@JSONField
private Boolean isDdl;
@JSONField
private String table;
@JSONField
private long ts;
@JSONField
private String type;
@JSONField
private List mysqlType;
@JSONField
private List old;
@JSONField
private JSONObject sqlType;
@JSONField
private String sql;
}
package com.qiunan.poseidon.flinkdemo;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.TypeReference;
import com.qiunan.poseidon.common.Constant;
import com.qiunan.poseidon.dws.entity.BinLogMsgEntity;
import com.qiunan.poseidon.rmqflink.RocketMQConfig;
import com.qiunan.poseidon.rmqflink.RocketMQSource;
import com.qiunan.poseidon.rmqflink.common.serialization.SimpleKeyValueDeserializationSchema;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.log4j.Logger;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
/**
* FLINK的keyby算子的demo
*
*
* @company GeekPlus
* @project jaguar
* @author qiunan
* @date Apr 30, 2019
* @since 1.0.0
*/
public class KeyByDemo {
private static Logger logger = Logger.getLogger(KeyByDemo.class);
public static void main(String[] args) {
try {
// 1.初始化数据源
StreamExecutionEnvironment env1 = StreamExecutionEnvironment.getExecutionEnvironment();
Properties consumerProps1 = new Properties();
consumerProps1.setProperty(RocketMQConfig.NAME_SERVER_ADDR, Constant.SOURCE_NAME_SERVER_ADDR);
consumerProps1.setProperty(RocketMQConfig.CONSUMER_GROUP, "flink_demo");
consumerProps1.setProperty(RocketMQConfig.CONSUMER_TOPIC, "BinLogFromCanal");
// 2.初始化数据源,对数据源进行映射,过滤,根据表名分成多个侧数据流
DataStream dataStream1 = env1
.addSource(new RocketMQSource(
new SimpleKeyValueDeserializationSchema(Constant.MQ_CONSTANT_ID, Constant.MQ_CONSTANT_ADDRESS),
consumerProps1))
.name("source1").setParallelism(1).map(new MapFunction, BinLogMsgEntity>() {
@Override
public BinLogMsgEntity map(Map value) throws Exception {
BinLogMsgEntity msgEntity = JSON.parseObject(value.get(Constant.MQ_CONSTANT_ADDRESS),
new TypeReference() {});
return msgEntity;
}
});
// 3.keyby的多种写法
// 3.1.通过自定义keySelect
KeyedStream keyedStream1 =
dataStream1.keyBy(new KeySelector() {
@Override
public String getKey(BinLogMsgEntity value) throws Exception {
// TODO Auto-generated method stub
return value.getTable();
}
});
// 3.2.通过pojo的字段名
KeyedStream keyedStream2 = dataStream1.keyBy("table");
// 3.3.通过指定tuple
KeyedStream, Tuple> keyedStream3 =
dataStream1.map(new MapFunction>() {
@Override
public Tuple3 map(BinLogMsgEntity value) throws Exception {
Tuple3 tuple3 = new Tuple3<>();
tuple3.setFields(value.getTable(), value.getDatabase(), value.getSql());
return tuple3;
}
}).keyBy(0);
// 4执行每5秒时间窗口操作,计数
SingleOutputStreamOperator> o1 =keyedStream1.timeWindow(Time.seconds(5))
.apply(new WindowFunction, String, TimeWindow>() {
@Override
public void apply(String key, TimeWindow window, Iterable input,
Collector> out) throws Exception {
Map result = new HashMap<>();
input.forEach(b -> {
int count = result.get(key) == null ? 0 : result.get(key);
count++;
result.put(key, count);
});
out.collect(result);
}
});
SingleOutputStreamOperator> o2 =keyedStream2.timeWindow(Time.seconds(5))
.apply(new WindowFunction, Tuple, TimeWindow>() {
@Override
public void apply(Tuple key, TimeWindow window, Iterable input,
Collector> out) throws Exception {
Map result = new HashMap<>();
input.forEach(b -> {
int count = result.get(key.toString()) == null ? 0 : result.get(key.toString());
count++;
result.put(key.toString(), count);
});
out.collect(result);
}
});
SingleOutputStreamOperator> o3 = keyedStream3.timeWindow(Time.seconds(5))
.apply(new WindowFunction, Map, Tuple, TimeWindow>() {
@Override
public void apply(Tuple key, TimeWindow window, Iterable> input,
Collector> out) throws Exception {
Map result = new HashMap<>();
input.forEach(b -> {
int count = result.get(key.toString()) == null ? 0 : result.get(key.toString());
count++;
result.put(key.toString(), count);
});
out.collect(result);
}
});
o1.print();
o2.print();
o3.print();
// 执行数据流
env1.execute("geekplus_dws_etl_job1");
} catch (Exception e) {
e.printStackTrace();
logger.error("error:" + e.getMessage());
}
}
}
在写这个demo的时候,有个很有意思的点,就是我的entity里isDdl用的是boolean类型,会报这个entity不能为key:This type cannot be used as key。改成Boolean就可以了。我猜这个地方跟说明的hashcode有关系。
2.reduce算子
reduce,在java8的stream里就有所接触。将一个流中多个元素合并成一个。在官方文档中,解释如下

其中提到,将新流入的数据,和最后一个reduce计算后的值进行计算,生成一个新值。
如何理解呢,就是窗口每流入一条数据,就会触发一次reduce。个人觉得reduce的适用场景比较狭窄,在做ETL的过程中,没有想到适用的场景。
DEMO代码如下
package com.qiunan.poseidon.flinkdemo;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.TypeReference;
import com.qiunan.poseidon.common.Constant;
import com.qiunan.poseidon.dws.entity.BinLogMsgEntity;
import com.qiunan.poseidon.rmqflink.RocketMQConfig;
import com.qiunan.poseidon.rmqflink.RocketMQSource;
import com.qiunan.poseidon.rmqflink.common.serialization.SimpleKeyValueDeserializationSchema;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.log4j.Logger;
import java.util.Map;
import java.util.Properties;
/**
* FLINK的reduce算子的demo
*
*
* @company GeekPlus
* @project jaguar
* @author qiunan
* @date Apr 30, 2019
* @since 1.0.0
*/
public class ReduceDemo {
private static Logger logger = Logger.getLogger(ReduceDemo.class);
public static void main(String[] args) {
try {
// 1.初始化数据源
StreamExecutionEnvironment env1 = StreamExecutionEnvironment.getExecutionEnvironment();
Properties consumerProps1 = new Properties();
consumerProps1.setProperty(RocketMQConfig.NAME_SERVER_ADDR, Constant.SOURCE_NAME_SERVER_ADDR);
consumerProps1.setProperty(RocketMQConfig.CONSUMER_GROUP, "flink_demo");
consumerProps1.setProperty(RocketMQConfig.CONSUMER_TOPIC, "BinLogFromCanal");
// 2.初始化数据源,对数据源进行映射,过滤,根据表名分成多个侧数据流
DataStream dataStream1 = env1
.addSource(new RocketMQSource(
new SimpleKeyValueDeserializationSchema(Constant.MQ_CONSTANT_ID, Constant.MQ_CONSTANT_ADDRESS),
consumerProps1))
.name("source1").setParallelism(1)
.map(new MapFunction, BinLogMsgEntity>() {
@Override
public BinLogMsgEntity map(Map value) throws Exception {
BinLogMsgEntity msgEntity = JSON.parseObject(value.get(Constant.MQ_CONSTANT_ADDRESS),
new TypeReference() {});
return msgEntity;
}
})
.filter(new FilterFunction() {
@Override
public boolean filter(BinLogMsgEntity value) throws Exception {
if(null == value.getData() ) {
return false;
}else {
return true;
}
}})
.keyBy("table").timeWindow(Time.seconds(5))
.reduce(new ReduceFunction() {
@Override
public BinLogMsgEntity reduce(BinLogMsgEntity value1, BinLogMsgEntity value2) throws Exception {
System.out.println("-------------------redeceFunction:tablie1:{"+value1.getTable()+"},tablie2:{"+value2.getTable()+"}。"
+ "size1:{"+value1.getData().size()+"},size2:{"+value2.getData().size()+"}。"
+ "type1:{"+value1.getType()+"},type2:{"+value2.getType()+"}----------------------");
return value1.getData().size()>value2.getData().size() ? value1 : value2 ;
}});
dataStream1.print();
// 执行数据流
env1.execute("geekplus_dws_etl_job1");
} catch (Exception e) {
e.printStackTrace();
logger.error("error:" + e.getMessage());
}
}
}
3.不建议使用的fold算子
我本机用来写Demo的flink版本是1.7.2。在看fold算子的时候,该算子已被注释不推荐使用。但是这里还是提一下。
官方说明如下

个人的理解是:与java8的流计算一样,fold像是一个对集合的递归。fold算子需提供一个初始值,像官方示例中的”start“。然后重写fold方法,在这个方法里,我们可以拿到上次计算完成的值current,和当前值。
Demo代码如下,
package com.qiunan.poseidon.flinkdemo;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.TypeReference;
import com.qiunan.poseidon.common.Constant;
import com.qiunan.poseidon.dws.entity.BinLogMsgEntity;
import com.qiunan.poseidon.rmqflink.RocketMQConfig;
import com.qiunan.poseidon.rmqflink.RocketMQSource;
import com.qiunan.poseidon.rmqflink.common.serialization.SimpleKeyValueDeserializationSchema;
import org.apache.flink.api.common.functions.FoldFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.log4j.Logger;
import java.util.Map;
import java.util.Properties;
/**
* FLINK的reduce算子的demo
*
*
* @company GeekPlus
* @project jaguar
* @author qiunan
* @date Apr 30, 2019
* @since 1.0.0
*/
public class FoldDemo {
private static Logger logger = Logger.getLogger(FoldDemo.class);
public static void main(String[] args) {
try {
// 1.初始化数据源
StreamExecutionEnvironment env1 = StreamExecutionEnvironment.getExecutionEnvironment();
Properties consumerProps1 = new Properties();
consumerProps1.setProperty(RocketMQConfig.NAME_SERVER_ADDR, Constant.SOURCE_NAME_SERVER_ADDR);
consumerProps1.setProperty(RocketMQConfig.CONSUMER_GROUP, "flink_demo");
consumerProps1.setProperty(RocketMQConfig.CONSUMER_TOPIC, "BinLogFromCanal");
// 2.初始化数据源,对数据源进行映射,过滤,根据表名分成多个侧数据流
DataStream dataStream1 = env1
.addSource(new RocketMQSource(
new SimpleKeyValueDeserializationSchema(Constant.MQ_CONSTANT_ID, Constant.MQ_CONSTANT_ADDRESS),
consumerProps1))
.name("source1").setParallelism(1)
.map(new MapFunction, BinLogMsgEntity>() {
@Override
public BinLogMsgEntity map(Map value) throws Exception {
BinLogMsgEntity msgEntity = JSON.parseObject(value.get(Constant.MQ_CONSTANT_ADDRESS),
new TypeReference() {});
return msgEntity;
}
})
.keyBy("table").timeWindow(Time.seconds(5))
.fold("table_name_fold", new FoldFunction() {
@Override
public String fold(String accumulator, BinLogMsgEntity value) throws Exception {
return accumulator+"_"+value.getTable();
}});
dataStream1.print();
// 执行数据流
env1.execute("geekplus_dws_etl_job1");
} catch (Exception e) {
e.printStackTrace();
logger.error("error:" + e.getMessage());
}
}
}
输出结果:

三、DataStream<->ConnectedStream
datastream与connectedStream的转换算子比较少,dataStream转成connectedStream只能用connect算子,而connectedStream可以通过map\flatmap\process\transform来转成dataStream的子类SingleOutputStreamOperator
1.connect算子
connect算子在官方的描述上只有很简短的一段,描述也是有点不太看得懂:

我个人的理解是,connect算子,只能对两个数据流进行联合,这两个数据流可以是不同数据类型的数据流,并且可以对两个数据流进行不同的map\process,数据流的状态是共享的(这句话是官方的说法,我不是很理解,搜了一下,有人举了个例子,两个数据流共享一些信息,比如计数)。相比union算子,我们可以看到两者的不同,union可以联合2个以上的数据流,而connect只能联合2个;union要求数据类型必须一致;union只能对数据流用同种处理方法,而connect可以用不同的处理方法;我在写demo的过程中发现,connect在process的时候,还可以通过context的output把数据输出到侧数据流中。
DEMO代码如下,我个人觉得,connect算子,在针对ETL数据源是同种类型的时候,使用场景不多。相比之下,可能union更适用一些。
package com.qiunan.poseidon.flinkdemo;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.TypeReference;
import com.qiunan.poseidon.common.Constant;
import com.qiunan.poseidon.dws.entity.BinLogMsgEntity;
import com.qiunan.poseidon.rmqflink.RocketMQConfig;
import com.qiunan.poseidon.rmqflink.RocketMQSource;
import com.qiunan.poseidon.rmqflink.common.serialization.SimpleKeyValueDeserializationSchema;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import org.apache.log4j.Logger;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
/**
* FLINK的connect算子的demo
*
* @company GeekPlus
* @project jaguar
* @author qiunan
* @date Apr 30, 2019
* @since 1.0.0
*/
public class ConnectedDemo {
private static Logger logger = Logger.getLogger(ConnectedDemo.class);
private static final OutputTag table = new OutputTag("table") {};
public static void main(String[] args) {
try {
// 1.初始化两个数据源
StreamExecutionEnvironment env1 = StreamExecutionEnvironment.getExecutionEnvironment();
Properties consumerProps1 = new Properties();
consumerProps1.setProperty(RocketMQConfig.NAME_SERVER_ADDR, Constant.SOURCE_NAME_SERVER_ADDR);
consumerProps1.setProperty(RocketMQConfig.CONSUMER_GROUP, "flink_demo");
consumerProps1.setProperty(RocketMQConfig.CONSUMER_TOPIC, "BinLogFromCanal");
Properties consumerProps2 = new Properties();
consumerProps2.setProperty(RocketMQConfig.NAME_SERVER_ADDR, Constant.SOURCE_NAME_SERVER_ADDR);
consumerProps2.setProperty(RocketMQConfig.CONSUMER_GROUP, "flink_demo1");
consumerProps2.setProperty(RocketMQConfig.CONSUMER_TOPIC, "MsgFromOds");
// 2.初始化数据源,对数据源进行映射,过滤,根据表名分成多个侧数据流
DataStream> dataStream1 = env1
.addSource(new RocketMQSource(
new SimpleKeyValueDeserializationSchema(Constant.MQ_CONSTANT_ID, Constant.MQ_CONSTANT_ADDRESS),
consumerProps1))
.name("source1").setParallelism(1)
.map(new MapFunction, Tuple2>() {
@Override
public Tuple2 map(Map value) throws Exception {
Tuple2 map = new Tuple2<>();
BinLogMsgEntity msgEntity = JSON.parseObject(value.get(Constant.MQ_CONSTANT_ADDRESS),
new TypeReference() {});
map.setFields(msgEntity.getTable(), msgEntity.getType());
return map;
}
});
DataStream> dataStream2 = env1
.addSource(new RocketMQSource(
new SimpleKeyValueDeserializationSchema(Constant.MQ_CONSTANT_ID, Constant.MQ_CONSTANT_ADDRESS),
consumerProps2))
.name("source2").setParallelism(1)
.map(new MapFunction, Tuple2>() {
@Override
public Tuple2 map(Map value) throws Exception {
Tuple2 map = new Tuple2<>();
BinLogMsgEntity msgEntity = JSON.parseObject(value.get(Constant.MQ_CONSTANT_ADDRESS),
new TypeReference() {});
map.setFields(msgEntity.getTable(), msgEntity.getEs());
return map;
}
});
//3.connect
SingleOutputStreamOperator connectedStream = dataStream1.connect(dataStream2)
.process(new CoProcessFunction, Tuple2, String>() {
//connect的process可以分别对两个流进行不同的处理,并且在处理的过程中,可以通过context写入侧数据流中。
@Override
public void processElement1(Tuple2 input1,
CoProcessFunction, Tuple2, String>.Context context1,
Collector output1) throws Exception {
// System.out.println("------processElement1:table:"+input1.f0+";type:"+input1.f1+"。----------------");
// System.out.println("------processElement1:context1:"+context1.toString());
//可以通过CoProcessFunction往侧数据流里写数据
// System.out.println("------processElement1:currentProcessingTime:"+context1.timerService().currentProcessingTime()+";currentWatermark:"+context1.timerService().currentWatermark()+"。----------------");
// context1.output(table, input1.f0+input1.f1);
output1.collect("------processElement1:table:"+input1.f0+";type:"+input1.f1+"。----------------");
}
@Override
public void processElement2(Tuple2 input2,
CoProcessFunction, Tuple2, String>.Context context2,
Collector output2) throws Exception {
// System.out.println("------processElement2:table:"+input2.f0+";es:"+input2.f1+"。----------------");
// System.out.println("------processElement2:context2:"+context2.toString());
// context2.output(table, input2.f0+input2.f1);
output2.collect("------processElement2:table:"+input2.f0+";es:"+input2.f1+"。----------------");
}});
// DataStream outOrderStream = connectedStream.getSideOutput(table);
// outOrderStream.print();
// ConnectedStreams, Tuple2> keyedConnectedStream = dataStream1.connect(dataStream2).keyBy(0,0);
//4.打印
connectedStream.print();
//执行数据流
env1.execute("geekplus_dws_etl_job1");
} catch (Exception e) {
e.printStackTrace();
logger.error("error:" + e.getMessage());
}
}
}
2.map\flatmap算子
和dataStream的map和flatmap算子相似,对connectedStream来说,map或flatmap主要是多了一个操作,即对两个流执行各自的map\flatmap。返回值是SingleOutputStreamOperator。
官网的示例中,flatmap没有体现出其独特的性质,我记得在java8的stream中,flatmap一般用于展开嵌套的list。对此,我写了下面这个demo:
package com.qiunan.poseidon.flinkdemo;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.TypeReference;
import com.qiunan.poseidon.common.Constant;
import com.qiunan.poseidon.dws.entity.BinLogMsgEntity;
import com.qiunan.poseidon.rmqflink.RocketMQConfig;
import com.qiunan.poseidon.rmqflink.RocketMQSource;
import com.qiunan.poseidon.rmqflink.common.serialization.SimpleKeyValueDeserializationSchema;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoFlatMapFunction;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import org.apache.log4j.Logger;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
/**
* FLINK的connect算子的demo
*
* @company GeekPlus
* @project jaguar
* @author qiunan
* @date Apr 30, 2019
* @since 1.0.0
*/
public class CoMapDemo {
private static Logger logger = Logger.getLogger(CoMapDemo.class);
private static final OutputTag table = new OutputTag("table") {};
public static void main(String[] args) {
try {
// 1.初始化两个数据源
StreamExecutionEnvironment env1 = StreamExecutionEnvironment.getExecutionEnvironment();
Properties consumerProps1 = new Properties();
consumerProps1.setProperty(RocketMQConfig.NAME_SERVER_ADDR, Constant.SOURCE_NAME_SERVER_ADDR);
consumerProps1.setProperty(RocketMQConfig.CONSUMER_GROUP, "flink_demo");
consumerProps1.setProperty(RocketMQConfig.CONSUMER_TOPIC, "BinLogFromCanal");
Properties consumerProps2 = new Properties();
consumerProps2.setProperty(RocketMQConfig.NAME_SERVER_ADDR, Constant.SOURCE_NAME_SERVER_ADDR);
consumerProps2.setProperty(RocketMQConfig.CONSUMER_GROUP, "flink_demo1");
consumerProps2.setProperty(RocketMQConfig.CONSUMER_TOPIC, "MsgFromOds");
// 2.初始化数据源,对数据源进行映射,过滤,根据表名分成多个侧数据流
DataStream>> dataStream1 = env1
.addSource(new RocketMQSource(
new SimpleKeyValueDeserializationSchema(Constant.MQ_CONSTANT_ID, Constant.MQ_CONSTANT_ADDRESS),
consumerProps1))
.name("source1").setParallelism(1)
.map(new MapFunction, Tuple2>>() {
@Override
public Tuple2> map(Map value) throws Exception {
Tuple2> map = new Tuple2<>();
BinLogMsgEntity msgEntity = JSON.parseObject(value.get(Constant.MQ_CONSTANT_ADDRESS),
new TypeReference() {});
map.setFields(msgEntity.getTable(), msgEntity.getData());
return map;
}
}).filter( new FilterFunction>>() {
@Override
public boolean filter(Tuple2> value) throws Exception {
if(null == value.f1) {
return false;
}else {
return true;
}
}});
DataStream>> dataStream2 = env1
.addSource(new RocketMQSource(
new SimpleKeyValueDeserializationSchema(Constant.MQ_CONSTANT_ID, Constant.MQ_CONSTANT_ADDRESS),
consumerProps2))
.name("source2").setParallelism(1)
.map(new MapFunction, Tuple2>>() {
@Override
public Tuple2> map(Map value) throws Exception {
Tuple2> map = new Tuple2<>();
BinLogMsgEntity msgEntity = JSON.parseObject(value.get(Constant.MQ_CONSTANT_ADDRESS),
new TypeReference() {});
map.setFields(msgEntity.getTable(), msgEntity.getMysqlType());
return map;
}
}).filter( new FilterFunction>>() {
@Override
public boolean filter(Tuple2> value) throws Exception {
if(null == value.f1) {
return false;
}else {
return true;
}
}});
//3.connect
SingleOutputStreamOperator> mapStream = dataStream1.connect(dataStream2)
.map(new CoMapFunction>, Tuple2>, List>() {
@Override
public List map1(Tuple2> value) throws Exception {
return value.f1;
}
@Override
public List map2(Tuple2> value) throws Exception {
return value.f1;
}});
SingleOutputStreamOperator flatMapStream = dataStream1.connect(dataStream2)
.flatMap(new CoFlatMapFunction>, Tuple2>, JSONObject>() {
@Override
public void flatMap1(Tuple2> value, Collector out)
throws Exception {
value.f1.forEach(j ->{out.collect(j);});
}
@Override
public void flatMap2(Tuple2> value, Collector out)
throws Exception {
value.f1.forEach(j ->{out.collect(j);});
}});
//4.打印
mapStream.print();
flatMapStream.print();
//执行数据流
env1.execute("geekplus_dws_etl_job1");
} catch (Exception e) {
e.printStackTrace();
logger.error("error:" + e.getMessage());
}
}
}
四、SplitStream<->DataStream
SplitStream,顾名思义,就是分割数据流。使用场景比较宽泛,比如我们可以一个binlog数据源,根据table名分割成多个数据源,然后各个数据源进行单独处理。不过在flink的1.7.2版本后,更推荐使用侧数据流。这个会在这一节后面提一下。
1.split算子与select算子
split算子用于将一个数据流拆分成两个或多个数据流,官方解释如下

从官方示例中,我们可以看到,输出为SplitStream。但是,我们如何拿到切出来的那个数据流,这就需要用到select算子,select算子的官方说明如下

一般来说,split和select是一起使用。
我简单写了个demo
package com.qiunan.poseidon.flinkdemo;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.TypeReference;
import com.qiunan.poseidon.common.Constant;
import com.qiunan.poseidon.dws.entity.BinLogMsgEntity;
import com.qiunan.poseidon.rmqflink.RocketMQConfig;
import com.qiunan.poseidon.rmqflink.RocketMQSource;
import com.qiunan.poseidon.rmqflink.common.serialization.SimpleKeyValueDeserializationSchema;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.log4j.Logger;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Properties;
public class SplitDemo {
private static Logger logger = Logger.getLogger(SplitDemo.class);
public static void main(String[] args) {
try {
// 1.加载数据源参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties consumerProps = new Properties();
consumerProps.setProperty(RocketMQConfig.NAME_SERVER_ADDR, Constant.SOURCE_NAME_SERVER_ADDR);
consumerProps.setProperty(RocketMQConfig.CONSUMER_GROUP, "flink_demo");
consumerProps.setProperty(RocketMQConfig.CONSUMER_TOPIC, "BinLogFromCanal");
// 2.初始化数据源,对数据源进行映射,过滤,根据表名分割成多个数据流
SplitStream splitStream = env
.addSource(new RocketMQSource(
new SimpleKeyValueDeserializationSchema(Constant.MQ_CONSTANT_ID, Constant.MQ_CONSTANT_ADDRESS),
consumerProps))
.name(Constant.FLINK_SOURCE_NAME).setParallelism(1)
.map(new MapFunction, BinLogMsgEntity>() {
@Override
public BinLogMsgEntity map(Map value) throws Exception {
BinLogMsgEntity msgEntity = JSON.parseObject(value.get(Constant.MQ_CONSTANT_ADDRESS),
new TypeReference() {});
return msgEntity;
}
}).split(new OutputSelector() {
@Override
public Iterable select(BinLogMsgEntity value) {
List output = new ArrayList();
if(value.getTable().equals("out_order")) {
output.add("out_order");
}else if(value.getTable().equals("out_order_details")) {
output.add("out_order_details");
}else {
output.add("other");
}
return output;
}});
DataStream outOrderStream = splitStream.select("out_order").map(new MapFunction() {
@Override
public String map(BinLogMsgEntity value) throws Exception {
return "out_order:"+value.getEs();
}});
DataStream outOrderDetailStream = splitStream.select("out_order_details").map(new MapFunction() {
@Override
public String map(BinLogMsgEntity value) throws Exception {
return "out_order_details:"+value.getEs();
}});
DataStream otherStream = splitStream.select("other").map(new MapFunction() {
@Override
public String map(BinLogMsgEntity value) throws Exception {
return "other:"+value.getTable()+"——"+value.getEs();
}});
// 4.对分割出来的数据流进行打印
outOrderStream.print();
outOrderDetailStream.print();
otherStream.print();
env.execute("geekplus_dws_etl_job");
} catch (Exception e) {
e.printStackTrace();
logger.error("error:" + e.getMessage());
}
}
}
2.侧输出流
在flink1.7.2版本后,splitStream不被推荐使用,使之替代的是侧输出流。那么如何使用侧输出流呢?
三个步骤:
-
定义OutputTag;
-
在process中,使用Context的output方法往侧输出流中丢数据
-
使用getSideOutput方法获取侧输出流
DEMO代码如下
package com.qiunan.poseidon.flinkdemo;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.TypeReference;
import com.qiunan.poseidon.common.Constant;
import com.qiunan.poseidon.common.Utils;
import com.qiunan.poseidon.dws.entity.BinLogMsgEntity;
import com.qiunan.poseidon.rmqflink.RocketMQConfig;
import com.qiunan.poseidon.rmqflink.RocketMQSource;
import com.qiunan.poseidon.rmqflink.common.serialization.SimpleKeyValueDeserializationSchema;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import org.apache.log4j.Logger;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.stream.Collectors;
public class JoinDemo {
private static Logger logger = Logger.getLogger(JoinDemo.class);
private static final OutputTag outOrder = new OutputTag("out_order") {};
private static final OutputTag outOrderDetail =
new OutputTag("out_order_detail") {};
public static void main(String[] args) {
try {
// 1.加载数据源参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties consumerProps = new Properties();
consumerProps.setProperty(RocketMQConfig.NAME_SERVER_ADDR, Constant.SOURCE_NAME_SERVER_ADDR);
consumerProps.setProperty(RocketMQConfig.CONSUMER_GROUP, "flink_demo");
consumerProps.setProperty(RocketMQConfig.CONSUMER_TOPIC, Constant.SOURCE_CONSUMER_TOPIC);
// 2.初始化数据源,对数据源进行映射,过滤,根据表名分成多个侧数据流
SingleOutputStreamOperator keyedStream = env
.addSource(new RocketMQSource(
new SimpleKeyValueDeserializationSchema(Constant.MQ_CONSTANT_ID, Constant.MQ_CONSTANT_ADDRESS),
consumerProps))
.name(Constant.FLINK_SOURCE_NAME).setParallelism(1)
.map(new MapFunction, BinLogMsgEntity>() {
@Override
public BinLogMsgEntity map(Map value) throws Exception {
BinLogMsgEntity msgEntity = JSON.parseObject(value.get(Constant.MQ_CONSTANT_ADDRESS),
new TypeReference() {});
return msgEntity;
}
}).process(new ProcessFunction() {
@Override
public void processElement(BinLogMsgEntity value,
ProcessFunction.Context ctx, Collector out)
throws Exception {
// 数据发送到常规输出中
out.collect(value);
// 根据表名,发送到侧输出中
if (value.getTable().equals("out_order")
&& value.getType().equals(Constant.MQ_MSG_TYPE_INSERT)) {
ctx.output(outOrder, value);
} else if (value.getTable().equals("out_order_details")
&& value.getType().equals(Constant.MQ_MSG_TYPE_INSERT)) {
ctx.output(outOrderDetail, value);
}
}
});
DataStream outOrderStream = keyedStream.getSideOutput(outOrder);
DataStream outOrderDetailStream = keyedStream.getSideOutput(outOrderDetail);
// 4.对侧数据流进行打印
// keyedStream.getSideOutput(outOrder).join(keyedStream.getSideOutput(outOrderDetail))
// 4.对侧数据流进行打印
// keyedStream.getSideOutput(outOrderDetail).print();
outOrderStream.join(outOrderDetailStream).where(new KeySelector() {
@Override
public String getKey(BinLogMsgEntity value) throws Exception {
// 获取out_order_code
String outOrderCode = value.getData().get(0).getString("out_order_code");
System.out.println("order:"+outOrderCode );
return outOrderCode;
}
}).equalTo(new KeySelector() {
@Override
public String getKey(BinLogMsgEntity value) throws Exception {
// 获取out_order_code
String outOrderCode = value.getData().get(0).getString("out_order_code");
System.out.println("detail:"+outOrderCode );
return outOrderCode;
}
}).window(ProcessingTimeSessionWindows.withGap(Time.seconds(60)))
.apply(new JoinFunction>() {
@Override
public List join(BinLogMsgEntity first, BinLogMsgEntity second) throws Exception {
List result = new ArrayList<>();
for(JSONObject orderJO : first.getData()){
String outOrderCode = orderJO.getString("out_order_code");
Integer orderType = orderJO.getInteger("order_type");
Long outOrderId = orderJO.getLong("id");
long inputTS = orderJO.getLong("input_date");
int hour = Utils.getHourFromTs(inputTS);
List detailList = second.getData().stream().filter(d ->d.getString("out_order_code").equals(outOrderCode)).collect(Collectors.toList());
int detailNum = detailList.size();
int skuPieceNum = detailList.stream().mapToInt(oj -> oj.getInteger("amount")).sum();
String sql = new StringBuffer("insert into dws_order_input_h (out_order_id,hour, order_type, detail_num,sku_piece_num) values (")
.append(outOrderId.toString()).append(",")
.append(hour).append(",")
.append(orderType).append(",")
.append(detailNum).append(",")
.append(skuPieceNum).append(")").toString();
result.add(sql);
}
return result;
}})
.process(new ProcessFunction, String>() {
@Override
public void processElement(List in, ProcessFunction, String>.Context arg1,
Collector out) throws Exception {
in.forEach(s ->{
out.collect(s);
});
}
})
.print();
// 5.对主数据流进行打印
// keyedStream.print();
env.execute("geekplus_dws_etl_job");
} catch (Exception e) {
e.printStackTrace();
logger.error("error:" + e.getMessage());
}
}
}